Introduction to SQL
SQL(Structured Query Language),是关系数据库的标准查询语言。
SQL 的特点:
-
综合统一
SQL 集数据定义语言(DDL),数据操纵语言(DML),数据控制语言 (DCL)功能于一体。

-
高度非过程化
SQL 只要提出“做什么”,而无须指明“怎么做”,因此无须了解存取路径。存取路径的选择以及 SQL 的操作过程由系统自动完成。 -
面向集合的操作方式
SQL 采用集合操作方式,不仅操作对象、查找结果可以是元组的集合,而且一次插入、删除、更新操作的对象也可以是元组的集合。 -
以同一种语法结构提供多种使用方式
SQL 是独立的语言,能够独立地用于联机交互的使用方式。同时 SQL 也是嵌入式语言,能够嵌入到高级语言(例如 C,C++,Java)程序中,供程序员设计程序时使用。
在两种不同的方式下, SQL 的语法结构基本上是一致的。
支持 SQL 的关系数据库管理系统同样支持关系数据库三级模式结构,如下图所示。其中外模式包含若干视图(view)和部分基本表(base table),模式包括若干基本表,内模式包括若干存储文件(stored file)。
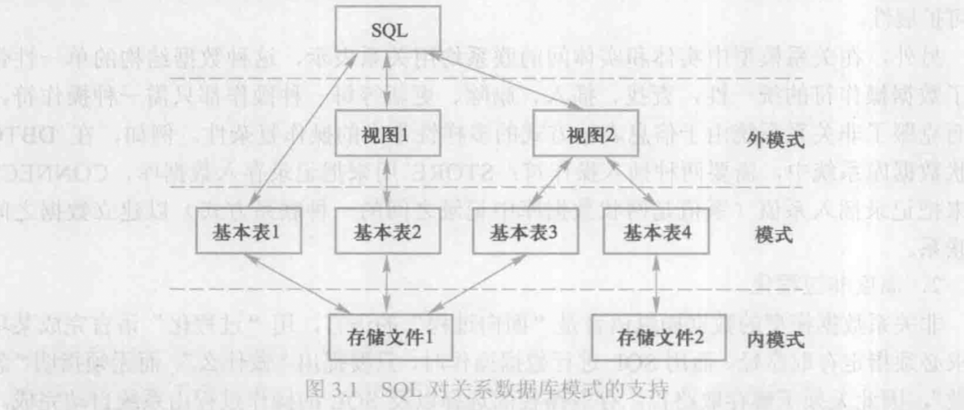
基本表是本身独立存在的表,在关系数据库管理系统中一个关系就对应一个基本表。一个或多个基本表对应一个存储文件,一个表可以带若干索引,索引也存放在存储文件中。
存储文件的逻辑结构组成了关系数据库的内模式。存储文件的物理结构对最终用户是隐蔽的。
视图是从一个或几个基本表导出的表。它本身不独立存储在数据库中,即数据库中只存放视图的定义而不存放视图对应的数据。这些数据仍存放在导出视图的基本表中,因此视图是一个虚表。视图在概念上与基本表等同,用户可以在视图上再定义视图。
数据定义
CREATE 创建,DROP 删除,ALTER 修改(只有表和索引有这项)。
模式(SCHEMA)
定义模式(CREATE SCHEMA)
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>;
/* 如果没有指定模式名,则模式名隐含为用户名 */
-
为用户
CHEN定义一个学生-课程模式S-T。CREATE SCHEMA "S-T" AUTHORIZATION CHEN;
删除模式(DROP SCHEMA)
DROP SCHEMA <模式名> <CASCADE|RESTRICT>; /* CASCADE 和 RESTRICT 两者必选其一 */
CASCADE(级联):删除模式的同时把该模式中所有的数据库对象全部删除。
RESTRICT(限制):如果该模式中定义了下属的数据库对象(如表、视图等),则拒绝该删除语句的执行。仅当该模式中没有任何下属的对象时才能执行。
基本表(TABLE)
定义基本表(CREATE TABLE)
-
建立一个学生信息表
Student。CREATE TABLE Student ( Sno CHAR(9) PRIMARY KEY, Sname CHAR(20) UNIQUE, Ssex CHAR(2), Sage SMALLINT, Sdept CHAR(20) ); -
建立一个学生选课表
SC。CREATE TABLE SC ( Sno CHAR(9), Cno CHAR(4), Grade SMALLINT, PRIMARY KEY (Sno,Cno), /* 主码由两个属性构成,必须作为表级完整性进行定义 */ FOREIGN KEY (Sno) REFERENCES Student(Sno), /* 表级完整性约束条件 */ FOREIGN KEY (Cno) REFERENCES Course(Cno) /* 表级完整性约束条件 */ );
如果完整性约束条件涉及该表的多个属性列,则必须定义在表级上,否则既可以定义在列级也可以定义在表级。
删除基本表(DROP TABLE)
DROP TABLE <表名> [RESTRICT | CASCADE];
CASCADE(级联):删除该表没有限制条件。在删除基本表的同时,相关的依赖对象都将被一起删除。
RESTRICT(限制):删除该表是有限制条件的。欲删除的基本表不能被其他表的约束所引用(如 CHECK , FOREIGN KEY 等约束),不能有视图、触发器、存储过程或函数等。如果存在依赖该表的对象,则此表不能被删除。
- 若表上建有视图,选择
RESTRICT时表不能删除;选择CASCADE时可以删除表,视图也自动被删除。CREATE VIEW IS_Student AS SELECT Sno,Sname,Sage FROM Student WHERE Sdept='IS'; DROP TABLE Student CASCADE; /* DROP TABLE Student RESTRICT; 会返回 Error */
修改基本表(ALTER TABLE)
ALTER TABLE <表名>
[ADD [COLUMN] <新列名> <数据类型> [完整性约束]]
[ADD <表级完整性约束>]
[DROP [COLUMN] <列名> [CASCADE| RESTRICT]]
[DROP CONSTRAINT <完整性约束名> [RESTRICT | CASCADE]]
[ALTER COLUMN <列名> <数据类型>];
ADD 子句用于增加新列、新的列级完整性约束条件和新的表级完整性约束条件。
DROP COLUMN 子句用于删除表中的列,如果指定了 CASCADE 短语,则自动删除引用了该列的其他对象;如果指定了 RESTRICT 短语,则如果该列被其他对象引用,关系数据库管理系统将拒绝删除该列。
DROP CONSTRAINT 子句用于删除指定的完整性约束条件。
ALTER COLUMN 子句用于修改原有的列定义,包括修改列名和数据类型。
-
向
Student表增加“入学时间”列,其数据类型为日期型。ALTER TABLE Student ADD S_entrance DATE; -
将年龄的数据类型由字符型(假设原来的数据类型是字符型)改为整数。
ALTER TABLE Student ALTER COLUMN Sage INT; -
增加课程名称必须取唯一值的约束条件。
ALTER TABLE Course ADD UNIQUE(Cname);
模式与表
每一个基本表都属于某一个模式,一个模式包含多个基本表。
定义基本表所属模式的三种方法:
-
在表名中明显地给出模式名。
CREATE TABLE "S-T".Student(...); /* Student 所属的模式是 S-T */ -
在创建模式语句中同时创建表。
/* 为用户 ZHANG 创建一个模式 TEST,并且在其中定义一个表 TAB1。 */ CREATE SCHEMA TEST AUTHORIZATION ZHANG CREATE TABLE TAB1 ( COL1 SMALLINT, COL2 INT, COL3 CHAR(20), COL4 NUMERIC(10,3), COL5 DECIMAL(5,2) ); -
设置所属的模式,这样在创建表时表名中不必给出模式名。
索引(INDEX)
WAITING TO BE UPDATED.
建立索引(CREATE INDEX)
删除索引(DROP INDEX)
修改索引(ALTER INDEX)
数据查询
单表查询
只涉及一个表的查询叫做单表查询。
选择表中的若干列
查询某个表的全部列:
SELECT * FROM STUDENT;
查询某个表的部分列,列显示的具体顺序可以自定义:
SELECT Sname, Sno FROM Student;
目标列表达式 不仅可以是算术表达式,还可以是字符串常量、函数等:
SELECT Sname, 2021 - Sage FROM Student;
选择表中的若干元组
消除取值重复的行:DISTINCT:
SELECT DISTINCT Sno FROM SC;
查询满足条件的元组:WHERE 子句:
-
查询所有年龄在
20岁以下的学生姓名及其年龄。SELECT Sname, Sage FROM Student WHERE Sage < 20; -
查询年龄不在
20~23岁之间的学生姓名、系别和年龄。SELECT Sname, Sdept, Sage FROM Student WHERE Sage NOT BETWEEN 20 AND 23; -
查询不是计算机科学系、数学系和信息系学生的姓名和性别。
SELECT Sname, Ssex FROM Student WHERE Sdept NOT IN ('CS', 'MA', 'IS'); -
查询所有有成绩的学生学号和课程号。
SELECT Sno, Cno FROM SC WHERE Grade IS NOT NULL; /* `is NULL` 不能用 `= NULL` 代替 */ -
查询计算机科学系年龄在
20岁以下的学生姓名。SELECT Sname FROM Student WHERE Sdept = 'CS' AND Sage < 20; /* AND 优先级比 OR 高,可用括号来改变优先级 */ -
字符匹配
[NOT] LIKE '<匹配串>' [ESCAPE '<换码字符>']
其含义是查找指定的属性列值与 <匹配串> 相匹配的元组。
<匹配串> 可以是一个完整的字符串,也可以含有通配符 % 和 _。
% 代表任意长度(长度可以为 0 )的字符串。
e.g. a%b 表示以 a 开头,以 b 结尾的任意长度的字符串。
_ 代表任意单个字符。
e.g. a_b 表示以 a 开头,以 b 结尾的长度为 3 的任意字符串。
-
查询所有姓刘的学生的姓名、学号和性别。
SELECT Sname, Sno, Ssex FROM Student WHERE Sname LIKE '刘%'; -
查询姓
欧阳且全名为三个汉字的学生的姓名。SELECT Sname FROM Student WHERE Sname LIKE '欧阳_';
如果用户要查询的字符串本身就含有通配符 % 或 _ ,这时就要使用 ESCAPE <换码字符> 短语对通配符进行转义。
-
查询
DB_Design课程的课程号和学分。SELECT Cno, Ccredit FROM Course WHERE Cname LIKE 'DB\_Design' ESCAPE '\';
ORDER BY 子句
ORDER BY 子句可以对查询结果按照一个或多个属性列的升序(ASC)或降序(DESC)排列,默认值为升序。空值按最大值来参与排序。
查询选修了 3 号课程的学生的学号及其成绩,查询结果按分数的降序排列:
SELECT Sno, Grade FROM SC WHERE Cno = '3' ORDER BY Grade DESC;
聚集函数
为了进一步方便用户,增强检索功能,SQL 提供了许多聚集函数。
- 统计元组个数:
COUNT(*) - 统计一列中值的个数:
COUNT([DISTINCT | ALL] <列名>) - 计算一列值的总和(此列必须为数值型):
SUM([DISTINCT | ALL] <列名>) - 计算一列值的平均值(此列必须为数值型):
AVG([DISTINCT | ALL] <列名>) - 求一列中的最大值和最小值:
MAX([DISTINCT | ALL] <列名>),MIN([DISTINCT | ALL] <列名>)
聚集函数只能用于 SELECT 子句和 GROUP BY 中的 HAVING 子句。
-
查询学生总人数。
SELECT COUNT(*) FROM Student; -
查询选修了课程的学生人数。
SELECT COUNT(DISTINCT Sno) FROM SC; -
计算选修
1号课程的学生平均成绩。SELECT AVG(Grade) FROM SC WHERE Cno = '1'; -
查询选修
1号课程的学生最高分数。SELECT MAX(Grade) FROM SC WHERE Cno='1'; -
查询学生
201215012选修课程的总学分数。SELECT SUM(Ccredit) FROM SC, Course WHERE Sno = '201215012' AND SC.Cno = Course.Cno;
GROUP BY 子句
GROUP BY 子句将查询结果按某一列或多列的值分组,值相等的为一组。
将查询结果分组的目的是细化聚集函数的作用对象。如果未对查询结果分组,聚集函数将作用于整个查询结果。对查询结果分组后,聚集函数将分别作用于每个组,即每一组都有一个函数值。
-
查询平均成绩大于等于
90分的学生学号和平均成绩。SELECT Sno, AVG(Grade) FROM SC GROUP BY Sno HAVING AVG(Grade) >= 90;
连接查询
若一个查询同时涉及两个以上的表,称为连接查询。连接查询是关系数据库中最主要的查询。
等值与非等值连接查询
[<表名1>.]<列名1> <比较运算符> [<表名2>.]<列名2>
-
查询每个学生及其选修课程的情况。
SELECT Student.*, SC.* FROM Student, SC WHERE Student.Sno = SC.Sno; /* 将 Student 与 SC 中同一学生的元组连接起来 */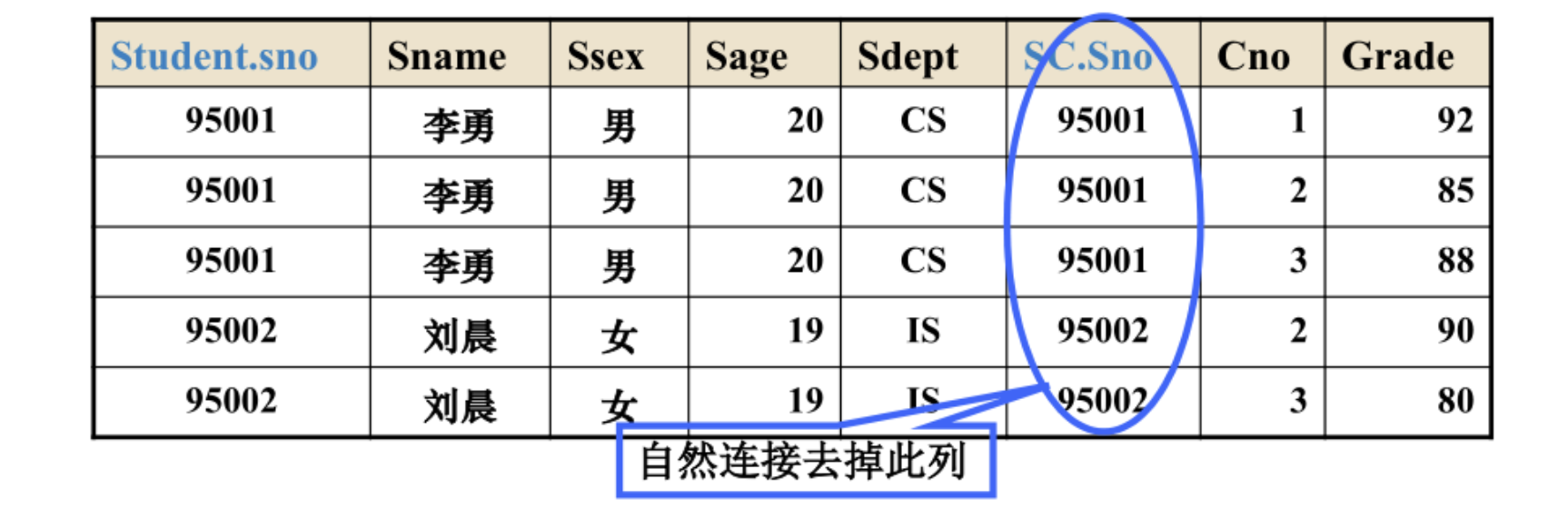
自身连接
一个表与其自己进行连接,称为表的自身连接。
需要给表起别名以示区别。且由于所有属性名都是同名属性,因此必须使用别名前缀。
-
查询每一门课的间接先修课(即先修课的先修课)。
SELECT FIRST.Cno, SECOND.Cpno FROM Course FIRST, Course SECOND WHERE FIRST.Cpno = SECOND.Cno;
外连接
普通连接操作只输出满足连接条件的元组,而外连接操作以指定表为连接主体,将主体表中不满足连接条件的元组一并输出。
左外连接列出左边关系中所有的元组,右外连接列出右边关系中所有的元组。
-
使用外连接查询每个学生及其选修课程的情况。
SELECT Student.Sno, Sname, Ssex, Sage, Sdept, Cno, Grade FROM Student LEFT OUTER JOIN SC ON (Student.Sno = SC.Sno);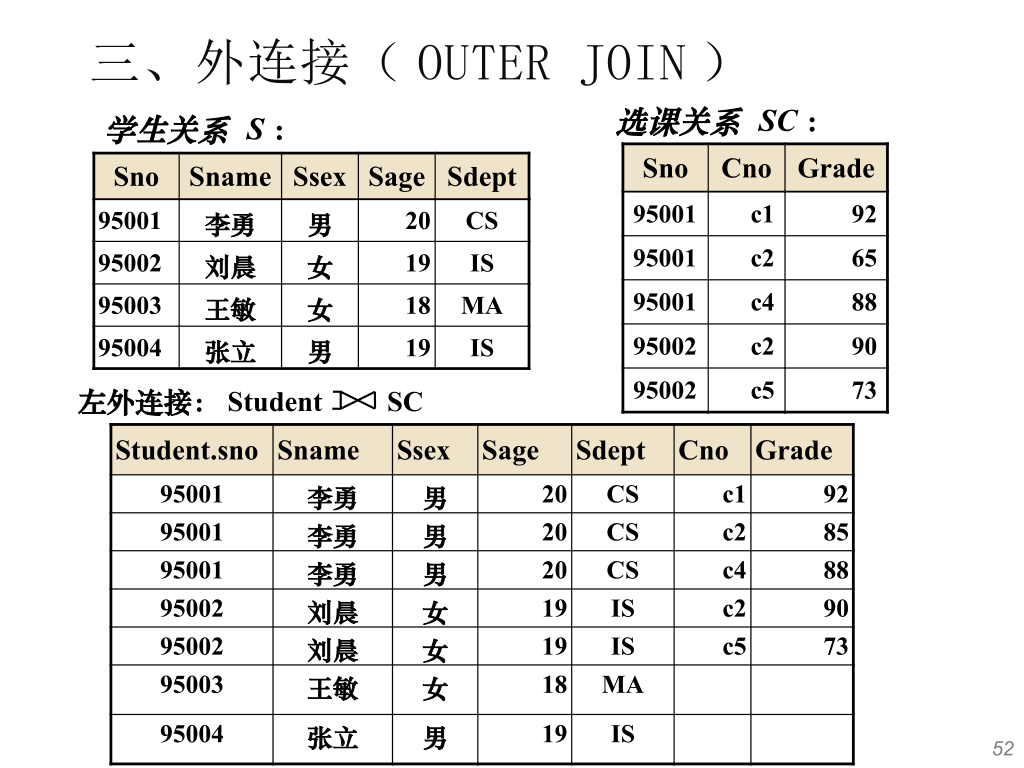
多表连接
两个以上的表进行连接称为多表连接。
-
查询每个学生的学号、姓名、选修的课程名及成绩。
SELECT Student.Sno,Sname,Cname,Grade FROM Student,SC,Course WHERE Student.Sno=SC.Sno AND SC.Cno=Course.Cno
关系数据库管理系统在执行多表连接时,通常是先进行两个表的连接操作,再将其连接结果与第三个表进行连接。
嵌套查询
一个 SELECT-FROM-WHERE 语句称为一个查询块。嵌套查询是指将一个查询块嵌套在另一个查询块的 WHERE 子句或 HAVING 短语的条件中的查询。
SELECT Sname /* 外层查询或父查询 */
FROM Student
WHERE Sno IN (
SELECT Sno /* 内层查询或子查询 */
FROM SC WHERE Cno='2'
)
子查询的 SELECT 语句不能使用 ORDER BY 子句,ORDER BY 子句只能对最终查询结果排序。
不相关子查询:子查询的查询条件不依赖于父查询,即由里向外逐层处理。
相关子查询:子查询的查询条件依赖于父查询。
带有 IN 谓词的子查询
在嵌套查询中,子查询的结果往往是一个集合,所以谓词 IN 是嵌套查询中最经常使用的谓词。
-
查询与
刘晨在同一个系学习的学生。SELECT Sno, Sname, Sdept FROM Student WHERE Sdept IN ( SELECT Sdept FROM Student WHERE Sname='刘晨' )也可以用自身连接来完成:
SELECT S1.Sno, S1.Sname, S1.Sdept FROM Student S1, Student S2 WHERE S1.Sdept = S2.Sdept AND S2.Sname = '刘晨';
带有比较运算符的子查询
-
找出每个学生超过他自己选修课程平均成绩的课程号。
SELECT Sno, Cno FROM SC x /* x 是表SC的别名,又称为元组变量,可以用来表示SC的一个元组 */ WHERE Grade >= ( SELECT AVG(Grade) FROM SC y WHERE y.Sno = x.Sno );