一、概述
Logstash 是一个开源的数据收集和日志处理工具,它是 Elastic Stack(ELK Stack)的一部分,用于从各种数据源中采集、转换和传输数据,以帮助分析和可视化大规模数据。Logstash 通常与 Elasticsearch 和 Kibana 一起使用,以实现实时日志分析和监控。
以下是 Logstash 的主要功能和特点:
-
数据采集:
Logstash可以从多种数据源中采集数据,包括日志文件、数据文件、消息队列、数据库、网络流量等。它支持多种输入插件,以适应不同数据源的需要。 -
数据转换:
Logstash具有强大的数据转换功能,可以对采集的数据进行过滤、解析、转换和丰富操作。它使用过滤插件来对数据执行各种操作,包括正则表达式解析、字段拆分、数据脱敏、时间戳生成等。 -
多通道数据处理:
Logstash允许将数据流式传输到不同的通道,以满足不同的需求。通道可以是Elasticsearch、Kafka、RabbitMQ等,或者您可以定义自定义输出插件。 -
数据过滤和插件:
Logstash有丰富的插件生态系统,包括输入插件、过滤插件和输出插件。这些插件可以根据特定需求来配置和扩展,以适应各种数据处理任务。 -
实时数据处理:
Logstash具有实时数据处理能力,可以将数据从源头到目的地以实时或近实时的方式传递。这使得它适用于日志监控、安全分析、性能监控等实时应用。 -
可伸缩性:
Logstash可以与多个Logstash实例一起部署,以实现数据采集和处理的横向扩展。这有助于应对大规模数据需求。 -
易于配置:
Logstash使用简单的配置文件(通常是YAML格式)来定义数据流的处理过程。配置文件非常直观,易于理解和维护。 -
社区和支持:
Logstash是一个广泛采用的开源项目,拥有活跃的社区支持和大量的文档资源。
Logstash 是 Elastic Stack 中的一个重要组件,与 Elasticsearch 和 Kibana 配合使用,可以构建强大的实时日志和数据分析解决方案。它为组织提供了强大的数据采集和处理工具,用于监控、分析和可视化大规模数据。
官方文档:
二、Logstash 架构
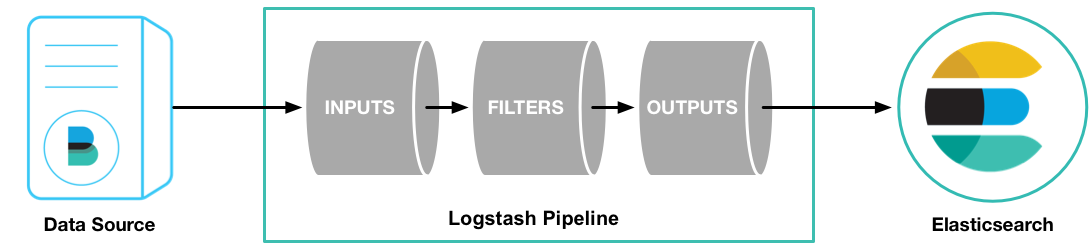
Logstash 包含3个主要部分: 输入(inputs),过滤器(filters)和输出(outputs)
Logstash的事件(logstash将数据流中等每一条数据称之为一个event)处理流水线有三个主要角色完成:inputs –> filters –> outputs。
inpust:必须,负责产生事件(Inputs generate events),常用:File、syslog、redis、kakfa、beats(如:Filebeats);官方文档:https://www.elastic.co/guide/en/logstash/7.17/input-plugins.htmlfilters:可选,负责数据处理与转换(filters modify them),常用:grok、mutate、drop、clone、geoip;官网文档:https://www.elastic.co/guide/en/logstash/7.17/filter-plugins.htmloutpus:必须,负责数据输出(outputs ship them elsewhere),常用:elasticsearch、file、graphite、kakfa、statsd;官方文档:https://www.elastic.co/guide/en/logstash/7.17/output-plugins.html
二、ElasticSearch 部署
这里可以选择以下部署方式:
- 通过docker-compose部署:通过 docker-compose 快速部署 Elasticsearch 和 Kibana 保姆级教程
- on k8s 部署:ElasticSearch+Kibana on K8s 讲解与实战操作(版本7.17.3)
这里我选择 docker-compose 部署方式。
1)部署 docker
# 安装yum-config-manager配置工具
yum -y install yum-utils
# 建议使用阿里云yum源:(推荐)
#yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce版本
yum install -y docker-ce
# 启动并开机启动
systemctl enable --now docker
docker --version
2)部署 docker-compose
curl -SL https://github.com/docker/compose/releases/download/v2.16.0/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
docker-compose --version
3)创建网络
# 创建
docker network create bigdata
# 查看
docker network ls
4)修改 Linux 句柄数和最大线程数
#查看当前最大句柄数
sysctl -a | grep vm.max_map_count
#修改句柄数
vi /etc/sysctl.conf
vm.max_map_count=262144
#临时生效,修改后需要重启才能生效,不想重启可以设置临时生效
sysctl -w vm.max_map_count=262144
#修改后需要重新登录生效
vi /etc/security/limits.conf
# 添加以下内容
* soft nofile 65535
* hard nofile 65535
* soft nproc 4096
* hard nproc 4096
# 重启服务,-h 立刻重启,默认间隔一段时间才会开始重启
reboot -h now
5)下载部署包开始部署
# 这里选择 docker-compose 部署方式
git clone https://gitee.com/hadoop-bigdata/docker-compose-es-kibana.git
cd docker-compose-es-kibana
chmod -R 777 es kibana
docker-compose -f docker-compose.yaml up -d
docker-compose ps
三、Logstash 部署与配置讲解
1)下载Logstash安装包
访问官方网站 https://www.elastic.co/downloads/logstash ,下载相应版本的zip文件。
wget https://artifacts.elastic.co/downloads/logstash/logstash-8.11.1-linux-x86_64.tar.gz
2)解压安装包文件
tar -xf logstash-8.11.1-linux-x86_64.tar.gz
3)不同场景测试
1)测试1:采用标准的输入和输出
cd logstash-8.11.1
# 测试,采用标准的输入和输出,#codec=>rubydebug,解析转换类型:ruby
# codec各类型讲解:https://www.elastic.co/guide/en/logstash/7.9/codec-plugins.html
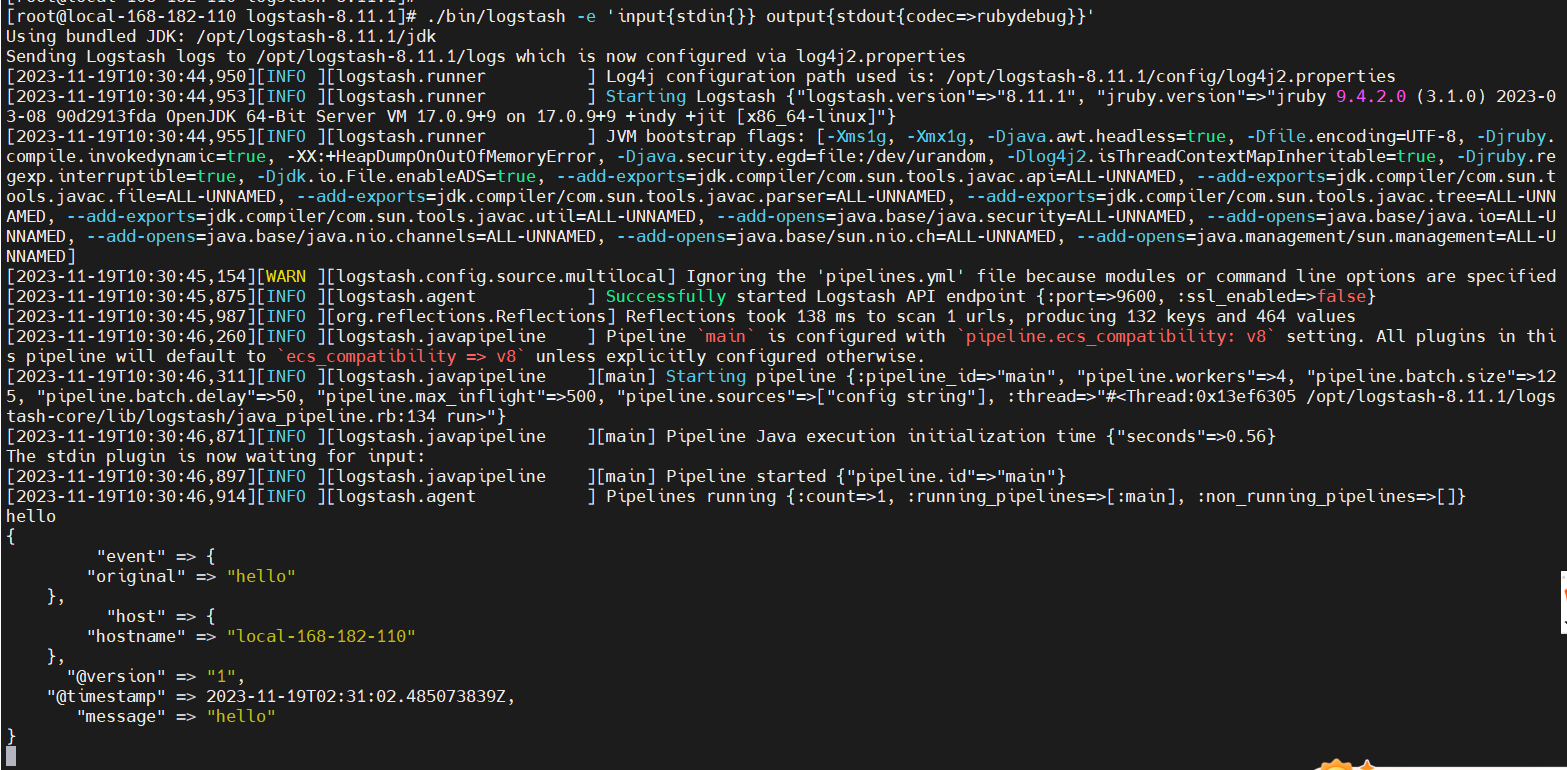
./bin/logstash -e 'input{stdin{}} output{stdout{codec=>rubydebug}}'
# 输入:
hello
# 输出:
{
"event" => {
"original" => "hello"
},
"host" => {
"hostname" => "local-168-182-110"
},
"@version" => "1",
"@timestamp" => 2023-11-19T02:31:02.485073839Z,
"message" => "hello"
}
2)测试2:使用配置文件 +标准输入输出
配置文件:config/logstash-1.conf
input {
stdin { }
}
output {
stdout { codec => rubydebug }
}
启动服务
./bin/logstash -f ./config/logstash-1.conf
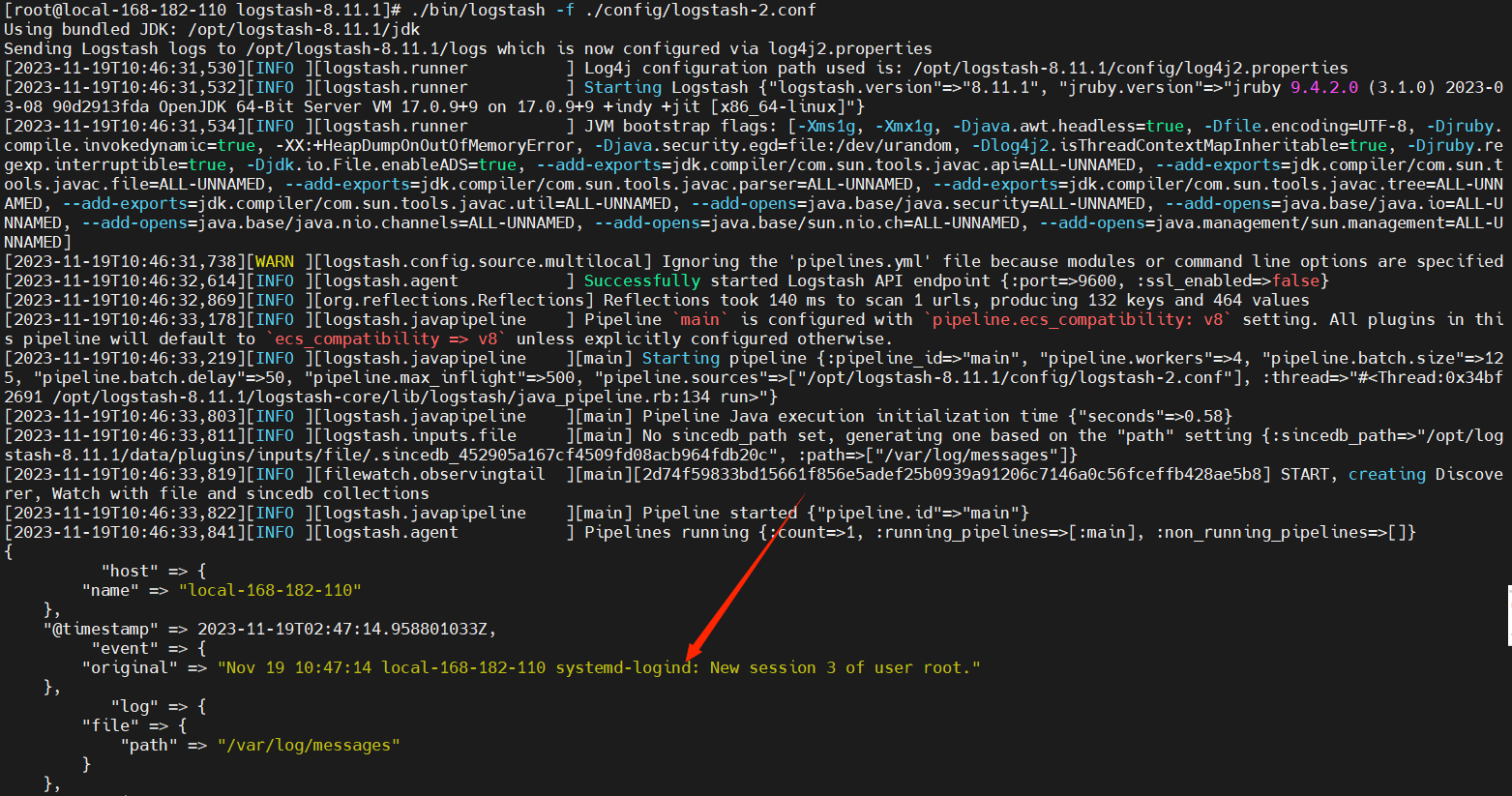
3)测试3:配置文件+file输入 +标准的屏幕输出
配置文件:./config/logstash-2.conf
input {
file {
path => "/var/log/messages"
}
}
output {
stdout {
codec=>rubydebug
}
}
启动服务
./bin/logstash -f ./config/logstash-2.conf
4)测试4:配置文件+文件输入+kafka输出
kafka 部署,可以参考我以下几篇文章:
配置文件:./config/logstash-3.conf
input {
file {
path => "/var/log/messages"
}
}
output {
kafka {
bootstrap_servers => "192.168.182.110:9092"
topic_id => "messages"
}
}
启动服务
./bin/logstash -f ./config/logstash-3.conf
消费 kafka 数据
docker exec -it kafka-node1 bash
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic messages --from-beginning

5)测试5:配置文件+filebeat端口输入+标准输出
filebeat 部署,可以参考我以下几篇文章:
服务器产生日志(filebeat)---》logstash服务器
配置文件:./config/logstash-4.conf
input {
beats {
port => 5044
}
}
output {
stdout {
codec => rubydebug
}
}
启动服务
./bin/logstash -f ./config/logstash-4.conf
启动后会在本机启动一个5044端口,不要和系统已启动的端口冲突即可,配合测试我们在 filebeat 服务器上修改配置文件。
filebeat 配置文件内容:filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
# ------------------------------ Logstash Output -------------------------------
output.logstash:
hosts: ["192.168.182.110:5044"]
启动 filebeat
./filebeat -e -c filebeat.yml
6)测试6:配置文件+filebeat端口输入+输出到kafka
服务器产生日志(filebeat)---> logstash服务器---->kafka服务器
配置文件:./config/logstash-5.conf
input {
beats {
port => 5044
}
}
output {
kafka {
bootstrap_servers => "192.168.182.110:9092"
topic_id => "messages"
}
}
启动服务
./bin/logstash -f ./config/logstash-5.conf
7)测试7:filebeat数据采集+kafka读取当输入+logstash处理+输出到 ES
服务器产生日志(filebeat)---> kafka服务器__抽取数据___> logstash服务器---->ES
logstash的配置:./config/logstash-6.conf
input {
kafka {
bootstrap_servers => "10.82.192.110:9092"
topics => ["messages"]
}
}
output {
elasticsearch {
hosts => ["10.82.192.110:9200"]
index => "messageslog-%{+YYYY-MM-dd}"
}
}
filebeat.yml output.kafka 配置:
# ------------------------------ KAFKA Output -------------------------------
output.kafka:
eanbled: true
hosts: ["10.82.192.110:9092"]
version: "2.0.1"
topic: '%{[fields][log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
使用 systemctl 启动 filebeat
# vi /usr/lib/systemd/system/filebeat.service
[Unit]
Description=filebeat server daemon
Documentation=/opt/filebeat-7.6.2-linux-x86_64/filebeat -help
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Environment="BEAT_CONFIG_OPTS=-c /opt/filebeat-7.6.2-linux-x86_64/filebeat.yml"
ExecStart=/opt/filebeat-7.6.2-linux-x86_64/filebeat $BEAT_CONFIG_OPTS
Restart=always
[Install]
WantedBy=multi-user.target
使用 systemctl 启动 logstash
# vi /usr/lib/systemd/system/logstash.service
[Unit]
Description=logstash
[Service]
User=root
ExecStart=/opt/logstash-8.11.1/bin/logstash -f /opt/logstash-8.11.1/config/logstash-6.conf
Restart=always
[Install]
WantedBy=multi-user.target
启动服务
systemctl start logstash
systemctl status logstash
四、Logstash filter常用插件
负责数据处理与转换(filters modify them),常用:grok、mutate、drop、clone、geoip;官网文档:https://www.elastic.co/guide/en/logstash/7.17/filter-plugins.html
1)使用grok内置的正则案例
grok 插件:Grok是将非结构化日志数据解析为结构化和可查询内容的好方法,底层原理是基于正则匹配任意文本格式
此工具非常适合syslog日志、apache和其他Web服务器日志、mysql日志,以及一般来说,任何通常为人类而不是计算机消费编写的日志格式。
grok内置了120种匹配模式,也可以自定义匹配模式:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
filebeat配置:filebeat.yml
##
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
output.logstash:
#指定logstash监听的IP和端口
hosts: ["192.168.182.110:5044"]
logstash 配置:stdin-grok-stout.conf
cat >> stdin-grok-stout.conf << EOF
input {
#监听的类型
beats {
#监听的本地端口
port => 5044
}
}
filter{
grok{
#match => { "message" => "%{COMBINEDAPACHELOG}" }
#上面的"COMBINEDAPACHELOG"变量官方github上已经废弃,建议使用下面的匹配模式
#参考地址:https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/legacy/httpd
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
}
}
output {
stdout {}
elasticsearch {
#定义es集群的主机地址
hosts => ["192.168.182.110:9200"]
#定义索引名称
index => "hqt-application-pro-%{+YYYY.MM.dd}"
}
}
EOF
2)使用grok自定义的正则案例
参考官网地址:https://www.elastic.co/guide/en/logstash/7.17/plugins-filters-grok.html
配置如下:
cat >> stdin-grok_custom_patterns-stdout.conf << EOF
input {
stdin {}
}
filter {
grok {
#指定模式匹配的目录,可以使用绝对路径
#在./patterns目录下随便创建一文件,并写入以下匹配模式
# ORDER_ID [\u4e00-\u9fa5]{10,11}:[0-9A-F]{10,11}
patterns_dir => ["./patterns"]
#匹配模式
#测试数据为:app_name:gotone-payment-api,client_ip:,context:,docker_name:,env:dev,exception:,extend1:,level:INFO,line:-1,log_message:com.gotone.paycenter.controller.task.PayCenterJobHandler.queryPayOrderTask-request:[\\],log_time:2022-11-23 00:00:00.045,log_type:applicationlog,log_version:1.0.0,本次成交的订单编号为:BEF25A72965,parent_span_id:,product_line:,server_ip:,server_name:gotone-payment-api-c86658cb7-tc8k5,snooper:,span:0,span_id:,stack_message:,threadId:104,trace_id:,user_log_type:
match => { "message" => "%{ORDER_ID:test_order_id}" }
}
}
output {
stdout {}
}
EOF
3)filter插件通用字段案例(添加/删除字段、tag)
原有字段(nginx的json解析日志)
配置如下:
cat >> stdin-remove_add_field-stout.conf << EOF
input {
beats {
port => 5044
}
}
filter {
mutate {
#移除指定的字段,使用逗号分隔
remove_field => [ "tags","agent","input","log","ecs","version","@version","ident","referrer","auth" ]
#添加指定的字段,使用逗号分隔
#"%{clientip}"使用%可以将已有字段的值当作变量使用
add_field => {
"app_name" => "nginx"
"test_clientip" => "clientip---->%{clientip}"
}
#添加tag
add_tag => [ "linux","web","nginx","test" ]
#移除tag
remove_tag => [ "linux","test" ]
}
}
output {
stdout {}
}
EOF
4)date 插件修改写入ES的时间案例
测试日志:如下是我们要收集的一条json格式的日志
{"app_name":"gotone-payment-api","client_ip":"","context":"","docker_name":"","env":"dev","exception":"","extend1":"","level":"INFO","line":68,"log_message":"现代金控支付查询->调用入参[{}]","log_time":"2022-11-23 00:00:00.051","log_type":"applicationlog","log_version":"1.0.0","method_name":"com.gotone.paycenter.dao.third.impl.modernpay.ModernPayApiAbstract.getModernPayOrderInfo","parent_span_id":"","product_line":"","server_ip":"","server_name":"gotone-payment-api-c86658cb7-tc8k5","snooper":"","span":0,"span_id":"","stack_message":"","threadId":104,"trace_id":"gotone-payment-apib4a65777-ce6b-4bcc-8aef-71a7cfffaf2c","user_log_type":""}
配置如下:
cat >> stdin-date-es.conf << EOF
input {
file {
#指定收集的路径
path => "/var/log/messages"
}
}
filter {
json {
#JSON解析器 可以将json形式的数据转换为logstash实际的数据结构(根据key:value拆分成字段形式)
source => "message"
}
date {
#匹配时间字段并解析
match => [ "log_time", "yyyy-MM-dd HH:mm:ss.SSS" ]
#将匹配到的时间字段解析后存储到目标字段,默认字段为"@timestamp"
target => "@timestamp"
timezone => "Asia/Shanghai"
}
}
output {
stdout {}
elasticsearch {
#定义es集群的主机地址
hosts => ["192.168.182.110:9200"]
#定义索引名称
index => "hqt-application-pro-%{+YYYY.MM.dd}"
}
}
EOF
5)geoip分析原IP地址位置案例
测试数据为:nginx的json格式日志
{"@timestamp":"2022-12-18T03:27:10+08:00","host":"10.0.24.2","clientip":"114.251.122.178","SendBytes":4833,"responsetime":0.000,"upstreamtime":"-","upstreamhost":"-","http_host":"43.143.242.47","uri":"/index.html","domain":"43.143.242.47","xff":"-","referer":"-","tcp_xff":"-","http_user_agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36","status":"200"}
配置如下:
cat >> beats-geoip-stdout.conf << EOF
input {
file {
#指定收集的路径
path => "/var/log/test.log"
}
}
filter {
json {
#JSON解析器 可以将json形式的数据转换为logstash实际的数据结构(根据key:value拆分成字段形式)
source => "message"
}
geoip {
#指定基于哪个字段分析IP地址
source => "client_ip"
#指定IP地址分析模块所使用的数据库,默认为GeoLite2-City.mmdb(这里必须再次指定以下,否则不会显示城市)
database => "/hqtbj/hqtwww/logstash_workspace/data/plugins/filters/geoip/CC/GeoLite2-City.mmdb"
#如果期望查看指定的字段,则可以在这里配置,若不配置,表示显示所有的查询字段
#fields => ["city_name","country_name","ip"]
#指定geoip的输出字段,当有多个IP地址需要分析时(例如源IP和目的IP),则该字段非常有效
#target => "test-geoip-nginx"
}
}
output {
stdout {}
}
EOF
GeoLite2-City.mmdb 下载:https://dev.maxmind.com/geoip/geolite2-free-geolocation-data
7)mutate组件常用案例
mutate 测试数据 python 脚本:
cat >> generate_log.py << EOF
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# @author : oldboyedu-linux80
import datetime
import random
import logging
import time
import sys
LOG_FORMAT = "%(levelname)s %(asctime)s [com.oldboyedu.%(module)s] - %(message)s "
DATE_FORMAT = "%Y-%m-%d %H:%M:%S"
# 配置root的logging.Logger实例的基本配置
logging.basicConfig(level=logging.INFO, format=LOG_FORMAT, datefmt=DATE_FORMAT, filename=sys.argv[1], filemode='a',)
actions = ["浏览⻚⾯", "评论商品", "加⼊收藏", "加⼊购物⻋", "提交订单", "使⽤优惠券", "领取优惠券", "搜索", "查看订单", "付款", "清空购物⻋"]
while True:
time.sleep(random.randint(1, 5))
user_id = random.randint(1, 10000)
# 对⽣成的浮点数保留2位有效数字.
price = round(random.uniform(15000, 30000),2)
action = random.choice(actions)
svip = random.choice([0,1])
logging.info("DAU|{0}|{1}|{2}|{3}".format(user_id, action,svip,price))
EOF
# python generate_log.py /tmp/app.log
8)logstash的多if分支案例
配置如下:
cat >> homework-to-es.conf << EOF
input {
beats {
type => "test-nginx-applogs"
port => 5044
}
file {
type => "test-product-applogs"
path => "/tmp/app.logs"
}
beats {
type => "test-dw-applogs"
port => 8888
}
file {
type => "test-payment-applogs"
path => "/tmp/payment.log"
}
}
filter {
if [type] == "test-nginx-applogs"{
mutate {
remove_field => [ "tags","agent","input","log","ecs","version","@version","ident","referrer","auth","xff","referer","upstreamtime","upstreamhost","tcp_xff"]
}
geoip {
source => "clientip"
database => "/hqtbj/hqtwww/logstash_workspace/data/plugins/filters/geoip/CC/GeoLite2-City.mmdb"
}
useragent {
source => "http_user_agent"
}
}
if [type] == "test-product-applogs" {
mutate {
split => { "message" => "|" }
}
mutate {
add_field => {
"user_id" => "%{[message][1]}"
"action" => "%{[message][2]}"
"svip" => "%{[message][3]}"
"price" => "%{[message][4]}"
}
}
mutate {
convert => {
"user_id" => "integer"
"svip" => "boolean"
"price" => "float"
}
}
}
if [type] in [ "test-dw-applogs","test-payment-applogs" ] {
json {
source => "message"
}
date {
match => [ "log_time", "yyyy-MM-dd HH:mm:ss.SSS" ]
target => "@timestamp"
}
}
}
output {
stdout {}
if [type] == "test-nginx-applogs" {
elasticsearch {
hosts => ["192.168.182.110:9200"]
index => "test-nginx-logs-%{+YYYY.MM.dd}"
}
}
if [type] == "test-product-applogs" {
elasticsearch {
hosts => ["192.168.182.110:9200"]
index => "test-product-applogs-%{+YYYY.MM.dd}"
}
}
if [type] in [ "test-dw-applogs","test-payment-applogs" ] {
elasticsearch {
hosts => ["192.168.182.110:9200"]
index => "test-center-applogs-%{+YYYY.MM.dd}"
}
}
}
EOF
开源数据收集引擎 Logstash 讲解和示例讲解就先到这里了,有任何疑问也可关注我公众号:大数据与云原生技术分享,进行技术交流,如本篇文章对您有所帮助,麻烦帮忙一键三连(点赞、转发、收藏)~
