Open-Domain Aspect-Opinion Co-Mining with Double-Layer Span Extraction(基于双层跨度提取的开放域方面意见协同挖掘)
摘要
方面-观点提取任务是从评论中提取方面术语和观点术语。监督提取方法取得了最先进的性能,但需要大规模人工注释的训练数据。因此,由于缺乏训练数据,它们在开放领域任务中受到限制。
本文解决了这一挑战,同时在联合模型中挖掘方面术语、观点术语及其对应关系。我们提出了一种具有双层跨度提取框架的开放域方面意见协同挖掘(ODAO)(Open-Domain Aspect-Opinion)方法。
- ODAO首先使用基于通用依赖解析的规则生成未标记语料库的弱标签,而不是获得人工注释。
- 然后,ODAO利用这种弱监督来训练双层跨度提取框架,以提取方面术语(ATE)、观点术语(OTE)和方面-观点对(AOPE)。ODAO应用典型相关分析作为早期停止指示器,以避免模型过度拟合噪声,从而解决嘈杂的弱监督问题。
- ODAO使用自训练过程,逐渐丰富训练数据以解决弱监督偏差问题。
- 我们进行了广泛的实验,展示了所提出的ODAO的强大性能。在四个基准数据集上进行的方面-观点共提取和对提取任务的结果表明,与最先进的完全监督方法相比,ODAO可以实现竞争性甚至更好的性能。
Introduce
了解客户需求对于业务发展至关重要。由于评论数量庞大,许多企业需要进行成本效益的评论分析,以提高他们的服务质量。
评论分析包括多个任务,包括方面术语提取(ATE)、观点术语提取(OTE)、方面-观点对提取(AOPTE)、基于方面的情感分析(ABSA)、指定方面的观点提取(ASOE)等。在评论分析中,方面术语描述产品或服务属性,而观点术语描述评价者对相应产品或产品方面的观点。
考虑到评论“酒单很全,非常令人印象深刻。”,其中方面术语是“酒单”,相应的观点术语是“全”和“印象深刻”,方面-观点对是(“酒单”,“全”)和(“酒单”,“印象深刻”)。我们的工作旨在同时挖掘方面术语、观点术语及其对应关系。
总结:1. 需求背景很大2.概念定义
早期的工作专注于ATE、OTE和AOPTE任务[11,23,24],这些方法是基于规则的,利用语料库级别的统计信息和依赖解析树等特征。首先挖掘频繁模式,然后使用这些模式来形成规则。这些规则可以适用于各种评论领域。然而,由于语言表达的变化,高质量的规则可能稀少且覆盖面较低,并且一些低质量的规则可能会在结果中引入噪声。这些规则还面临着复杂的方面-观点表达的挑战(例如,一个方面可能对应于多个观点术语)。(早期工作)
现有关于ATE [14, 18, 31–33, 36]、OTE [30, 32, 35, 39]和AOPTE [2, 8, 12]任务的研究通过在人工注释的标签上训练深度神经网络取得了最先进的结果。这些监督方法可以学习方面术语和观点术语之间的复杂关系。然而,这些方法依赖于人工注释的数据集,这可能很昂贵。由于它们对标记数据集的依赖,这些方法在资源匮乏的领域可能表现不佳。(深度学习)
为了解决标记数据不足的问题,提出了几种半监督方法。类似于基于规则的方法,半监督方法[4,39]也会挖掘规则。这些方法利用人工注释数据集来挖掘高质量的规则。然后利用这些挖掘到的规则对未标记的语料库进行注释。弱标记和人工注释数据集用于训练深度神经网络。这些方法改进了跨领域任务的性能,但仍需要具有人类注释的相关语料库。(半监督方法)
总结:1. 过去的工作怎么做的 2.缺陷是什么
我们的工作旨在开发一个无需人工注释语料库的开放域方面-观点共挖掘任务框架。我们采用了先前基于规则方法的发现,形成适用于广泛领域的一些高质量规则。然后将这些修改后的规则应用于注释评论语料库。与人工注释标签相比,规则提供的弱标签是有偏差且嘈杂的。(用规则处理)
为了处理这些问题,我们提出了一种新的双层跨度抽取模型ODAO。
提出的ODAO模型同时执行三个任务,即ATE、OTE和AOPTE。我们进一步将AOPTE任务分解为两个子任务:指定方面的观点抽取(ASOE)和指定观点的方面抽取(OSAE)。这四个任务,ATE、OTE、ASOE和OSAE密切相关,可以相互增强。其中,ATE和OSAE任务的目标类似于提取方面术语,而OTE和ASOE任务的目标类似于提取观点术语。此外,ASOE和OSAE可以视为ATE和OTE的后续任务。为了在一个框架内共同建模这四个任务,我们提出了一个双层体系结构,为每个任务提供基于BERT的跨度提取器。(问题定义)
我们进一步利用任务之间的相关性来解决弱标签训练数据中的偏差和噪声问题。先前的工作注意到,早期停止可以防止模型过度拟合嘈杂的注释标签。然而,在没有基础真值标签的情况下,何时停止仍然是一个挑战。我们使用以下观察结果来解决这个难题。
直观地说,具有相同目标的任务应该对相同审核的解释达成一致。例如,由OSAE模块提取的方面术语也应由ATE模块提取。因此,耦合任务之间的相关性可以指示学习状态。当耦合模块的隐藏表示最大相关时,意味着耦合任务已经经过适当训练。因此,在评论的隐藏表示上采用规范化相关分析(CCA)来衡量这种相关性,并在训练期间使用CCA作为提前停止标准,以避免模型过度拟合嘈杂和有偏差的标签。此外,如果未标记的评论收到了四个子任务的预测结果,则该评论很可能被正确预测。因此,ODAO采用自我训练思想,将这些高度可信的评论及其预测标签添加到训练池中以丰富训练数据,然后重新训练模型。(训练到什么时候停止)
我们在不同领域的各种基准数据集上进行了广泛的实验,评估由ATE模块提取的方面术语、由OTE模块提取的观点术语以及由ASOE和OSAE模块组合提取的方面-观点对。实验结果表明,ODAO优于先前的半监督方法,并针对ATE、OTE和AOPTE三个任务的性能达到了最先进的全监督方法的竞争水平,即使ODAO仅使用少量规则来获得弱标签训练数据。实验结果证明了提出的ODAO在实际应用中的有效性。
问题总结:
-
早期工作
-
深度学习
-
半监督方法
-
用规则处理
各自有各自的问题
总之,本论文的主要贡献如下:
- 我们提出ODAO模型,在弱监督条件下同时提取评论中的方面术语、观点术语和方面-观点对。据我们所知,这是第一篇针对开放领域评论分析执行这些任务的工作。
- 我们设计了一个双层跨度提取框架,以不同方面共同建模任务。具体而言,ODAO共同建模了ATE、OTE、ASOE和OSAE任务,并充分考虑它们之间的相关性。
- 所提出的ODAO对由规则提供的有偏差和嘈杂的训练数据保持弹性。具体而言,通过使用CCA作为提前停止标准来防止模型对嘈杂的标签过度拟合,而自我训练过程则丰富了训练数据以解决训练偏差问题。
- 在各种领域的基准数据集上进行的广泛实验验证了所提出的ODAO的有效性
Multi-Variate Time Series Forecasting on Variable Subsets(多变量时间序列预测的变量子集问题)
摘要
我们在多变量时间序列预测(MTSF)领域中制定了一个新的推理任务,称为变量子集预测(VSF)。
在推理期间,只有一小部分变量可用。
由于长期数据丢失(例如传感器故障)或训练/测试之间存在高→低资源领域转移,因此变量在推理期间缺失。据我们所知,在遇到这种失败时,MTSF模型的鲁棒性尚未被研究过。
通过广泛的评估,我们首先展示了最先进方法在VSF场景下表现显著下降。
我们提出了一种非参数包装技术,可以应用到任何现有的预测模型上。通过在4个数据集和5个预测模型上进行系统实验,我们展示了即使只有原始变量的15%存在,我们的技术也能恢复模型接近95%的性能。
Introduce
多变量时间序列预测(MTSF)由于其在许多现实场景中的适用性,如交通预测、空气质量预测、电力负载预测和医学监测等,仍然受到研究界的广泛关注[10]。我们注意到两种实际情况,其中MTSF模型需要对数据稀缺性具有鲁棒性。具体而言,我们提出了在推理时模型无法访问所有用于训练的变量的MTSF情景。
-
长期变量数据不可用性:在大多数多变量时间序列应用中,时间序列数据最常见的来源是传感器。多变量时间序列中的每个变量都是传感器的输出。由于零件故障、电池耗尽等原因,传感器故障在现实部署中很常见,因为它们暴露在不良天气条件、灰尘等环境中。如[30]所述,传感器故障可能会持续很长一段时间(在许多情况下超过多个月),直到传感器被更换。这导致由此前故障的传感器产生的变量长期不可用。
-
高→低资源领域转移:时间序列模型通常用于资源可用性变化很大的域。例如,考虑产品库存预测。由于不同产品之间存在市场需求的相关性(例如,手机和它们的保护壳[14]),因此这被提出为MTSF问题。
例子:
- 在大型零售商数据集上训练的模型将拥有各种各样的产品(变量)。但是,当将同一模型应用于中小型企业(SMB)零售商时,所备货物的数量将显著受到限制,并且可能随时间而变化。因此,不可能在一组固定的产品子集上训练模型,因为不同的SMBs存货不同。
- 另一个例子是用于预测生理指标(如血糖、胰岛素、肌酐等)的MTSF模型[4]。在大型医院收集的数据训练的模型在训练期间可以访问所有变量。当同一模型被应用于没有许多诊断仪器的农村医院时,在推理过程中会缺少很多变量。在这种情况下,虽然可以事先知道变量的子集,但是创建和维护每个已知子集的模型不具有可扩展性。
- 此外,我们工作中提出的算法(第5节)能够优于或与只在已知子集上训练的模型相匹配。类似的情况也发生在其他领域,例如高端(高资源)和低配(低资源)智能手机之间的电池使用预测以及沿海(高资源)和深海(低资源)海军站之间的风速预报[9]。(介绍问题的定义)
多变量时间序列插值技术[18,24]是一个活跃研究领域。插值方法使用全局间变量模式和局部变量信息(平均值、最新值)生成合理的缺失值。插值技术显著依赖于时间局部性,因此在数据缺失很长时间时效果不佳。在高→低资源领域转移情况下,变量完全缺失。在这种情况下,插值方法甚至更不有效。据我们所知,文献中还没有研究MTSF模型在存在这种故障情况下的鲁棒性,这种故障会导致推理过程中的某些变量完全缺失。虽然为了完整性,我们在第9节中也提供了与插值方法的比较。(过去的插值方法不太行)
传统上,MTSF问题旨在通过准确建模变量间和内部变量依赖关系,同时预测N个变量的未来值,给定它们的过去时间序列值。在本文中,训练设置与标准设置相同,我们假设训练算法可以访问所有变量(用N表示)。但是在推理过程中,过去数据仅提供给一个任意小的变量子集(用S表示),我们旨在预测S中变量的未来值。我们将这称为MTSF中的变量子集预测(简称VSF)问题。图1用一个简单的例子总结了问题。(论文题目的解释,问题的定义)
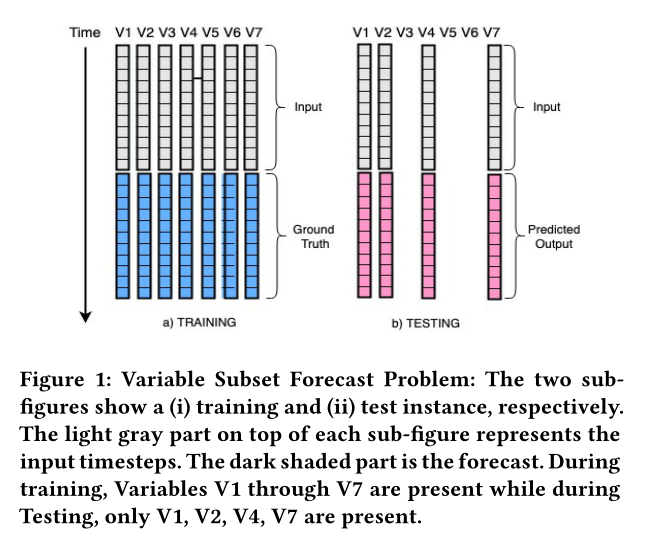
图1:变量子集预测问题:两个子图分别显示(i)训练和(ii)测试实例。每个子图顶部的浅灰色部分表示输入时间步。深色阴影部分是预测结果。在训练期间,V1到V7变量存在,而在测试期间,只有V1、V2、V4和V7存在。
VSF问题面临两个主要挑战。
- 首先,由于推理过程中缺失了数据的大部分(N-S变量),因此恢复与所有N都存在的情况下的损失是具有挑战性的。
- 其次,在推理过程中仅随机呈现一个小的S,利用N中丰富的变量间关联是不可行的。先前的研究[2、8、16、25]已经通过利用这种变量间的依赖性获得了显著的性能提升。(之前的经验不可用)此外,由于在训练期间不知道S,因此为每个子集S重新训练模型是不可行的。(问题总结)
在本文中,我们还提出了一种新的解决方案,以提高预测模型的性能,并表明即使只有15%的可用变量,它也可以恢复接近最佳情况下95%的性能。
所提出的算法是一个包装器方法,因为它可以在任何现有的预测模型上实现。
我们采用非参数方法来解决该问题,通过仅使用S变量检索最近邻居,并使用这些邻居填补缺失值。然而,这种检索是固有地有偏的,因为邻居是使用部分维度中的距离度量检索的,因此与传统的k-NN设置不同。
我们解决的另一个技术挑战是实现具有偏差检索机制的接近最优性能。我们提出了一种新颖的集成加权方法来对具有偏差的检索结果进行评分。我们的方法简单易行,更重要的是底层预测模型不需要重新训练。
本文的贡献如下:
(1) 我们制定了一项新的推理任务,称为MTSF中的变量子集预测,这是由现实世界中出现的故障情况所激发的。据我们所知,我们是第一个提出这个问题的。 (第3节)
(2) 我们提出了一种新颖的包装器解决方案来提高此设置下各种模型的性能。该算法编码非常简单,不关注预测模型的选择。(第5节)
(3) 我们进行了广泛的实验,以理解为什么当前的预测模型在VSF设置中显著表现不佳(第4节)。然后,我们通过彻底的删除操作进行定量和定性研究我们提出的解决方案。
GBPNet_ Universal Geometric Representation Learning on Protein Structures(GBPNet:蛋白质结构的通用几何表示学习)
摘要
蛋白质3D结构的表示学习对于应用,例如计算蛋白质设计或蛋白质工程来说是具有挑战性和必要的。
近年来,几何深度学习在非欧几里得领域取得了巨大成功。
尽管蛋白质可以自然地表示为图形,但主要由于在建模复杂的表示和捕捉3D结构建模中的固有相关性方面存在重大挑战,因此它仍然没有得到充分的探索。
几个挑战包括:
- 在学习过程中提取和保存多级旋转和翻译等变信息是一项挑战。
- 难以开发适当的工具来有效地利用输入的空间表示来捕捉空间维度上的复杂几何图形。
- 难以结合各种几何特征并保留固有的结构关系。
在这项工作中,我们引入了几何瓶颈感知器,并在此基础上建立了一个用于蛋白质结构表示学习的一般SO(3)-等变消息传递神经网络。所提出的几何瓶颈感知器可以集成到不同的网络架构主干中,以处理不同领域的几何数据。
这项研究为三维结构研究中的几何深度学习提供了新的思路。
从经验上讲,我们在三个核心下游任务上证明了我们提出的方法的优势,在这三个任务中,我们的模型实现了显著的改进,并优于现有的基准。有关实施,请访问https://github.com/sarpaykent/GBPNet.
Introduce
蛋白质作为所有生物的基本构建单元,在基础生物过程中起着关键作用,并吸引着来自不同领域的广泛关注 [13]。研究这些大分子的几何结构对于理解生物过程中的蛋白质反应机制和提高药物设计具有关键作用。近年来,深度学习技术的发展,特别是成功应用图神经网络模拟图结构 [35],引起了从蛋白质结构中学习的广泛关注并在过去几年中急剧增长。卷积神经网络和基于图神经网络的方法取得了一些有前途的结果,用于理解蛋白质结构,包括计算蛋白质设计 (CPD) [10, 12]、配体结合亲和力 (LBA) [20, 30] 和蛋白质结构排名 (PSR) [3, 11, 14, 24, 26, 30]。
介绍这方面的重要性,即研究意义
最近的研究展示了图神经网络从蛋白质三维结构中学习的潜在能力。尽管最近取得了进展,仍有几个挑战尚未得到充分探索。
-
首先,有效地利用空间输入信息动态捕捉跨空间维度的复杂几何结构仍是一个开放问题。虽然将三维蛋白质结构表示建模为图是很自然的,但直接采用现有的图神经网络来处理蛋白质三维结构可能不足以捕捉在学习过程中无处不在的多层次结构信息。因此,它没有调整好捕捉在空间上靠近但在序列位置上较远的氨基酸之间的相互作用。目前,处理三维结构的几何深度学习的事实选择是图神经网络 [7, 12]。消息传递神经网络通过聚合直接邻居的消息和堆叠 GNN 层来学习远程节点的信息。许多先前的研究已经鉴定出一些消息传递范式存在的问题,包括当 GNN 具有多层时过度平滑和当消息传递依赖于长程交互时过度压缩的问题 [1]。如何在不失真地传输信息的情况下有效地在图网络中流动信息对于几何深度学习至关重要。还需要改进 GNN 的传播方法来处理复杂的三维几何数据。
总结:
现有的图神经网络来处理蛋白质三维结构不足以捕捉在学习过程的多层次结构信息,急需新的网络来捕捉信息 没有调整好捕捉在空间上靠近但在序列位置上较远的氨基酸之间的相互作用。 消息传递范式存在的问题,还需要改进 GNN 的传播方法来处理复杂的三维几何数据。
- 其次,难以发现和保留节点/边和图谱之间的不同级别的几何特征。几何表示由相互关联的边和节点特征组成。蛋白质结构的表示学习不仅应依赖于节点,还应依赖于边的特征。此外,对于节点和边的标量和向量特征是相互关联的,因此具有联合学习标量和向量特征能力的模块对于模型捕捉自然蛋白质图的几何表示至关重要。例如,整体蛋白骨架由一组 Cα-CO - NH - Cα 共面单元表示。通过旋转一个共面单元可以生成多个构象,因为共面单元周围的化学键将相应旋转。因此,学习蛋白质结构表示不仅需要网络同时处理几何特征,而且还需要联合保留节点/边和图形级别信息
总结:难以发现和保留节点/边和图谱之间的不同级别的几何特征 需要具有联合学习标量和向量特征能力的模块
-
最后,捕捉大型复杂三维蛋白质结构中的非局部关系和抽象特征映射仍然具有挑战性。现有工作 [10, 12] 通常使用基于 GNN 的方法。如图1所示,一个蛋白质包含成千上万个氨基酸。氨基酸序列的折叠和分子内结合形成蛋白质的三维几何结构。空间上远离的氨基酸对可能处于接触状态。因此,问题半径是解决图中节点之间所需交互范围,对于蛋白质几何图来说是相当大的。图1 (b) 显示了一个蛋白质的三维结构,其中线显示了连接原子的化学键。由于蛋白质作为一种特定类型的图在序列和结构上都非常复杂,因此来自非相邻节点的信息可能需要在整个网络中传播。大型蛋白质图限制了模拟蛋白质三维结构的方法。学习长程依赖和复杂结构特性的要求在很大程度上增加了我们的任务难度。
总结:来自非相邻节点的信息可能需要在整个网络中传播。大型蛋白质图限制了模拟蛋白质三维结构的方法。
学习长程依赖和复杂结构特性的要求在很大程度上增加了我们的任务难度。
我们提出了一种新颖的图神经网络,用于几何图表示学习,以解决捕捉跨空间维度的复杂几何形状和整合向量和标量特征方面的挑战。具体而言,提出了一种新颖的几何瓶颈感知器 (GBP),用于集成标量和向量特征,并通过模块中的减少参数空间来增强共享的低级表示。GBP 是一种通用的插件结构,适用于几何信息存在的各种领域。此外,我们引入了一种基于 GBP 的等变消息传递神经网络 (GBPNet),用于蛋白质 3D 结构表示学习。该模型可以在特征空间中聚合复杂的空间信息,以捕捉几何模式并增加模型的可扩展性。我们总结了我们的主要贡献如下:
-
提出了一种新的SO(3)-等变信息传递神经网络。我们为蛋白质几何表示学习提出了一个新的通用框架。我们的SO(3)等变消息传递网络支持各种几何表示学习任务。
-
提出了一种用于几何表示学习的新型嵌入式模块。我们提出了一种新的几何瓶颈感知器(GBP)来集成几何特征并捕捉3D结构中复杂的几何关系。
GBP模块的输出与图形旋转和平移是等价的。最重要的是,这种设计允许模型向上扩展以堆叠更多的GNN层,允许图从更大的感受野中学习表示。
-
进行了综合实验。在具有三个蛋白质表示学习任务的三个数据集上进行的综合实验验证了GBPNet能够学习各种下游任务的蛋白质结构中的几何关系,并且优于最先进的方法。
问题总结:
- 现有的图神经网络来处理蛋白质三维结构不足以捕捉在学习过程的多层次结构信息,急需新的网络来捕捉信息 没有调整好捕捉在空间上靠近但在序列位置上较远的氨基酸之间的相互作用。消息传递范式存在的问题,还需要改进 GNN 的传播方法来处理复杂的三维几何数据。
- 难以发现和保留节点/边和图谱之间的不同级别的几何特征 需要具有联合学习标量和向量特征能力的模块
- 来自非相邻节点的信息可能需要在整个网络中传播。大型蛋白质图限制了模拟蛋白质三维结构的方法。
学习长程依赖和复杂结构特性的要求在很大程度上增加了我们的任务难度。
Saliency-Regularized Deep Multi-Task Learning显著性正则化的深度多任务学习
摘要
多任务学习(MTL)是一种框架,通过共享知识来提高多个学习任务的泛化能力。
虽然浅层的多任务学习可以学习任务关系,但只能处理预定义的特征。现代深度多任务学习可以共同学习潜在特征和任务共享,但它们对任务关系模糊不清。而且,它们预定义了应该在任务之间共享哪些层和神经元,并且不能自适应地学习。
为了解决这些挑战,本文提出了一个新的多任务学习框架,通过补充现有浅层和深度多任务学习场景的优点,共同学习潜在特征和明确的任务关系。
1. 具体而言,我们提出将任务关系建模为任务输入梯度之间的相似度,并提出了其等效性的理论分析。
1. 此外,我们创新性地提出了一个明确学习任务关系的多任务学习目标,通过新的正则化器实现。
1. 理论分析表明,由于所提出的正则化器,泛化误差已经减少。在多个多任务学习和图像分类基准测试上的大量实验证明了所提出方法的有效性、效率以及学习任务关系模式的合理性。
INTRODUCTION
多任务学习(MTL,[5])是一个基于这样一个思想的重要研究领域,即通过与其他相关任务结合使用进行归纳偏置,可以提高某个任务的性能。
传统的浅层多任务学习方法可以为单个任务拟合模型并学习任务关系,但它们不专注于从头生成特征,而是依赖于预定义并明确的特征[42, 46]。近年来,深度表示学习使得 MTL 能够“深入”,使其能够在拟合任务的预测模型的同时生成特征。
深度多任务学习通常根据两种将任务模型相关联的方式进行分类:硬参数共享和软参数共享。
- 硬参数共享方法[26, 48]本质上硬编码了哪些神经元或层用于不同任务的共享,哪些部分不共享,而没有自适应地完成。此外,它们通常共享表示学习层(例如卷积层),而不是决策层(例如用于分类的全连接层)。
- 软参数共享方法[8, 30]不需要硬编码共享模式,而是为每个任务构建单独的模型,并“软化”地规范它们之间的相关性。因此,软参数共享在学习任务关系方面具有更好的灵活性,但可能不是很高效,因为它的模型参数随着任务数量呈线性增长。
相比之下,硬参数共享更“简洁”,但需要预定义哪些部分是共享的,哪些部分不共享。
总结:介绍硬参数共享和软参数共享以及多任务学习
因此,尽管多任务学习(MTL)是一个持久存在的研究领域,但它仍然是一个具有挑战性和开放性的领域,需要付出更多的努力来解决上述硬参数共享和软参数共享的模型灵活性和简洁性之间的平衡等挑战。虽然最近有一些尝试试图缓解这种困境,例如在硬参数共享中在任务特定层中规范化任务关系,以实现未共享层中的知识转移 [26],以及通过分支[27]或神经架构搜索[40]等方法自适应地学习共享哪些部分或不共享哪些部分,但研究前沿仍然存在多个关键瓶颈,包括:
(1)难以规范不同任务的深度非线性函数。自适应地学习任务关系需要规范不同任务的预测函数,然而对于非线性-非参数函数而言,这要求在输入的整个连续域内进行规范化,因此更加困难。为了解决这个问题,现有的工作[26,39]通常采用简化的问题,即规范化神经网络参数。请注意,这种简化偏离了原始问题并过于受限。例如,有两个具有不同潜在神经元排列的神经网络可以表示相同的函数。此外,即使它们具有不同的架构,它们仍然可能表示相同的功能 [22]。这种差距会使模型的通用性和有效性下降。
(2)联合特征生成和任务关系学习缺乏可解释性。尽管浅层MTL无法生成特征,但由于它们通过手工制作特征的使用方式来学习显式的任务相关性,因此其具有良好的可解释性。然而,在深度MTL中,生成的特征没有明确的含义,黑盒模型之间的关系高度模糊。提高生成特征和任务关系的可解释性非常重要,但也具有挑战性。
(3)难以进行理论分析。虽然对于浅层MTL有丰富的理论分析,例如关于广义误差[3]和规范化MTL算法满足表现定理的条件[2],但类似的分析面临强大的障碍,无法将其扩展到输入空间由按层嵌入所给出的神经网络的深度MTL中。增强模型容量和不同深度MTL模型之间的理论关系的理论分析至关重要。
本文提出了一种新的显著性正则化深度多任务学习(SRDML)框架来解决上述挑战。
- 首先,我们将传统线性多任务学习中的特征权重重新考虑为输入梯度,然后借用显著性检测的概念将特征学习推广到非线性情况。
- 其次,我们将任务关系问题重新定义为任务之间显著区域之间的相似性,以正则化和推断任务关系。
- 第三,为了验证我们的假设,我们对它们的等价性进行了理论分析。同时,我们还对所提出的正则化如何有助于减少泛化误差进行了理论分析。
- 最后,我们在合成和多个大规模真实世界数据集上与各种基线进行比较,证明了我们的模型的有效性和效率。