一、背景
熟悉.NET的同学应该用过CLR 中的BinaryWriter、BinaryReader类对二进制流文件写入、读取int数据,写入和读取都非常简单,这是同一语言/平台写入与读取,实际还有其他语言/平台读写需求(如C++程序读取C#程序生成的二进制文件),由于int是4个字节数据,因此它的存储必然是大端序或小端序的一种,具体是哪一种呢?它的底层是如何实现的?我们通过对源码分析逐步弄清疑惑。
我们知道诸如int这种多个字节的数据类型,在存储和传输时是有顺序的,即大小端问题。
大端序:从左至右,左侧为高位,右侧为低位
小端序:从右至左,右侧为高位,左侧为低位
假设有一个4字节的数组,byte[] array=new byte[4]{4,3,2,1};
用大端序存储:
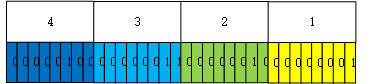
用小端序存储:
二、写入代码分析
1、写入代码
using (FileStream fileStream = new FileStream(@"D:\cnblogs\BinaryFile.dat", FileMode.Open))
{
using (BinaryWriter writer = new BinaryWriter(fileStream))
{
//构造4字节的int32数据,从左到右4个字节值分别为:4、3、2、1
writer.Write(4*256*256*256+3*256*256+2*256+1);
writer.Flush();
}
}
2、分析写入底层源码
查看Write(int value)方法源码:
protected Stream OutStream; private byte[] _buffer; // temp space for writing primitives to. // Writes a four-byte signed integer to this stream. The current position // of the stream is advanced by four. // public virtual void Write(int value) { _buffer[0] = (byte) value; _buffer[1] = (byte) (value >> 8); _buffer[2] = (byte) (value >> 16); _buffer[3] = (byte) (value >> 24); OutStream.Write(_buffer, 0, 4); }
该方法中前4行,通过强制转换为byte、移位操作运算,获取int的从右向左(从低到高)的四个字节,分别复制到缓冲区中
_buffer[0] = (byte) value;
将int型数据截取最右侧第1个字节的值
_buffer[1] = (byte) (value >> 8);对value右移8位,得到的结果强转为byte类型的数据,最终获取int从右至左数第2个字节的值
_buffer[2] = (byte) (value >> 16);
对value右移16位,得到的结果强转为byte类型的数据,最终获取int从右至左数第3个字节的值
_buffer[3] = (byte) (value >> 24);
对value右移24位,得到的结果强转为byte类型的数据,最终获取int从右至左数第4个字节的值
方法的最后一行,将缓冲区4个字节数据写入到输出流中
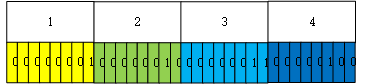
整理存储结构如下:
回到文章开头的问题,BinaryWriter使用大端序还是小端序存储int型数据?
显然是小端序存储。
三、读取代码分析
1、读取代码
using (FileStream fileStream = new FileStream(@"D:\cnblogs\BinaryFile.dat", FileMode.Open))
{
using (BinaryReader reader = new BinaryReader(fileStream))
{
var num = reader.ReadInt32();
}
}
2、分析读取底层源码
查看ReadInt32()方法源码:
private bool m_isMemoryStream; // "do we sit on MemoryStream?" for Read/ReadInt32 perf public virtual int ReadInt32() { if (m_isMemoryStream) { if (m_stream==null) __Error.FileNotOpen(); // read directly from MemoryStream buffer MemoryStream mStream = m_stream as MemoryStream; Contract.Assert(mStream != null, "m_stream as MemoryStream != null"); return mStream.InternalReadInt32(); } else { FillBuffer(4); return (int)(m_buffer[0] | m_buffer[1] << 8 | m_buffer[2] << 16 | m_buffer[3] << 24); } }
代码中有一个if else的分支语句,查看变量m_isMemoryStream的值,发现构造函数初始化时通过判断输入流是否为MemoryStream
public BinaryReader(Stream input, Encoding encoding, bool leaveOpen) { m_stream = input; m_isMemoryStream = (m_stream.GetType() == typeof(MemoryStream)); }
本文通过FileStream读取,显然走else中的代码:
FillBuffer(4); return (int)(m_buffer[0] | m_buffer[1] << 8 | m_buffer[2] << 16 | m_buffer[3] << 24);
其中FillBuffer(4) 是将Stream读取数据到缓存字节数组m_buffer中
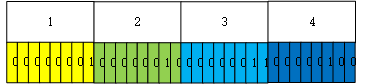
最后通过:return (int)(m_buffer[0] | m_buffer[1] << 8 | m_buffer[2] << 16 | m_buffer[3] << 24);
还原写入的数据。
上述运算,由于移位运算符优先级高于位运算符,会优先计算
1、执行移位操作
m_buffer[1] << 8,左移8位变为2个字节
m_buffer[2] << 16,左移16位变为3个字节
m_buffer[3] << 24,左移24位变为4个字节
2、执行位运算
上述过程可视化表示如下:

四、总结
通过分析源码,确认BinaryWriter使用了小端序存储int型数据。
由此当有其他语言平台(如C++)读取BinaryWriter生成的二进制文件的需求时,应注意使用小端序读取文件中的int型数据。