首先打开虚拟机,启动好finallshell,
然后启动zookeeper,启动hadoop集群
然后打开本机上的hadoop文件

根据下面这个目录找到MapReduce
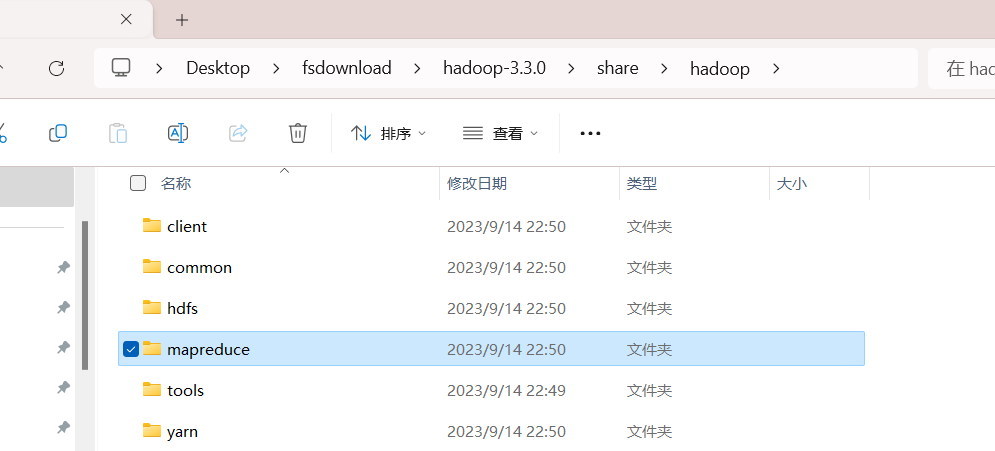
找到MapReduce中的sources
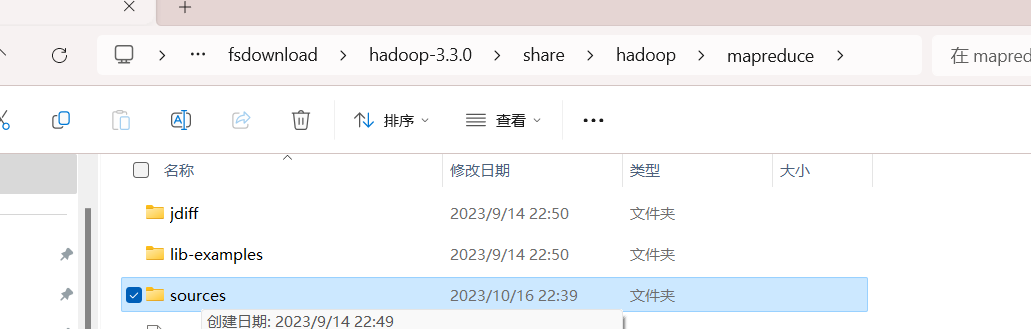
找到这个文件解压
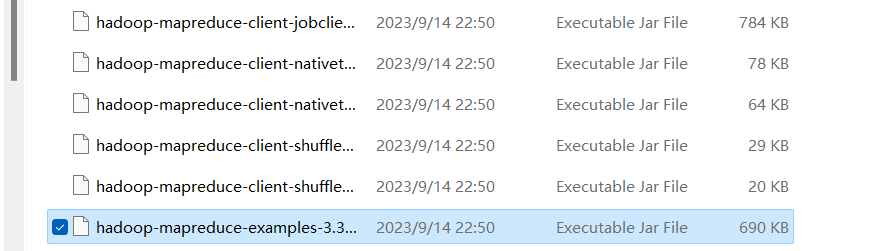
根据这个路径名找到wordcount.java
hadoop-mapreduce-examples-3.3.0-sources\org\apache\hadoop\examples
注意这一步的目的是为了确定虚拟机中的hadoop有wordcount.java这个文件如果没有的话就很抓马需要上传
这里大家确定本机的hadoop中有这个文件之后,还是把我们刚才解压的hadoop-mapreduce-examples-3.3.0-sources
这个文件夹全部传到对应的这个finallshell路径中去,以防万一下面的命令显示找不到wordcount这个文件
回到finallshell
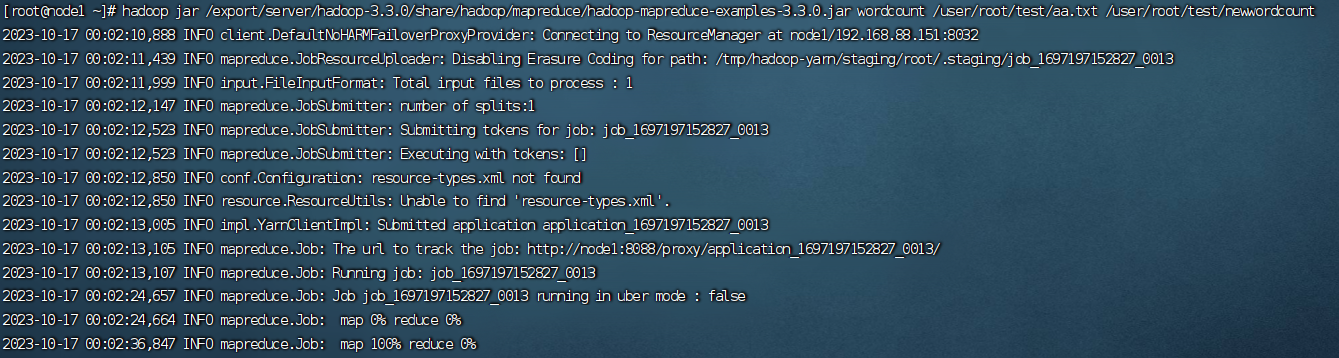
hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /user/root/test/aa.txt /user/root/test/newwordcount
输入这个命令,如果你的hadoop版本不同记得修改,除了hadoop的版本要改其他的都不动,然后后面的:
/user/root/test/aa.txt这个是你hdfs web界面上显示的路径记得跟自己的保持一致,后面的
/user/root/test/newwordcount
是出案件的一个新的newwordcount文件夹用于存储结果
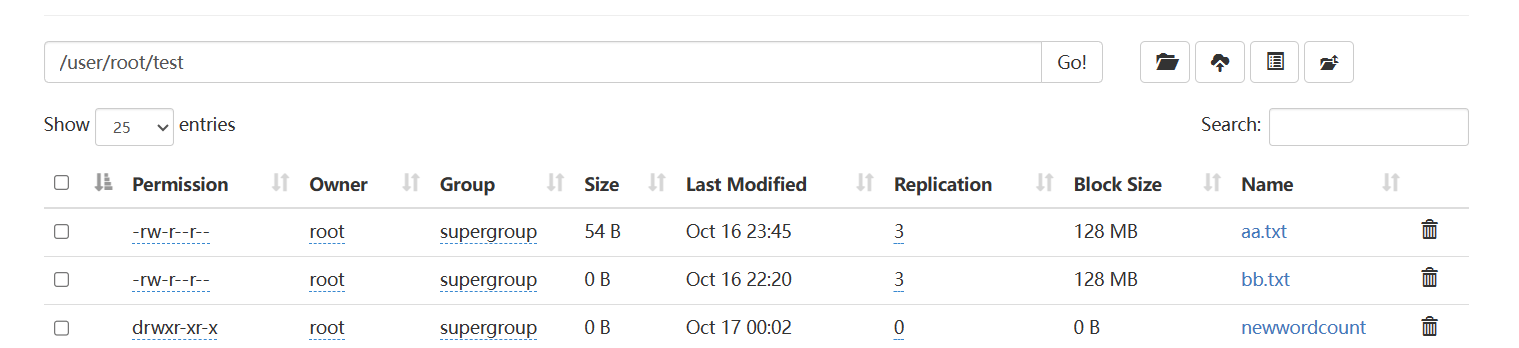
在finallshell输入命令后输出的结果存储在这里:part-r-00000
下载下来改成.txt结尾文件即可查看
补充上面我们给到的命令中只包含一个aa.txt如果你还想多弄几个不同的文件,只需要在后面加上/user/root/test/xxx.txt 这一行代码即可,想加几个文件加几个,
上面的命令前面是寻找wordcount的位置,后面的以输入文件路径为起始,最后一个文件当做结果储存文件路径:所以当你想统计两个文件的时候可以这样写:
hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /user/root/test/aa.txt /user/root/test/bb.txt /user/root/test/newwordcount
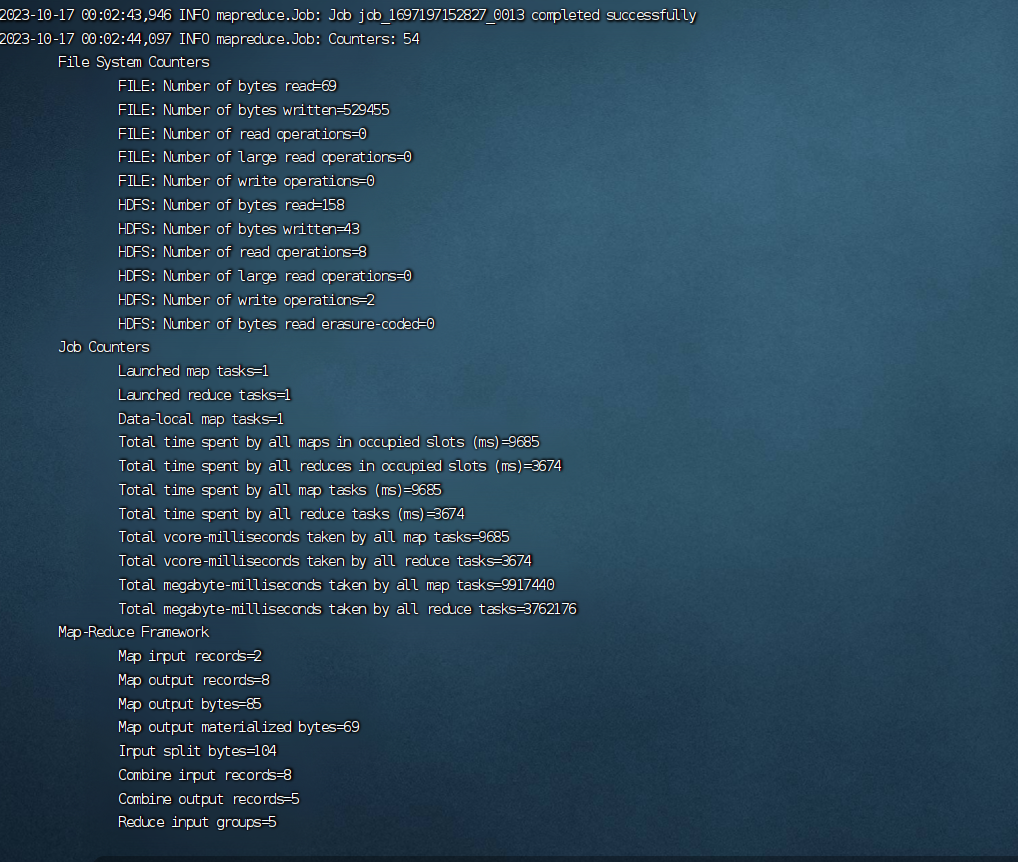
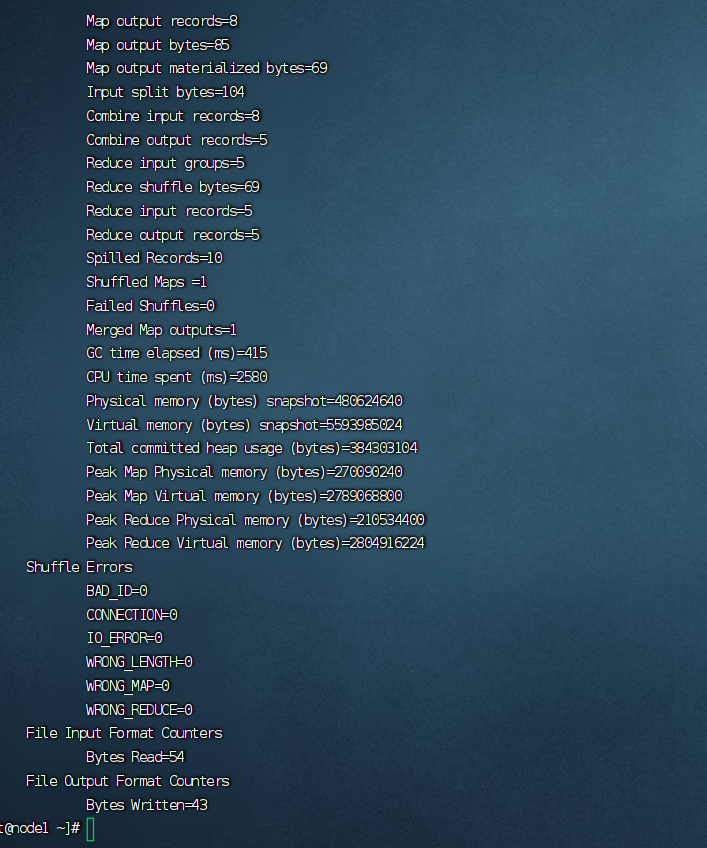
在finallshell执行命令后显示如此即为成功: