BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generatio
| Paper | 模型参数量 | 训练数据量 | 数据集来源 |
|---|---|---|---|
| BLIP | 224M-361M | 14M - 129M | COCO, Visual Genome, Conceptual12M, SBU caption LAION-115M |
结构
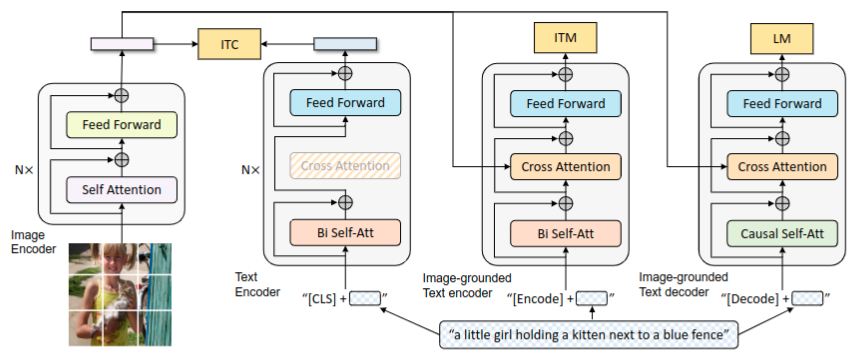
结构如Fig.2所示
- 视觉特征模块-ViT 将图片拆分成patch序列然后提取得到图片的特征序列。在序列前添加[CLS]token,该位置对应的ViT输出特征作为全局图片特征的表示。
- 文本特征模块-双向Attention encoder,同样的在序列前面添加[CLS]token,该位置对应encoder的最终输出特征作为文本的整体表示。
- 图文混合encoder,论文中称为image-grounded text encoder。用[Encode]token添加到文本序列的前面,该位置对应的encoder最终输出特征作为图文对的多模态特征表示。
- 图文混合decoder,论文中称为image-grounded text decoder。用[Decode]token放在首位,用于启动自回归生成。decoder模块中掩模矩阵是下三角。
不同模态特征融合是如何体现呢?
融合与All you need is Attention中Decoder模块处理事一致的。不管是encoder还是decoder模块,都是ViT模块提取图像特征,得到图像块的特征序列。encoder和decoder都是文本信息经过各自的Attention模块后,与图像特征序列进行cross-Attention操作。
损失函数
ITC
Image-Text contrastive Loss图文对比损失函数。该损失函数目标是将视觉Transformer特征与文本Transformer特征进行对齐,使得正的图文对具有相似的表示,而负的图文对则相反。该损失函数的实现可参考论文[1]
ITM
Image-Text Matching Loss图文匹配损失函数。该损失函数目标是学习图文多模态表示,该表示抓住了图文细粒度对齐信息。ITM是一个二分类,来预测图文对是正的还是负的。为了挖掘更有价值的负样本对,采用了难例挖掘方法,具体实现可参考论文[1]
LM
Language Modeling Loss,图生文损失函数,实际上是下一个token预测,一个交叉熵损失函数。
CapFilt
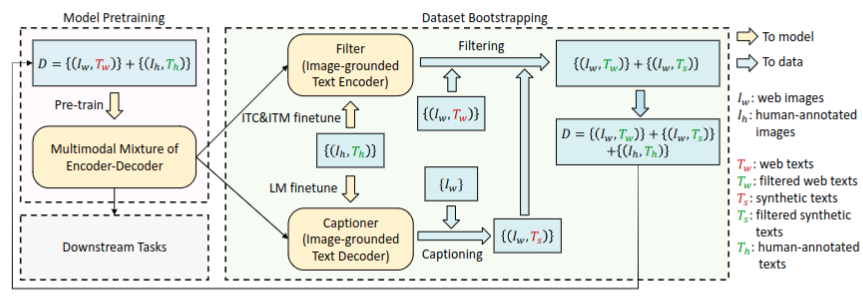
由于标注成本过高,因此仅有少量的高质量人工标注的图文对数据,如COCO数据集。可以从网络上收集大量的图文对数据,然而网页上对图片的文本描述信息不都很准确,从而导致训练的图文模型性能受到干扰。论文提出一种提升图文数据集文本描述信息质量的方法。如Fig.3 所示
该方法包括两个模块:文本注释器Captioner和文本过滤器Filter,这二者是上述提到的VLP模型的一部分。
- Captioner则是基于图像的文本生成器 text decoder,给定一张图片生成一段描述该图片的文本。基于LM损失函数在COCO又进行了微调。
- Filter则是基于图像的图文过滤器,基于ITC和ITM损失函数在COCO上进行微调。对网络上收集的图文数据和基于Captioner合成的图文数据进行过滤。
实验
实验设置
image transformer初始化于在ImageNet预训练的ViT模型,text transformer初始化于\(BERT_{base}\)。ViT模型探索两种变体ViT-B/16, ViT-L/16.论文中除特殊说明外,BILP都是指使用ViT-B/16模型结构。
- 训练集: 人工标注的数据集COCO和Visual Gnome,网络上收集的数据集Conceptual Captions, Conceptual 12M, LAION-115M。训练仅使用了其中14M的数据量。
CapFilt的影响
表1 展示了在两种不同数据集下,使用CapFilt方法在下游任务,如图文检索和图片注释上的性能表现。这些下游任务或者是微调过的或者是没有微调的。
从表格可以看出,单独使用CapFilt中的生产器Captioner或者单独使用过滤器Filter,都带来性能的提升。当着二者同时使用时,性能又进一步提升。 而且当模型和数据规模都变大时,使用CapFilt方法仍能带来性能的提升。
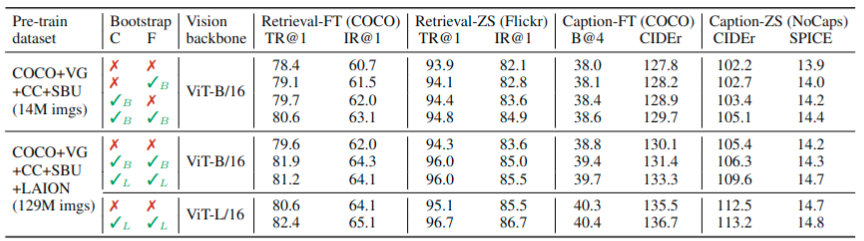
图4展示的是,图像及对应文本描述。红色表示被过滤器拒绝,蓝色表示接受。\(T_w\)表示来着网络的文本,\(T_s\)表示生成的文本。图示表明,不管是网络上的文本还是生成的文本,过滤器都具备筛选过滤掉图文不匹配的能力。

合成图片注释,多样性是关键。
CapFilt方法采用核取样方法来生成图片的注释文本。核取样方法是一种随机解码方法,每次生产的token从满足累积概率之和大于给定阈值如0.9的几个候选token中随机取样。表2是核方法与其它几种方法进行对比。尽管核取样方法产生更多的噪音,但是仍带来性能的提升。

实验对比
图文检索
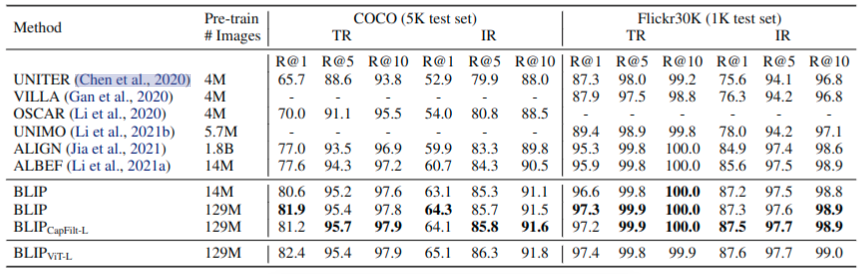
在COCO和Filckr30K这两个数据集上进行图到文检索和文到图检索。微调是在这两个数据集上,使用ITC和ITM损失函数进行训练。为了更快速推理,首先基于图文特征相似度,选择k个候选对象,然后基于逐对的ITM分数重排序。表5展示了,BLIP模型实现了显著的性能提升。表5展示了,即使没有微调,也在Flickr30K测试集上也超过之前的模型。
图片注释 Image Captioning
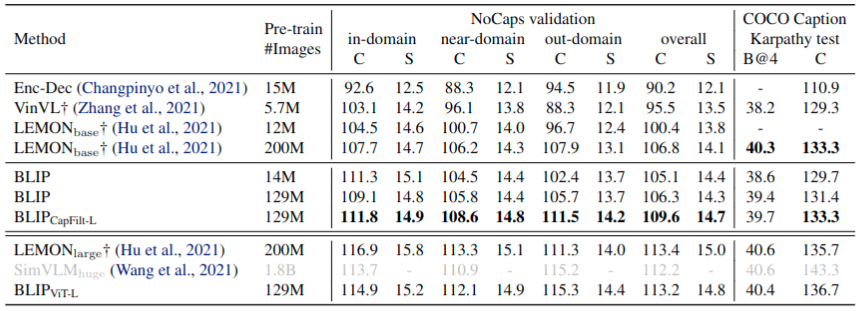
在NoCaps和COCO数据集上进行测试,模型是在COCO数据集上基于LM损失函数进行微调。论文在每张图片注释文本前添加"a picture of", 这样生成的结果会好些。表7中,展示了使用14M数据量训练的BLIP模型比其它方法基于相同体量数据集训练模型的生成性能更好。而使用129M数据集训练的BLIP模型与使用更大体量200M的LEMON模型的性能相当。这里的LEMON模型是要求有前置的计算量大的目标检测与高分辨率图片800x1333,而BLIP模型不要求目标检测和高分辨率图片(仅使用384x384),因此推理速度更快。
问题: NLP 生成的评价指标?
CIDEr, SPICE, BLEU
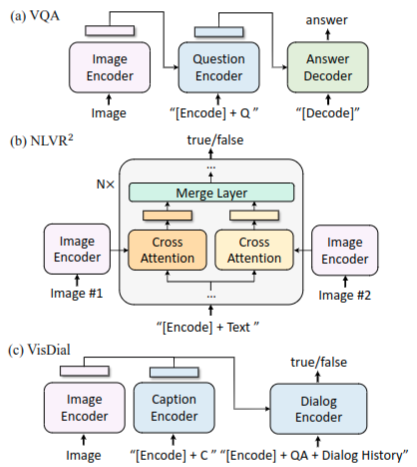
VQA
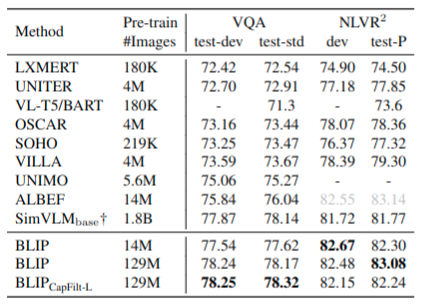
VQA要求模型在给定图片和问题,然后输出答案。代替之前将VQA看作多选项的分类问题,而此次将VQA设计为答案生成任务。任务设计参考图5(a),与原始预训练时候模块输入输出有些区别。图片和问题被编码为多模态表示,然后输入给Decoder,进而输出答案。参考表8,结果就是[效果好]☺
自然语言视觉推理 NLVR2
NLVR2任务要求模型推理一个语句是否正确描述一对图像。为了能对两张图片进行推理,如图5(B)所示设计,在基于图像的text encoder的交叉注意力层中,分别处理与两张图像的attention然后再进行融合。参考表8,结果就是[效果好]☺
视觉对话 VisDial
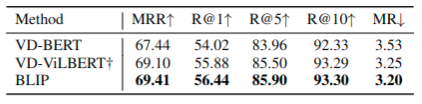
VisDial 以对话方式扩展VQA任务,模型不仅要基于图片问题对来预测答案,还要考虑到对话的历史和图片的注释信息,进行推理判断。任务设计参考图5(c)所示,聚合图片和注释的特征表示然后通过交叉注意力方式传递给对话encoder。给定图像文本注释信息,在对话中问问题,然后基于ITM损失函数判断对话中的答案是不是问题的答案。参考表9,结果就是[效果好]☺
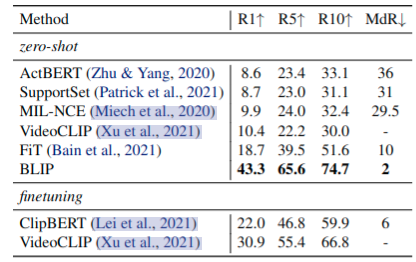
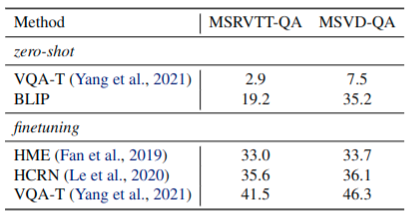
零样本迁移到视频语言任务
表 10 和 11 也展示出了本文提出图像文本模型对于视频语言任务上也具有很强的泛化能力。将在COCO和VQA数据集上训练的模型,零样本迁移到文本-视频检索和视频问答任务。为处理视频输入,统一从视频中取n帧然后提取帧特征,合并为特征序列。尽管有着数据域上的差异,而且此种方式丢弃了视频帧及时间序列信息,但结果就是[效果好]☺
参考
【1】Align before Fuse: Vision and Language Representation Learning with Momentum Distillation.