论文作者:Swalpa Kumar Roy, Ankur Deria, Chiranjibi Shah, et al.
论文发表年份:2023
模型简称:morphFormer
发表期刊:IEEE Transactions on Geoscience and Remote Sensing
Motivation
1)尽管CNN能够提取空间域中的上下文信息,但它们无法有效地提取序列信息,特别是长期和中期依赖关系。因此,它们在HSI分类中的性能可能会受到具有相似频光谱特征的影响。
2)Transformer擅长于表征光谱特征,但无法对局部语义元素进行建模或有效利用空间信息。
3)数学形态学(Mathematical morphology,MM)是一种基于拓扑、格理论、集合论和随机函数分析几何结构的理论。尽管MM已成功应用于RS中,用于基于EP或AP等技术提取空间信息,但SE无法捕获动态特征。如果将EP或AP替换为可学习的MM操作,则由此产生的网络可以更有能力学习细微的特征。传统的Transformer模型使用自注意力来突出最重要的特征。如果MM操作与Transformer相结合,则模型可能能够学习内在形状信息,并在自注意块中使用该信息来进行更好的特征提取,从而获得更高的分类精度。
Contribution
1) 我们提供了一种基于spectral–spatial morphFormer的新的可学习分类网络,该网络通过膨胀和侵蚀算子进行空间和光谱形态卷积。
2) 我们引入了一种新的注意力机制,用于将现有的 CLS tokens和从HSI patch tokens获得的信息有效地融合到一个新的token中,以进行形态特征融合。
3) 我们通过将所提出的网络与其他现有技术的方法进行比较,在四个公共HSI数据集上进行了实验。所获得的结果表明了所提出的方法的有效性。
Method
1) Convolutional Networks for Feature Learning
我们提出的模型利用Conv3D和HetConv2D从HSI中提取鲁棒和判别特征。原始数据的subcubes数据XHSI(维度为11×11×B)中,这些subcubes数据被重塑为(1×11×11 X B),并用作具有内核大小(3×3×9)和填充(1×1×0)的Conv3D层的输入。使用填充,使得输出图像的空间大小与输入图像的空间尺寸相同。HetConv2D区块遵循Conv3D层,由两个并行工作的Conv2D层组成。其中一个Conv2D层用组卷积,另一个用逐点卷积。HetConv2D利用两个不同大小的核来提取多尺度信息。
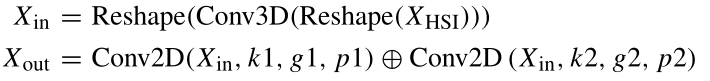
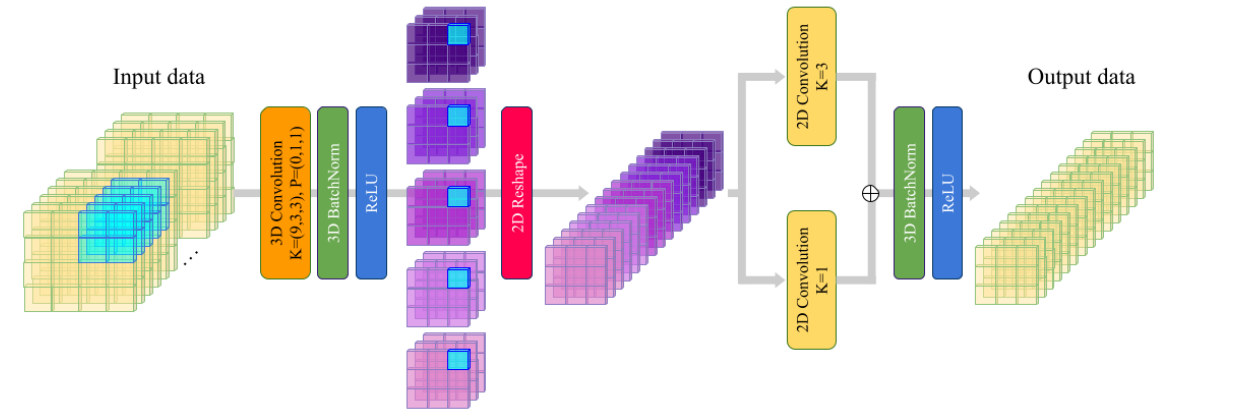
2) Image Tokenization and Position Embedding
Tokenization过程:先将卷积映射的特征flattening为121x64,然后再用两个可学习的矩阵分别与展平的特征作矩阵乘法,最后再将两个矩阵作矩阵乘法得到Xpatch∈Rn×64
形状为(1×64)的patch tokens通过flattening形状为[(11×11)×64]的HSIsubcubes获得:![]() , 其中T(·)是转置函数,Xflat∈R121×64。
, 其中T(·)是转置函数,Xflat∈R121×64。
tokenization操作用于从121个patches中选择n个,如下所示![]() ,
,![]() .其中WaH∈R64×n,WbH∈R64×64,XWa∈Rn×121,XWb∈R121×64
.其中WaH∈R64×n,WbH∈R64×64,XWa∈Rn×121,XWb∈R121×64
tokenization操作使用两个可学习的权重来提取关键特征:![]() , 其中Xpatch∈Rn×64
, 其中Xpatch∈Rn×64
CLS令牌(Xcls)是一个可学习的张量,它是随机初始化的。为了简化头部尺寸的计算,使用了64的尺寸:![]()
最后加入位置编码并使用Dropout操作:![]() , 其中DP表示值为0.1的丢弃层,PE表示可学习的位置编码。
, 其中DP表示值为0.1的丢弃层,PE表示可学习的位置编码。
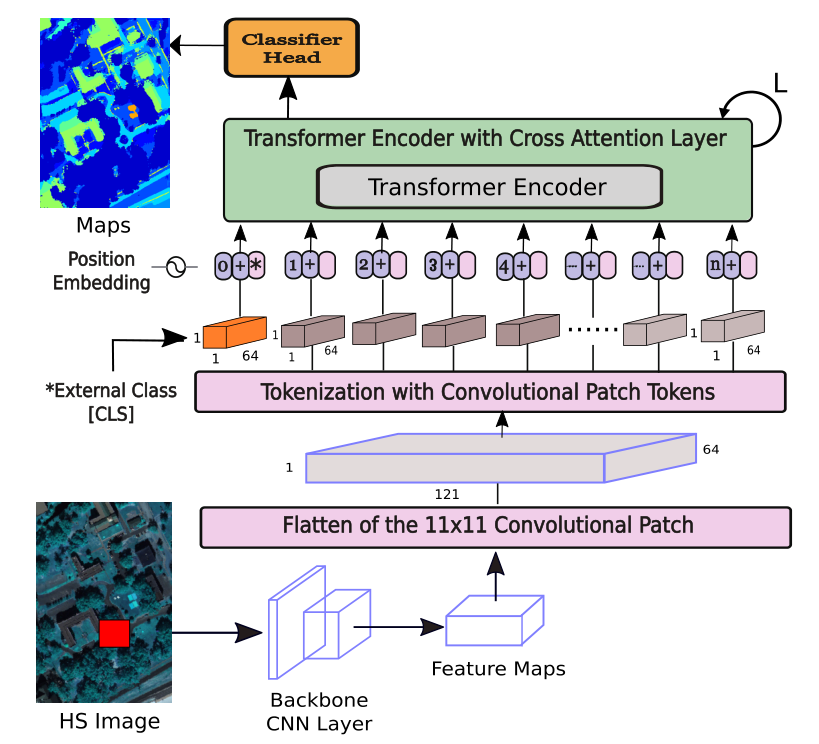
3) Spectral and Spatial Morphological Convolutions
MM是一种强大的技术,用于表征图像中物体的内在形状、结构和大小。本文提出的光谱和空间形态网络是基于膨胀和侵蚀操作设计的,SE大小为(s×s)。通过将输入的HSI patch tokens 与SE相结合,选择局部邻域中具有最大值的像素,来产生放大图像。作为膨胀过程的结果,HSI输入 patch token 的显著的对象的边界被加宽。换句话说,内核的大小影响HSI patch token 的各个区域的纹理的大小。膨胀过程由⊞表示,可以由以下方程表示:
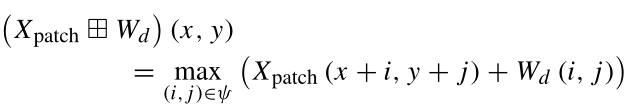
其中 ψ={(i,j)|i∈{1,2,3,…,s};j∈{1,2,3,…,s}} 表示核的元素,Wd表示用于膨胀操作的SE。关于侵蚀操作,与SE的卷积的输出选择局部邻域中具有最小值的像素。该操作减少了HSI补丁令牌中背景对象的形状(与膨胀相反)。侵蚀可以消除微小的细节并扩大孔洞,使它们在不同的纹理区域相互区分。设Xpatch∈Rk×k是空间大小为k×k的输入HSI补丁令牌,并设⊟表示形态侵蚀操作。侵蚀操作可以定义为:
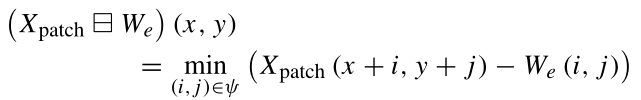
其中 ψ={(i,j)|i∈{1,2,3,…,s};j∈{1,2,3,…,s}} 表示核的元素,We表示用于腐蚀操作的SE。
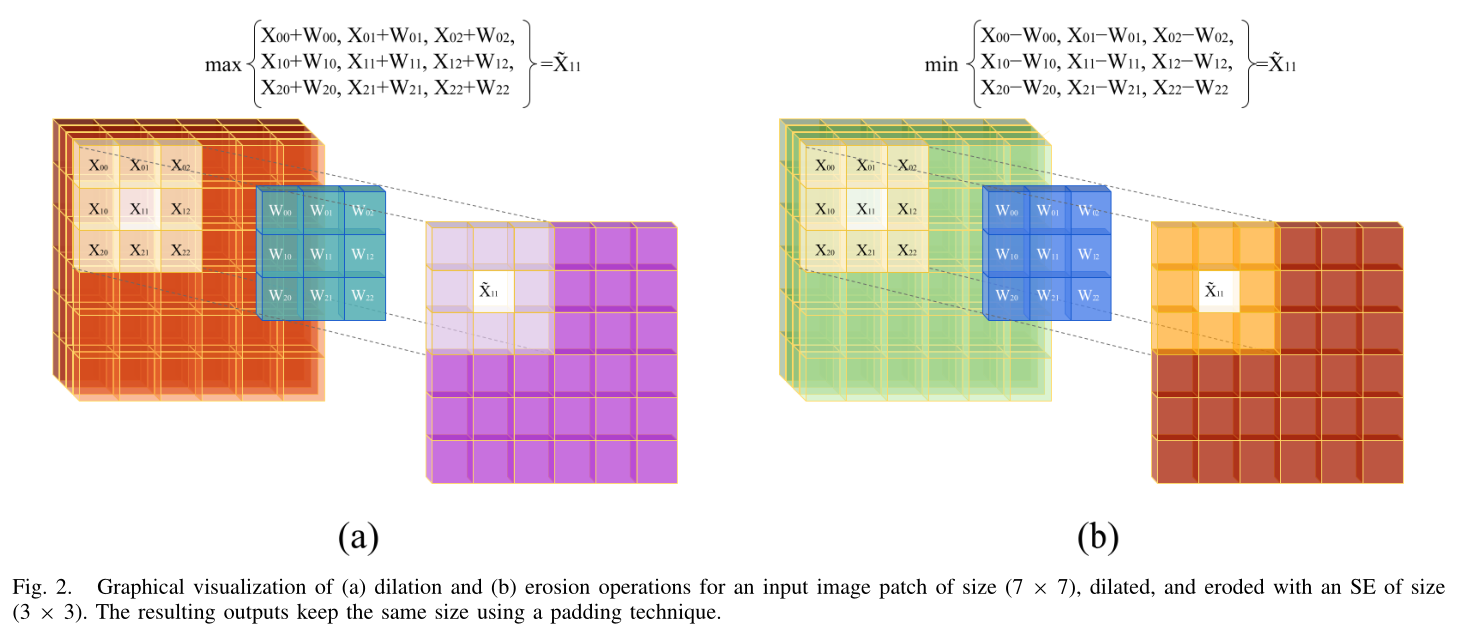
为了从HSI patch token 中获得形态形状特征,使用具有原始操作(例如,扩张和侵蚀)的空间形态块(SpatialMorph)。空间形态块包括膨胀和侵蚀的平行分支,然后是它们各自的卷积运算,最后,两个分支的结果以元素方式融合。由于形态学运算是非线性的,它们可能会在学习到的特征中产生差异。为了规范化那些学习到的特征,使用了卷积运算。整个SpatialMorph块可以被描述为:
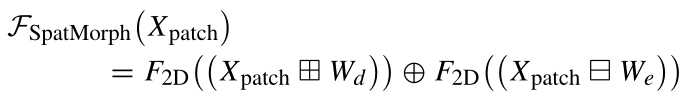
其中Wd和We是(3×3)核的权重,F2D是表示利用2-D卷积获得的膨胀和侵蚀特征图之间的线性组合的函数。为了从HSI patch token 中获得形态学光谱特征,使用了光谱形态学(SpectralMorph)块。可以使用以下等式来描述该块:
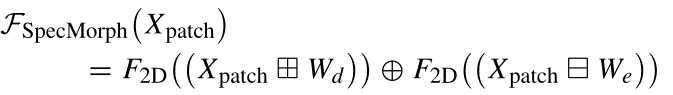
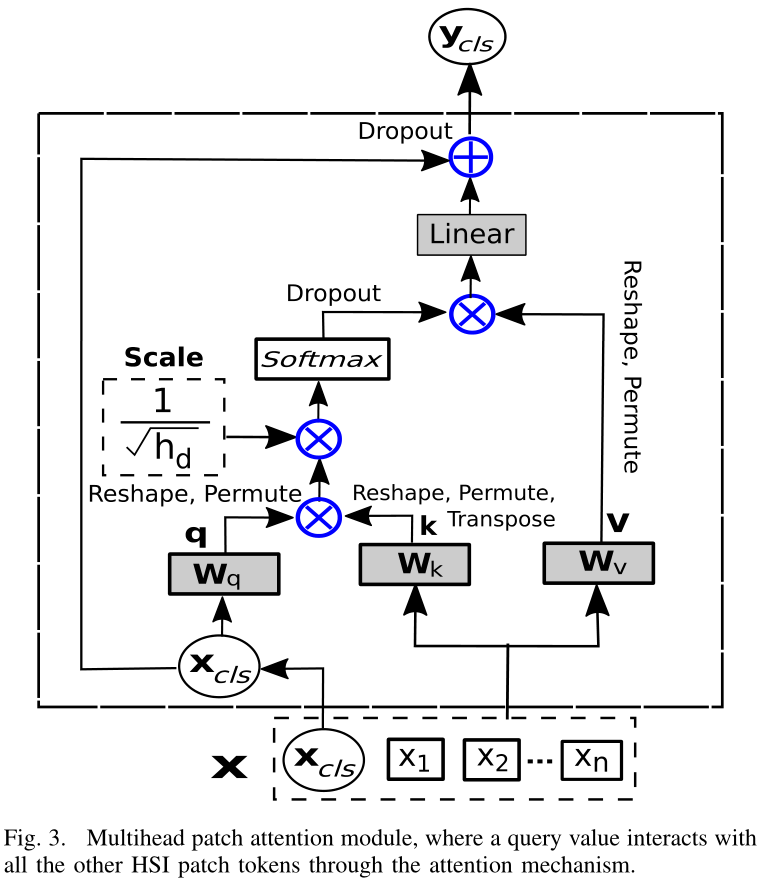
4)Patch Attention Using Morphological Feature Fusion
CLS(Xcls)token使用HSIpatch tokens用于在彼此之间交换信息,以提供整个HSI补丁的抽象表示。
整个操作在Transformer编码器的块中执行,其中每个Transformer块由光谱和空间形态特征提取块和残差多头交叉注意块组成。
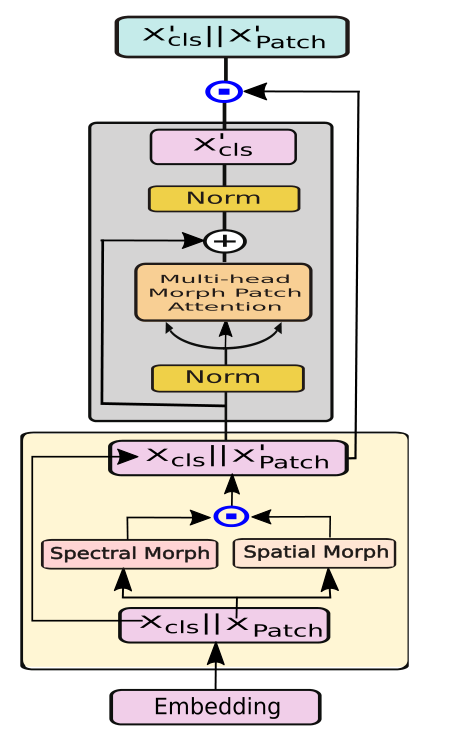
Spectral Morph和Spatial Morph两层的输出以通道形式(X′patch)与Xcls级联,以生成整个形态块的最终输出。来自光谱和空间形态块的输出通道是输入Xpatch的一半,因此,在将两者concatenate之后,通道的数量变得等于Xpatch。整个形态块可以总结如下:

随后输入后续注意力模块,使用值为0.1的Dropout层(DP),然后是应用于qkv操作的最终输出的线性投影层(Wl∈R64×64)。MorphAT模块(在使用多个头时)成为多个头形态注意模块,并且可以表示为MMorphAT:
![]()
![]()
对于给定的X′k−1,MMorphAT模块的输出X′cls,其中k是第k个变换器编码器块,可以表示为:
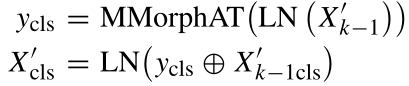
其中X′cls∈R1×64。然后将该输出X′cls与X′patch Concat,以产生特定Transformer编码器块的最终输出,可以定义为:
![]()
所提出的模型使用了八个头。最后,从Transformer编码器块(Xk)的输出中提取CLS token,并通过分类器头从CLS token中获得最终分类结果。
Experiment
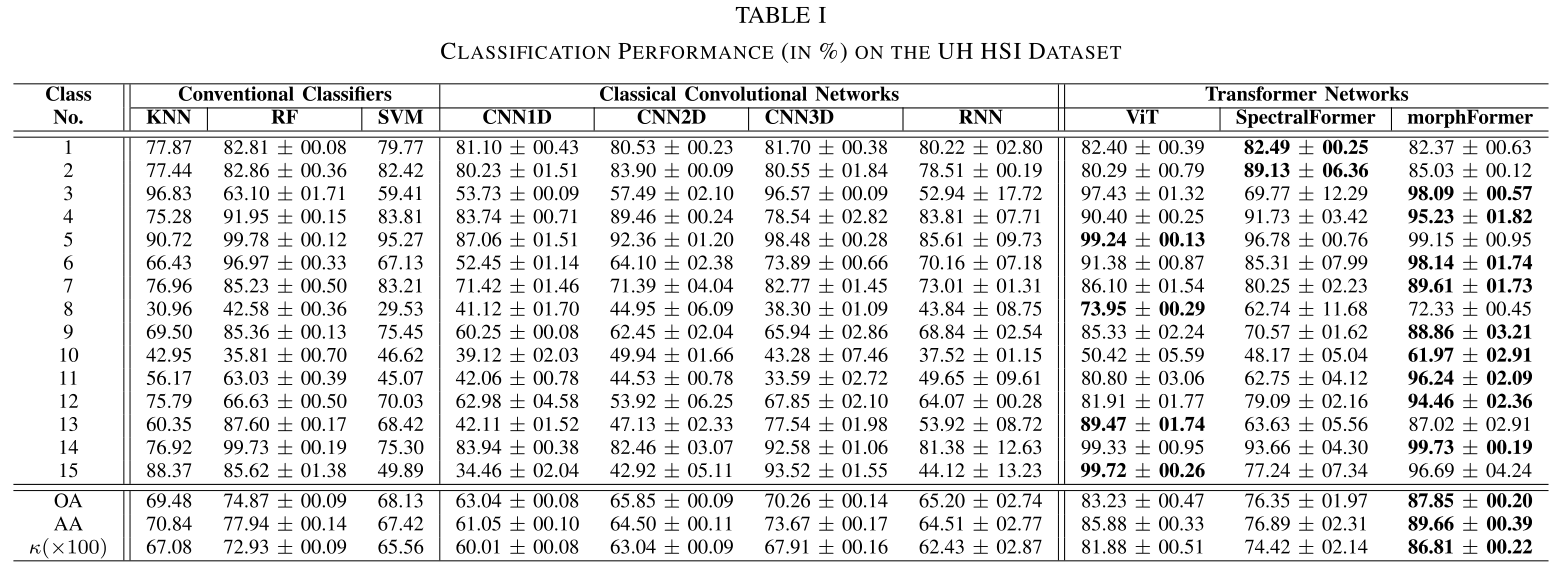
Datasets: University of Houston (UH), the University of Southern Mississippi Gulfpark (MUUFL), and the cities of Trento and Augsburg.
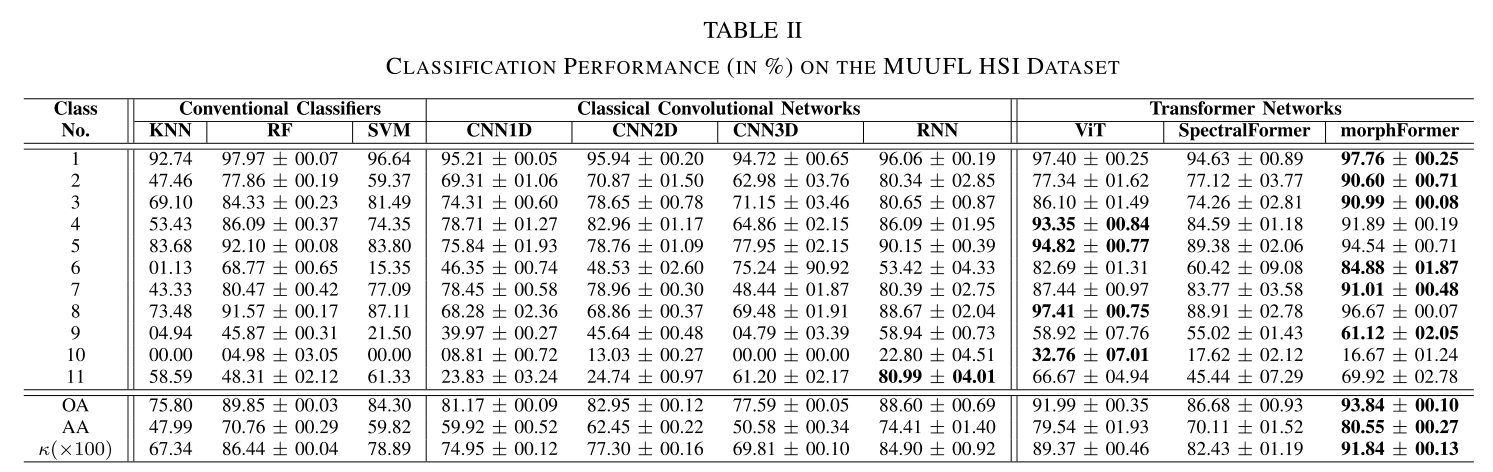
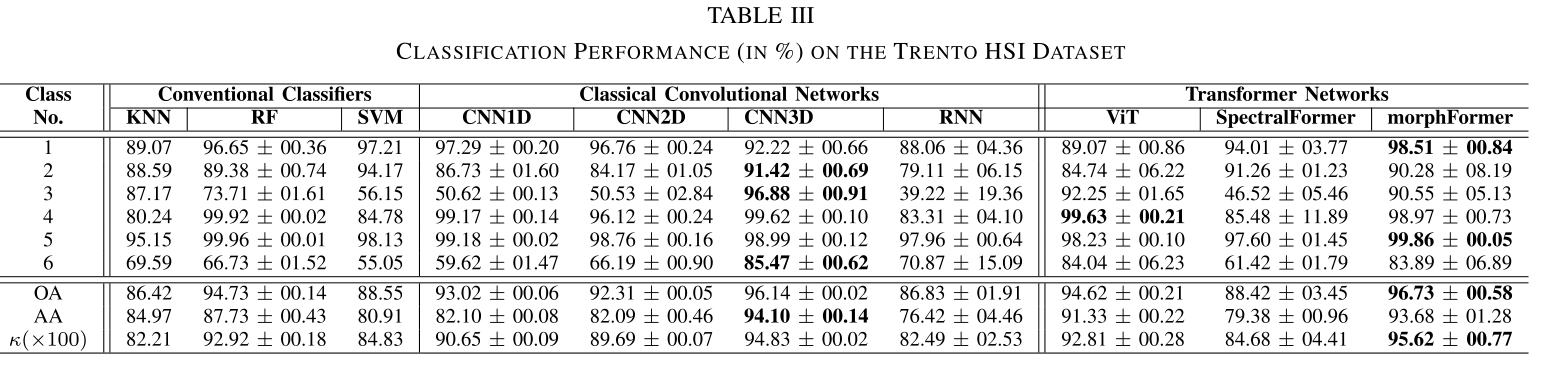
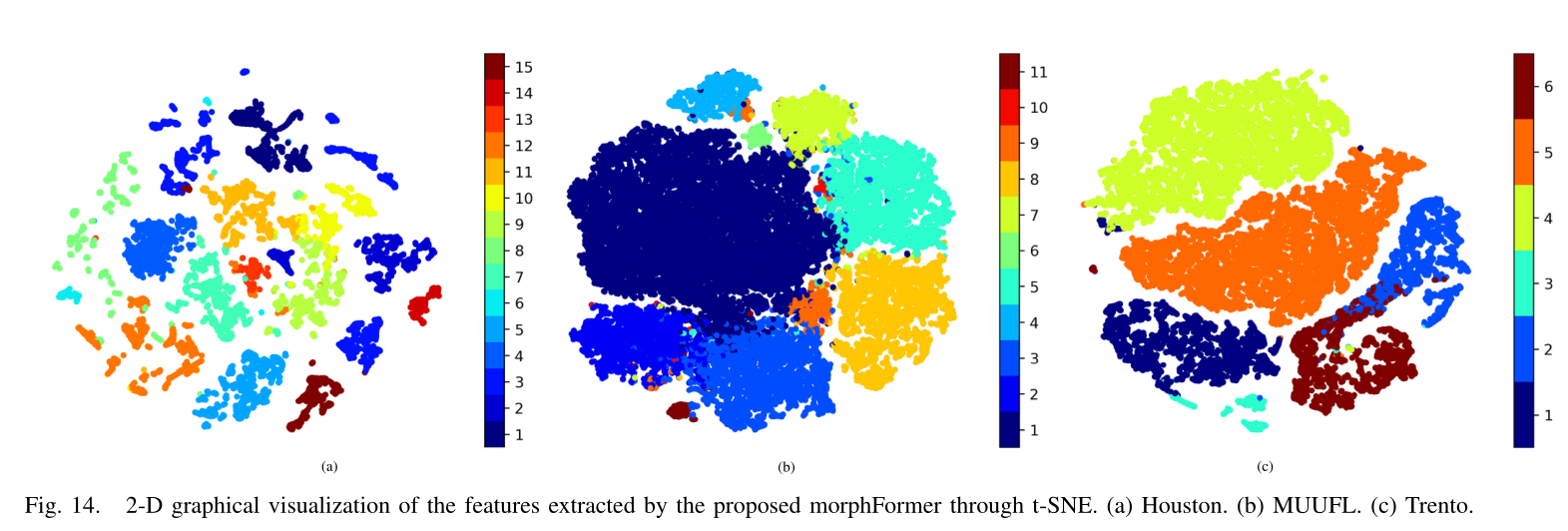
Conclusion
我们提出了一种新的用于HSI数据分类的morphFormer网络,该网络基于光谱和空间形态学卷积。尽管融合注意力和形态学特征并不简单,但与标准卷积模型和最近开发的transformer模型相比,我们的方法可以成功地将注意力机制与形态学操作相结合,并提供卓越的分类性能。我们的morphFormer有潜力在EO和RS的许多不同分类任务中表现出色。这是因为它除了能够应用多头自注意机制外,还能够应用可学习的形态学运算。在我们未来的工作中,将使用morphFormer研究一种基于通用对抗性网络(GAN)的方法。此外,激光雷达处理问题也将使用基于morphFormer的方法来解决。
- Classification Morphological Hyperspectral Transformer Attentionclassification morphological hyperspectral transformer cross-attention classification multi-scale transformer transformer attention need all crossformer cross-scale transformer attention transformer attention vision论文 self-attention transformer attention网络 轻量transformer标记attention transformer attention mlps bert morphological hyperspectral