查看数据
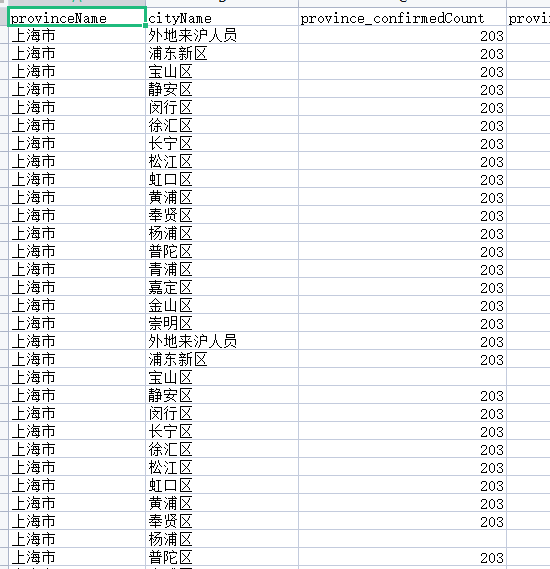
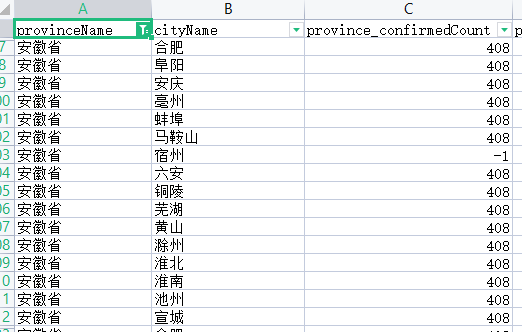
可以看到省确诊数(province_confirmedCount)列存在空缺值和负值的情况

省治愈数(province_curedCount)列存在空缺值
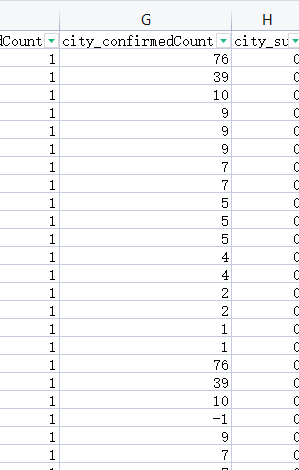
市确诊数(city_confirmedCount)列存在负值的情况
数据处理
1.省确诊数(province_confirmedCount)列与省治愈数(province_curedCount)列的空缺值与负值的处理
思路:
已知在同一省下同一更新时间province_confirmedCount(省确诊数)和province_curedCount(省治愈数)是一样的

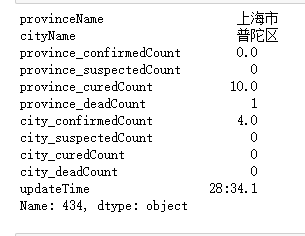
如图,在这里province_confirmedCount(省确诊数)和province_curedCount(省治愈数)分别为169和10
而且province_confirmedCount列为省确诊数,不存在有负值的情况
所以在处理空缺值和负值时可以先计算其他的province_curedCount和province_curedCount平均值来填充
因为要计算平均值,所以要把负值转为空缺值,这样才不会影响平均值的计算
源代码如下:
data.loc[data['province_confirmedCount'] <= 0 , 'province_confirmedCount'] = np.nan data[['province_confirmedCount', 'province_curedCount']] =\ data.groupby(['provinceName', 'updateTime'])[['province_confirmedCount', 'province_curedCount']].transform(lambda x: x.fillna(x.mean()))
这段代码的作用是对数据集中的省份(provinceName)和更新时间(updateTime)进行分组,然后对每个分组中的确诊人数(province_confirmedCount)和治愈人数(province_curedCount)进行缺失值填充,填充方式是用该分组中缺失值的均值进行填充。
具体解释如下:
- data:代表数据集;
- data[['province_confirmedCount', 'province_curedCount']]:代表选择数据集中的省份确诊人数和治愈人数这两列数据;
- data.groupby(['provinceName', 'updateTime']):代表按照省份和更新时间进行分组;
- [['province_confirmedCount', 'province_curedCount']]:代表选择分组后的省份确诊人数和治愈人数这两列数据;
- transform(lambda x: x.fillna(x.mean())):代表对每个分组中的缺失值进行填充,填充方式是用该分组中缺失值的均值进行填充。
总之,这段代码的作用是对数据集中的省份确诊人数和治愈人数这两列数据进行缺失值填充,填充方式是用每个省份和更新时间分组后的均值进行填充。
检查
province_confirmedCount列
源数据:

处理后数据:

province_curedCount列
源数据:
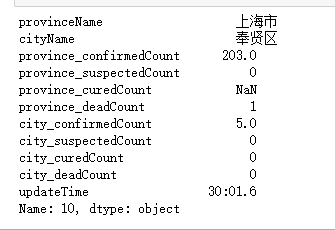
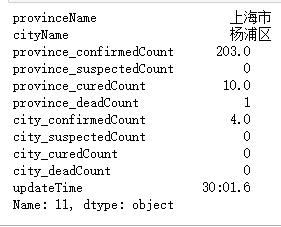
处理后数据:
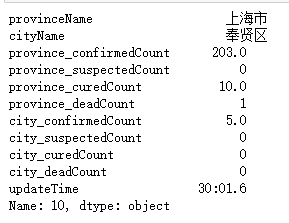
2.city_confirmedCount中负值的处理
思路:

如图所示,这里的city_confirmedCount为市确诊数,所以也不存在负值的情况.
而且这里所有的city_confirmedCount列加起来应该等于province_confirmedCount列的数也就市203
所以其中-1的值应该为19
源代码如下:
data.loc[data['city_confirmedCount'] < 0, 'city_confirmedCount'] = np.nan group_provicetime=data.groupby(['provinceName','updateTime']) def fillna_city_confirmedCount(df): province_mean = df['province_confirmedCount'].mean() city_sum = df['city_confirmedCount'].sum() if df['city_confirmedCount'].isnull().any(): fill_value = province_mean - city_sum df['city_confirmedCount'] = df['city_confirmedCount'].fillna(fill_value) return df data=group_provicetime.apply(fillna_city_confirmedCount)
这段代码的作用是对数据集中的城市确诊人数(city_confirmedCount)进行缺失值填充,填充方式是用该城市所在省份其他城市的确诊人数均值减去已有城市确诊人数之和进行填充。
具体解释如下:
- group_provicetime=data.groupby(['provinceName','updateTime']):代表按照省份和更新时间进行分组;
- def fillna_city_confirmedCount(df):定义一个名为fillna_city_confirmedCount的函数,该函数的作用是对传入的数据框df进行处理;
- province_mean = df['province_confirmedCount'].mean():计算该省份的确诊人数均值;
- city_sum = df['city_confirmedCount'].sum():计算该城市所在省份其他城市的确诊人数之和;
- if df['city_confirmedCount'].isnull().any(): 判断该城市的确诊人数是否有缺失值;
- fill_value = province_mean - city_sum:计算需要填充的值,即该省份的确诊人数均值减去已有城市确诊人数之和;
- df['city_confirmedCount'] = df['city_confirmedCount'].fillna(fill_value):用需要填充的值对缺失值进行填充;
- return df:返回处理后的数据框。
最后,通过group_provicetime.apply(fillna_city_confirmedCount)将fillna_city_confirmedCount函数应用于每个省份和更新时间分组中的城市确诊人数(city_confirmedCount)列,对缺失值进行填充,填充方式是用该城市所在省份其他城市的确诊人数均值减去已有城市确诊人数之和进行填充。
检查
源数据:
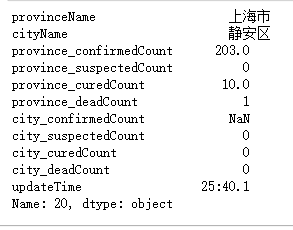
处理后数据:
