综合设计——多源异构数据采集与融合应用综合实践
| 这个项目属于哪个课程 | 2023数据采集与融合技术 |
|---|---|
| 组名、项目简介 | 组名:普雷蒙奇、项目需求:多模态情感分析、项目目标:通过在网页中搜索关键词来得到一个综合的情感分析、项目开展技术路线:前端、python 、华为云平台 |
| 团队成员学号 | 102102112、102102115、102102116、102102118、102102119、102102120、102102156、102102159 |
| 这个项目目标 | 通过在网页中上传文本、图片、视频或音频分析其中的情感 |
| 其他参考文献 | [1]梁爱华,王雪峤 多模态学习数据采集与融合、[2]陈燕、赖宇斌 基于CLIP和交叉注意力的多模态情感分析模型 、[3]武星、殷浩宇 面向视频数据的多模态情感分析 |
Gitee文件夹链接:
https://gitee.com/w-jking/crawl_project/blob/master/大作业/datacrawl.7z
项目整体介绍:
项目名称:
国产手机情感分析
项目背景:
近年来,国货新潮流兴起,华为Mate60系列供应链90%以上来自国内,消费者的真实反馈对于手机品牌口碑和市场表现至关重要,收集和分析消费者对于国产手机的反馈,不仅可以为用户提供一个选择手机品牌的依据,也可以为品牌提供有价值的建议和改进方向。
项目目标:
通过采集和挖掘不同模态(文本、图片、音频)的数据,运用不同的情感分析模型,构造一个可以对国产手机各个方面进行多模态分析的系统,对国产手机品牌得到一个综合的情感分析,直观的感受到大众对于国产手机的的态度,以便于更好的判断国产手机中的“国货之光”。
项目具体流程图:
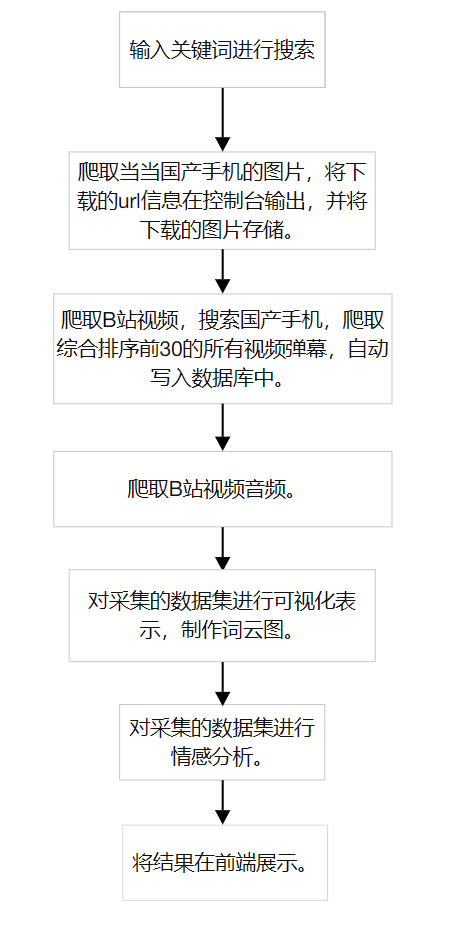
技术路线:
-
前端开发:
-
使用HTML、CSS和JavaScript进行前端的是界面设计,实现输入关键词和视频数量和弹幕数量后得到一个综合分析。
-
提升用户体验,使用动画效果和过渡效果,可以提高页面的交互性和吸引力。
-
-
后端开发:
-
使用python语言来实现后端开发的编写
-
使用Django框架来处理前端信息的接收,以及后端得到的信息返回
-
-
数据处理与分析:
-
文本爬取:
- 爬取B站弹幕和京东评论,但是京东评论在项目最后阶段爬取不到数据,所以只保留了弹幕的爬取。
- 采用request库的findall()函数获取指定cid的弹幕,并通过正则表达式提取出弹幕文本。
-
图片爬取:
- 爬取当当网的图片。
- 使用requests库的findall()函数和正则表达式取所有满足条件的图片链接。
- 并使用多线程机制将图片进行下载。
-
音/视频爬取:
- 爬取B站相关视频。
- 采用request库的findall()函数和正则表达式提取JSON中BV号。
- 使用正则表达式和json库获取视频和音频的url。
- 使用requests库来下载视频和音频文件。
-
文本分析: 首先考虑ERNIE-UIE文心模型,可是配置不成功,导致没有结果显示。接着考虑讯飞的情感分析模型,发现只能单句分析,不太符合需求,最后考虑百度云的API接口。
-
视频和音频分析:
- 对B站相关视频进行爬取,得到视频和音频。
- 使用Whisper方法将音频转为文本。
- 对上传的音频文件进行特征提取和情感识别。
-
图片分析:
- 使用预训练的BERT模型进行图像处理。
- 使用预训练的ResNet-50提取图片特征。
- 将图像特征输入到分类器中进行预测。
-
-
结果输出与展示:将分析结果通过前端界面展示。
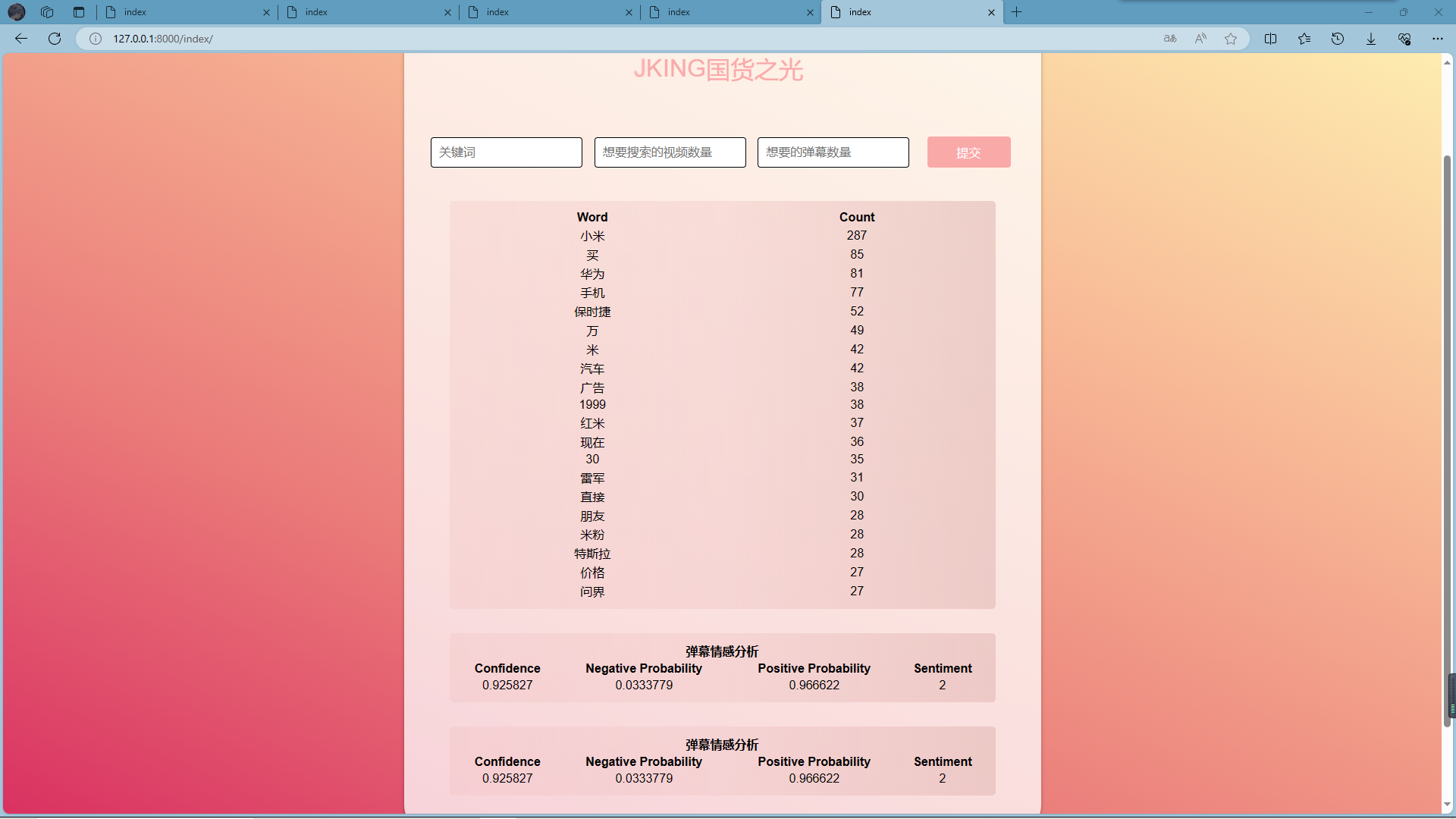
- 结果输出与展示:
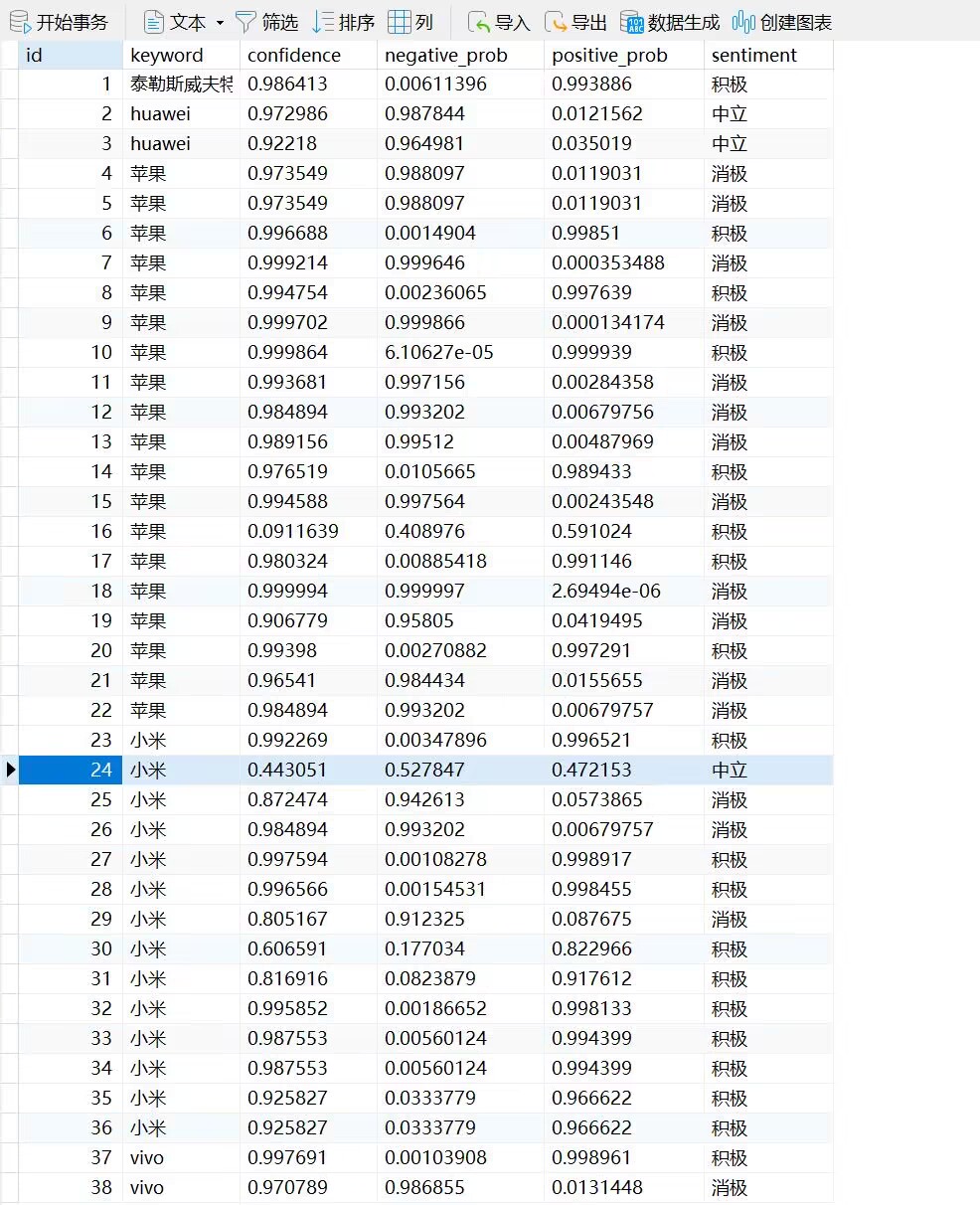
个人部分介绍:
这次的项目实践主要负责寻找关于模型的资料、部分数据爬虫、完善项目博客这几个工作。
- 寻找模型和数据集
首先考虑ERNIE-UIE文心模型,可是配置不成功,导致没有结果显示。

接着考虑讯飞的情感分析模型,发现只能单句分析,不太符合需求。

为模型的训练寻找数据集
- 部分数据爬虫
由于,该项目需要对视频进行爬取分析,和我小组成员璐璐一起完成了这部分,实现了对B站的视频进行爬取和分析。
import time
import requests
import re
import json
import os
def get_bvs(keyword, desired_count):
headers = {
'User-Agent': '',
'Cookie': ''
}
current_count = 0 # 当前已获取的BV号数量
bvs = [] # 存储所有获取的BV号
page = 1 # 初始页码
while current_count < desired_count:
search_url = f'https://api.bilibili.com/x/web-interface/search/all?keyword={keyword}&page={page}&order='
response = requests.get(search_url, headers=headers)
data = response.text
BVs = re.findall('BV..........', data)
bvs.extend(BVs)
current_count += len(BVs)
page += 1
if len(BVs) == 0:
break
print(search_url)
time.sleep(1)
# 保存获取的BV号
with open("bvids.txt", "w") as f:
for bvid in bvs:
f.write(bvid + "\n")
return bvs[:desired_count]
def download_media(bv, video_path, audio_path):
url = f'https://www.bilibili.com/video/{bv}/'
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76",
"Referer": "https://www.bilibili.com/", # 设置防盗链
}
resp = requests.get(url=url, headers=header)
obj = re.compile(r'window.__playinfo__=(.*?)</script>', re.S)
html_data = obj.findall(resp.text)[0] # 从列表转换为字符串
json_data = json.loads(html_data)
videos = json_data['data']['dash']['video'] # 这里得到的是一个列表
video_url = videos[0]['baseUrl'] # 视频地址
audios = json_data['data']['dash']['audio']
audio_url = audios[0]['baseUrl'] # 音频地址
resp1 = requests.get(url=video_url, headers=header)
with open(os.path.join(video_path, f'{bv}.mp4'), mode='wb') as f:
f.write(resp1.content)
resp2 = requests.get(url=audio_url, headers=header)
with open(os.path.join(audio_path, f'{bv}.wav'), mode='wb') as f:
f.write(resp2.content)
print(f"BV号为 {bv} 的视频和音频已下载完成")
def main(key):
# keyword = input("请输入关键词:") # 输入要搜索的关键词
keyword = key
# desired_count = int(input("请输入总共需要获取的BV号数量:")) # 总共需要获取的BV号数量
desired_count = 10
bvs = get_bvs(keyword, desired_count)
video_path = "videos"
audio_path = "audios"
if not os.path.exists(video_path):
os.mkdir(video_path)
if not os.path.exists(audio_path):
os.mkdir(audio_path)
for bv in bvs:
download_media(bv, video_path, audio_path)
if __name__ == "__main__":
main()
项目初期选择了爬取京东评论,和璐璐负责50个国产品牌的爬取。但是,等项目后期发展发现不能爬取了。

- 完善项目整体博客
心得体会
本次实践总体来说是有很大的收获的,算是对这门课程一个整体的回顾,又复习运用了request库和正则表达式,尝试了新的爬取内容。也学到了如何去调用合适的大模型,也算一定程度上了解到了学科的前沿知识,对自己的眼界有很大的提升,也进一步加强了自己对数据采集这么课的认识。
gitee文件夹链接