在现代大型服务器中多个内存节点机器一般都采用NUMA架构,而NUMA架构中不同的内存节点在Linux内核中使用pg_data_t类型(实际是struct pglist_data)来表示表示。
Linux又为每个内存节点根据内存地址的高低划分了不同的区域类型如ZONE_DMA、ZONE_DMA32、ZONE_NORMAL,一个区域在Linux中使用数据结构struct zone表示。
一个内存节点中的所有zone组织在pg_data_t的struct zone node_zones[MAX_NR_ZONES]成员中,这个node_zones有MAX_NR_ZONES个struct zone元素,但是这其中并非所有的zone都是有效的,这依赖于架构以及系统的差异;比如,有些架构中没有ZONE_HIGH。
这样一来,我们就可以了解在NUMA架构的系统中各个节点和zone的组织情况,以4个节点为例如下所示:
node0: node_zones[DMA]、node_zones[DMA32]、node_zones[ZONE_NORMAL]、node_zones[ZONE_MOVABLE]
node1: node_zones[DMA]、node_zones[DMA32]、node_zones[ZONE_NORMAL]、node_zones[ZONE_MOVABLE]
node2: node_zones[DMA]、node_zones[DMA32]、node_zones[ZONE_NORMAL]、node_zones[ZONE_MOVABLE]
node3: node_zones[DMA]、node_zones[DMA32]、node_zones[ZONE_NORMAL]、node_zones[ZONE_MOVABLE]
有了这个组织结构,我们可以顺利的在NUMA系统中分配内存了吗?No!
思考一下这些问题:当一个进程要分配内存时,系统中多个NUMA内存节点它首选从哪个节点分配内存?如果首选的节点内存不足了,第二选择的内存节点是哪个呢?内存节点选好了,从哪个内存zone分配内存呢?
首先,Linux会先计算好每个节点与其他节点之间的距离:
Node Fallback list ------------------ 0 0 1 2 3 1 1 0 3 2 2 2 3 0 1 3 3 2 1 0
上面node0距离其他节点由近到远分别为node0,node1, node2, node3。每个节点到其他的节点的距离决定了在当前节点分配内存时的选择顺序,因此node0分配内存的先后顺序就是node0 > node1 > node2 > node3,这种内存的分配策略在Linux中叫ZONELIST_FALLBACK
当然还有一种特殊情况,有些场景中内存分配时只能够在当前NUMA节点分配,在Linux中使用__GFP_THISNODE标志分配内存时就是这种情况,此时的分配策略是ZONELIST_NOFALLBACK。
Linux为每个NUMA节点创建了一个struct zonelist node_zonelists[MAX_ZONELISTS]数组来实现上面的ZONELIST_FALLBACK和ZONELIST_NOFALLBACK策略;如果分配内存时有__GFP_THISNODE标志则选用node_zonelists[ZONELIST_NOFALLBACK],否则选用node_zonelists[ZONELIST_FALLBACK]。
内存分配时优先选择哪个内存节点的问题解决了,那么如何选择具体的zone呢?答案还是在这个node_zonelists[]上。
首先node_zonelists[]是struct zonelist结构的数组,而struct zonelist结构的定义如下:
struct zonelist { struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1]; /* MAX_ZONES_PER_ZONELIST = (MAX_NUMNODES * MAX_NR_ZONES) */ };
可以看到struct zonelist实际上是一个 MAX_NUMNODES * MAX_NR_ZONES + 1大小的 struct zoneref数组;其实可以看做是两层MAX_NUMNODES,表示一个个的NUMA node;而MAX_NR_ZONES则是每个节点上的zones。而一个NUMA node中的node_zonelists[ZONELIST_NOFALLBACK]就是将系统中所有节点的zones按照距离依次铺开:
node0 | node1 | node2 | node3
MOVABLE,NORNMAL,DMA32,DMA| MOVABLE,NORNMAL,DMA32,DMA| MOVABLE,NORNMAL,DMA32,DMA| MOVABLE,NORNMAL,DMA32,DMA
上面是node0的node_zonelists[]的组织情况,首先从节点维度来看数组元素先后顺序是按离node0距离近远来分布的;其次,从一个node的zone分布情况来看是从高到低的zone分布来的。
因此当前上下文为node0分配内存时,优先选择距离最近的node0;然后再优先从最高的zone去分配(其实这里描述并不准确,zone的起点需要根据gfp来确定,然后从高到低优先级依次降低)。
还有一点需要补充,node_zonelist中存放的其实是struct zoneref。而struct zoneref的定义非常简单,代表着pg_data_t.node_zones[]中的一个zone:
struct zoneref { struct zone *zone; /* Pointer to actual zone */ /* 这里的zone_idx指的是当前这个zoneref所代表的zone在对应的NUMA节点上node_zones[]中的index */ int zone_idx; /* zone_idx(zoneref->zone) */ };
咋一看struct zoneref和struct zone其实就差了一个zone_idx,这个有什么作用呢,为什么要这样设计呢?
首先,node_zonelist中的zoneref.zone是指向node_zones[]中具体某个zone的指针,这是为了避免对大数据结构的查找引用带来的cache miss。
其次,zone_idx代表着zoneref.zone在node_zones[]数组中的索引,注意如果node_zones[]中的某个zone是一个”空”zone,即没有管理任何一个page,则node_zonelist[]中的zoneref则不会有对应的元素。也就是说node_zonlist[]中代表一个node的zoneref元素并不是和node_zones[]一一对应的,它是node_zones[]的一个子集;为此需要有zone_idx来表示它在node_zones[]中的位置。
最后,用一张图来做总结:
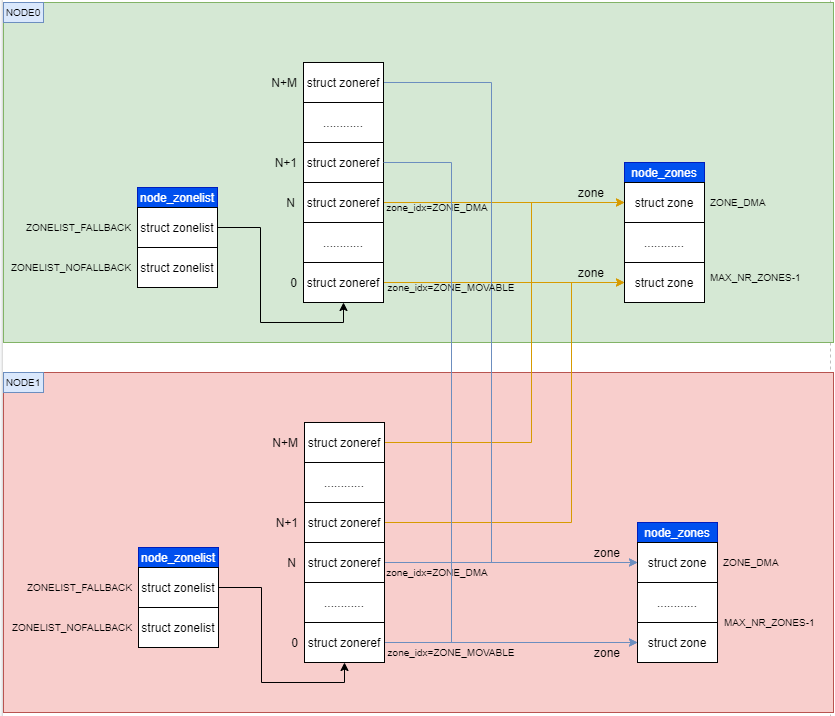
图1 两个节点的ZONELIST_FALLBACK示意图