作业①
实验要求
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
码云链接
代码展示
MySpider部分
import scrapy
from datamining.实验3.shiyan31.shiyan31.items import Shiyan31Item
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
# 定义start_requests方法,生成对特定URL的请求并返回该请求
def start_requests(self):
url = "http://www.weather.com.cn/"
# 使用yield返回一个Request对象,该对象会发送一个GET请求到url指定的网址
yield scrapy.Request(url=url, callback=self.parse)
# 定义parse方法,用于处理服务器返回的响应
def parse(self, response):
# 定义一个全局变量item,这样在处理响应之外的地方也可以引用到这个变量
global item
try:
# 使用UnicodeDammit处理响应内容的编码,使其可以被正确处理
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
# 通过处理后的响应获取unicode格式的内容
data = dammit.unicode_markup
# 使用BeautifulSoup解析unicode格式的内容
soup = BeautifulSoup(data, 'html.parser')
# 在soup对象中使用CSS选择器查找符合条件的li标签元素,这里的选择条件是class属性以"line"开始
allimg = [img['src'] for img in soup.find_all("img", attrs={})]
for img in allimg:
item = Shiyan31Item()
item["img"] = img # 将img赋值给item的img属性
yield item
# 如果在处理响应的过程中出现异常,则打印异常信息
except Exception as err:
print(err)
items部分
import scrapy
class Shiyan31Item(scrapy.Item):
# define the fields for your item here like:
img = scrapy.Field()
# name = scrapy.Field()
pass
pipelines部分
from urllib import request
i = 1
class Shiyan31Pipeline:
def process_item(self, item, spider):
try:
global i
request.urlretrieve(item["img"], f'C:/Users/lenovo/PycharmProjects/pythonProject/datamining/实验3/images/{i}.jpg') # 保存图片
i = i + 1
except Exception as err:
print(err)
return item
settings部分
BOT_NAME = "shiyan31"
SPIDER_MODULES = ["shiyan31.spiders"]
NEWSPIDER_MODULE = "shiyan31.spiders"
ITEM_PIPELINES = {
'shiyan31.pipelines.Shiyan31Pipeline': 300,
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "shiyan31 (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
运行结果
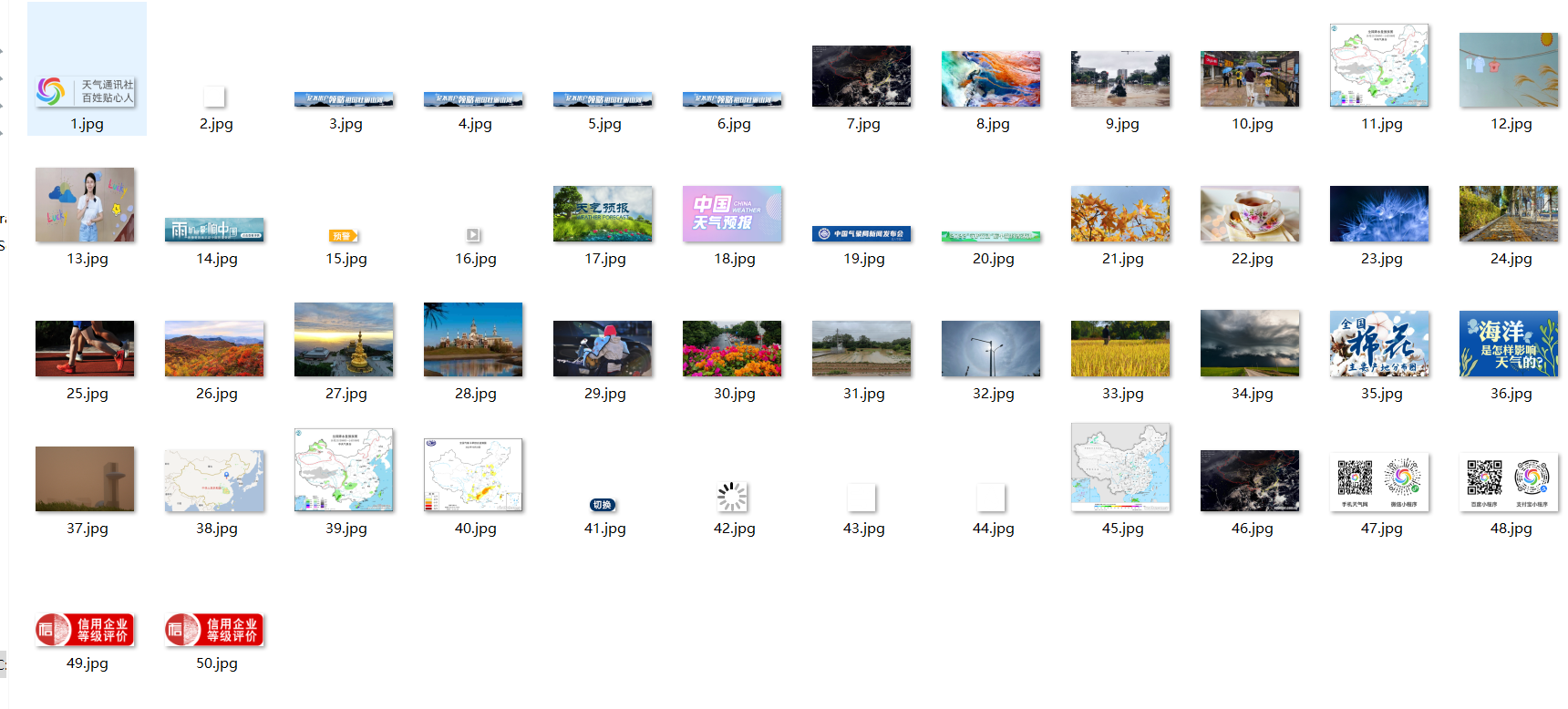
实验心得
这个实验总体难度不高,加上之前完成过多线程爬取,图片爬取实验,总体代码编程没什么难度,但是因为对scrapy不熟悉,花费了很多时间熟悉scrapy,通过这次实验,我对scrapy更加熟悉了,对我帮助很大。
作业②
实验要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:
Gitee文件夹链接
码云链接
代码展示
MySpider部分
import scrapy
from datamining.实验3.shiyan32.shiyan32.items import Shiyan32Item
from lxml import etree
from selenium import webdriver
import time
class MySpider(scrapy.Spider):
name = "mySpider"
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=chrome_options)
# 定义start_requests方法,生成对特定URL的请求并返回该请求
def start_requests(self):
url = 'https://quote.eastmoney.com/center/gridlist.html#hs_a_board' # 要爬取的网页URL
self.driver.get(url)
time.sleep(1) # 等待页面加载完毕
html = etree.HTML(self.driver.page_source) # 获取网页HTML内容
yield scrapy.Request(url, self.parse, meta={'html': html})
# 定义parse方法,用于处理服务器返回的响应
def parse(self, response):
# 定义一个全局变量item,这样在处理响应之外的地方也可以引用到这个变量
global item
html = response.meta['html']
lis = html.xpath('//*[@id="table_wrapper-table"]/tbody/tr')
for link in lis:
id = link.xpath('./td[2]/a/text()')[0]
name = link.xpath('./td[3]/a/text()')[0]
zxj = link.xpath('./td[5]/span/text()')[0]
updown1 = link.xpath('./td[6]/span/text()')[0]
updown2 = link.xpath('./td[7]/span/text()')[0]
cjl = link.xpath('./td[8]/text()')[0]
zf = link.xpath('./td[10]/text()')[0]
max = link.xpath('./td[11]/span/text()')[0]
min = link.xpath('./td[12]/span/text()')[0]
jt = link.xpath('./td[13]/span/text()')[0]
zt = link.xpath('./td[14]/text()')[0]
item = Shiyan32Item()
item['id'] = id
item['name'] = name
item['zxj'] = zxj
item['updown1'] = updown1
item['updown2'] = updown2
item['cjl'] = cjl
item['zf'] = zf
item['max'] = max
item['min'] = min
item['jt'] = jt
item['zt'] = zt
yield item
items部分
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Shiyan32Item(scrapy.Item):
# define the fields for your item here like:
id = scrapy.Field()
name = scrapy.Field()
zxj = scrapy.Field()
updown1 = scrapy.Field()
updown2 = scrapy.Field()
cjl = scrapy.Field()
zf = scrapy.Field()
max = scrapy.Field()
min = scrapy.Field()
jt = scrapy.Field()
zt = scrapy.Field()
pass
pipelines部分
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pandas as pd
import mysql.connector
class Shiyan32Pipeline:
def process_item(self, item, spider):
mydb = mysql.connector.connect(
host="localhost",
user="root",
password="wjy514520",
database="mydb"
)
mycursor = mydb.cursor()
sql = "INSERT INTO shiyan31 (id, name, zxj, updown1, updown2, cjl, zf, max, min, jt, zt) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
val = (item['id'],item['name'] ,item['zxj'],item['updown1'],item['updown2'],item['cjl'],item['zf'],item['max'],item['min'],item['jt'],item['zt'])
mycursor.execute(sql, val)
mydb.commit()
return item
settings部分
BOT_NAME = "shiyan32"
SPIDER_MODULES = ["shiyan32.spiders"]
NEWSPIDER_MODULE = "shiyan32.spiders"
ITEM_PIPELINES = {
'shiyan32.pipelines.Shiyan32Pipeline': 300,
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "shiyan32 (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
运行结果
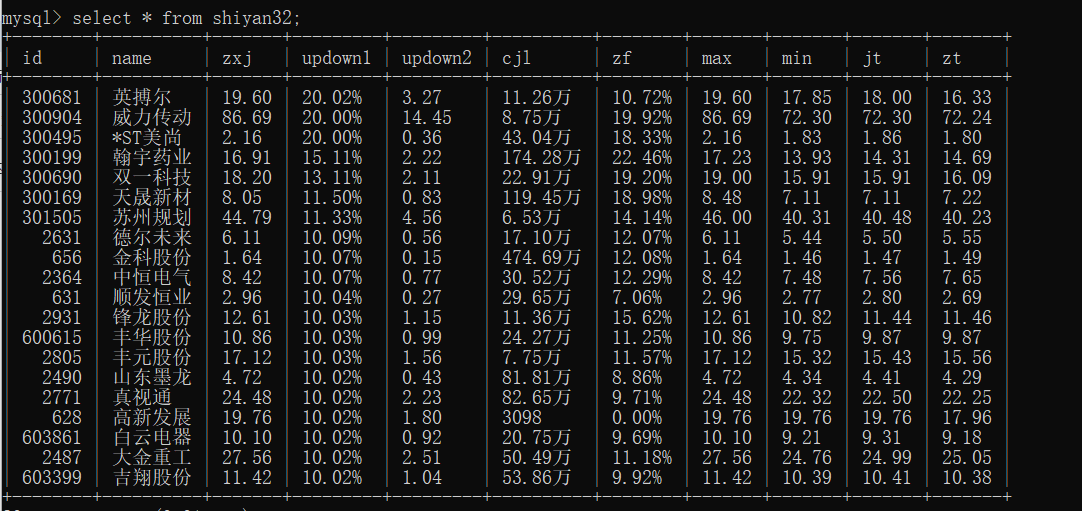
实验心得
个人感觉这个实验难度较大,股票页面为动态页面,用常规方法无法爬取,需要用selenium方法才能爬取需要的数据,加之对于Xpath和scrapy并不熟悉,花费了很多时间进行数据的提取和数据的处理,加上编程并不熟练,花费了大量时间在这个实验上,之前也没有用过mysql处理数据,也花费了不少时间学习相关内容,不过这些时间没有浪费,让我学到了很多东西。
作业③
实验要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
码云链接
代码展示
MySpider部分
import scrapy
from datamining.实验3.shiyan33.shiyan33.items import Shiyan33Item
from lxml import etree
from selenium import webdriver
import time
class MySpider(scrapy.Spider):
name = "mySpider"
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=chrome_options)
# 定义start_requests方法,生成对特定URL的请求并返回该请求
def start_requests(self):
url = 'https://www.boc.cn/sourcedb/whpj/' # 要爬取的网页URL
self.driver.get(url)
time.sleep(1) # 等待页面加载完毕
html = etree.HTML(self.driver.page_source) # 获取网页HTML内容
yield scrapy.Request(url, self.parse, meta={'html': html})
# 定义parse方法,用于处理服务器返回的响应
def parse(self, response):
# 定义一个全局变量item,这样在处理响应之外的地方也可以引用到这个变量
global item
html = response.meta['html']
lis = html.xpath('/html/body/div/div[5]/div[1]/div[2]/table/tbody/tr')
i = 1
for link in lis:
if i != 1:
texts = link.xpath('./td[1]/text()')
if texts:
name = texts[0]
else:
name = ''
texts = link.xpath('./td[2]/text()')
if texts:
TBP = texts[0]
else:
TBP = ''
texts = link.xpath('./td[3]/text()')
if texts:
CBP = texts[0]
else:
CBP = ''
texts = link.xpath('./td[4]/text()')
if texts:
TSP = texts[0]
else:
TSP = ''
texts = link.xpath('./td[5]/text()')
if texts:
CSP = texts[0]
else:
CSP = ''
texts = link.xpath('./td[8]/text()')
if texts:
TIME = texts[0]
else:
TIME = ''
item = Shiyan33Item()
item["name"] = name
item["TBP"] = TBP
item["CBP"] = CBP
item["TSP"] = TSP
item["CSP"] = CSP
item["TIME"] = TIME
yield item
if i == 1:
i = i + 1
items部分
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Shiyan33Item(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TIME = scrapy.Field()
pass
pipelines部分
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import mysql.connector
class Shiyan33Pipeline:
def process_item(self, item, spider):
global result
mydb = mysql.connector.connect(
host="localhost",
user="root",
password="wjy514520",
database="mydb"
)
mycursor = mydb.cursor()
sql = "INSERT INTO shiyan33 (name, TBP, CBP, TSP, CSP, TIME) VALUES (%s, %s, %s, %s, %s, %s)"
val = (item['name'], item['TBP'], item['CSP'], item['TSP'], item['CSP'], item['TIME'])
mycursor.execute(sql, val)
mydb.commit()
return item
settings部分
BOT_NAME = "shiyan33"
SPIDER_MODULES = ["shiyan33.spiders"]
NEWSPIDER_MODULE = "shiyan33.spiders"
ITEM_PIPELINES = {
'shiyan33.pipelines.Shiyan33Pipeline': 300,
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "shiyan33 (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
运行结果

实验心得
这个实验远不如实验二来得困难,应该是经过了实验二的折磨,对于selenium和scrapy有了更深的理解,如何将数据传入mysql数据库也在完成实验二后就掌握了,实验三完成的速度很快,但也帮我巩固了相关知识。