写在前面
学习一个软件最好的方法就是啃它的官方文档。本着自己学习、分享他人的态度,分享官方文档的中文教程。软件可能随时更新,建议配合官方文档一起阅读。推荐先按顺序阅读往期内容:
文献篇:
1.文献阅读:使用 Tangram 进行空间解析单细胞转录组的深度学习和比对
::: block-1
目录
- 1 安装
- 2 下载数据
- 3 导入空间组数据
- 4 导入单细胞数据
- 5 准备映射
- 6 映射
- 7 分析
- 8 留一交叉验证(LOOCV)
:::
官网教程:
https://tangram-sc.readthedocs.io/en/latest/tutorial_link.html
1 安装
- 确保
tangram-sc已通过pip install tangram-sc安装。 - 否则,编辑并取消注释以
sys.path开头的指定 Tangram 文件夹的行。 - Python 环境需要安装
environment.yml中列出的包。
import os, sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import scanpy as sc
import torch
sys.path.append('./') # uncomment for local import
import tangram as tg
%load_ext autoreload
%autoreload 2
%matplotlib inline
tg.__version__
2 下载数据
- 如果你安装了
wget,则可以运行以下代码自动下载并解压数据。
# Skip this cells if data are already downloaded
!wget https://storage.googleapis.com/tommaso-brain-data/tangram_demo/mop_sn_tutorial.h5ad.gz -O data/mop_sn_tutorial.h5ad.gz
!wget https://storage.googleapis.com/tommaso-brain-data/tangram_demo/slideseq_MOp_1217.h5ad.gz -O data/slideseq_MOp_1217.h5ad.gz
!wget https://storage.googleapis.com/tommaso-brain-data/tangram_demo/MOp_markers.csv -O data/MOp_markers.csv
!gunzip -f data/mop_sn_tutorial.h5ad.gz
!gunzip -f data/slideseq_MOp_1217.h5ad.gz
- 如果您没有安装
wget,请参考官网教程手动下载数据:- 从成年小鼠皮质收集的 snRNA-seq 数据集:10Xv3 MOp
- 对于空间数据,我们将使用 Slide-seq2 data 的一个冠状切片(adult mouse brain; MOp area)。
- 我们将通过文献中发现的数百个 marker genes 来绘制它们。
- 所有数据集都需要解压缩:生成的
h5ad和csv文件应放置在数据文件夹中。
3 导入空间组数据
- 空间数据需要组织为一个 voxel-by-gene 矩阵。这里,Slide-seq 数据包含 9852 个空间 voxels,每个空间 voxels 测量 24518 个基因。
path = os.path.join('./data/without', 'slideseq_MOp_1217.h5ad')
ad_sp = sc.read_h5ad(path)
ad_sp
## AnnData object with n_obs × n_vars = 9852 × 24518
## obs: 'orig.ident', 'nCount_RNA', 'nFeature_RNA', 'x', 'y'
- voxel 坐标保存在
obs.x和obs.y字段中,我们可以使用它们来可视化空间 ROI。每个“点”都是 10um voxel 的中心。
xs = ad_sp.obs.x.values
ys = ad_sp.obs.y.values
plt.axis('off')
plt.scatter(xs, ys, s=.7);
plt.gca().invert_yaxis()

4 导入单细胞数据
- 对于单细胞数据,我们通常指的是 scRNAseq 或 snRNAseq。
- 我们首先 mapping MOp 10Xv3 数据集,其中包含从初级运动皮层后部区域收集的单核。
- 它们是大约 26k 个具有 28k 个基因的 profiled 细胞。
path = os.path.join('data/without','mop_sn_tutorial.h5ad')
ad_sc = sc.read_h5ad(path)
ad_sc
## AnnData object with n_obs × n_vars = 26431 × 27742
## obs: 'QC', 'batch', 'class_color', 'class_id', 'class_label', 'cluster_color', 'cluster_labels', 'dataset', 'date', 'ident', 'individual', 'nCount_RNA', 'nFeature_RNA', 'nGene', 'nUMI', 'project', 'region', 'species', 'subclass_id', 'subclass_label'
## layers: 'logcounts'
- 通常,我们使用 raw count 形式的数据,特别是当空间数据也采用 raw count 形式时。
- 如果数据采用整数格式,则可能意味着它们是原始计数。
np.unique(ad_sc.X.toarray()[0, :])
- 在这里,我们只进行一些轻微的预处理作为库大小校正(在 scanpy 中,通过
sc.pp.normalize),将每个细胞内的计数标准化为固定数字。 - 有时,我们会应用更复杂的预处理方法,例如批量校正,尽管映射对于原始数据效果很好。
- 理想情况下,单细胞和空间数据集应表现出尽可能相似的信号,并且应最终确定预处理管道以协调信号。
sc.pp.normalize_total(ad_sc)
- 在单细胞数据中添加注释是个好主意,因为在我们 map 后它们将被投影到空间上。
- 在这种情况下,细胞类型在
subclass_label字段中进行注释,我们为其绘制细胞计数。 - 请注意,两个数据集中的细胞类型比例应该相似:例如,如果
Meis在 snRNA-seq 中是一种罕见的细胞类型,那么即使在空间数据中,它也应该是一种罕见的细胞类型。
ad_sc.obs.subclass_label.value_counts()
5 准备映射
- Tangram 学习单细胞数据的空间对齐,以便对齐的单细胞数据的基因表达与空间数据的基因表达尽可能相似。
- 在此过程中,Tangram 仅查看用户指定的子集基因,称为训练基因。
- 训练基因的选择是 mapping 的一个微妙步骤:它们需要承载有趣的信号并进行高质量的测量。
- 通常,一个好的开始是选择 100-1000 个 top marker genes,在不同细胞类型之间均匀分层。有时,我们还使用整个转录组,或使用不同的训练基因组执行不同的映射,以查看结果变化有多大。
- 对于本例,我们选择了 MOp 区域的 253 个 marker genes,这些基因是在另一项研究中策划的。
df_genes = pd.read_csv('data/without/MOp_markers.csv', index_col=0)
markers = np.reshape(df_genes.values, (-1, ))
markers = list(markers)
len(markers)
## 253
- 现在,我们需要通过在两个 AnnData 结构的
uns字典中创建training_genes字段来准备用于 mapping 的数据集。 - 该
training_genes字段包含训练基因列表中的基因子集。稍后将在映射函数中使用该字段来创建训练数据集。 - 此外,数据集中的基因顺序需要相同。这是因为 Tangram maps 只使用基因表达,所以每个矩阵中的第 j-th 列必须对应于相同的基因。
- 如果某个基因的计数在其中一个数据集中全部为零,则该基因将从训练基因中删除。
- 此任务由辅助函数
pp_adata执行。 - 在
pp_adatas函数中,基因名称被转换为小写,以消除不一致的大写。如果不需要,可以设置参数gene_to_lowercase=False。
tg.pp_adatas(ad_sc, ad_sp, genes=markers)
- 您现在会注意到,这两个数据集现在包含 249 个基因,但提供了 253 个标记。
- 这是因为标记基因需要由两个数据集共享。如果一个基因缺失,
pp_adata就会将其删除。 - 最后,下面的
assert行是确保uns中training_genes字段中的基因在两个AnData中实际排序的好方法。
ad_sc
## AnnData object with n_obs × n_vars = 26431 × 26496
## obs: 'QC', 'batch', 'class_color', 'class_id', 'class_label', 'cluster_color', 'cluster_labels', 'dataset', 'date', 'ident', 'individual', 'nCount_RNA', 'nFeature_RNA', 'nGene', 'nUMI', 'project', 'region', 'species', 'subclass_id', 'subclass_label'
## var: 'n_cells'
## uns: 'training_genes', 'overlap_genes'
## layers: 'logcounts'
ad_sp
## AnnData object with n_obs × n_vars = 9852 × 20864
## obs: 'orig.ident', 'nCount_RNA', 'nFeature_RNA', 'x', 'y', 'uniform_density', 'rna_count_based_density'
## var: 'n_cells'
## uns: 'training_genes', 'overlap_genes'
assert ad_sc.uns['training_genes'] == ad_sp.uns['training_genes']
6 映射
- 我们现在可以训练模型(把单细胞的数据映射到空间上)。
- 应在分数稳定后中断映射,这可以通过传递
num_epochs参数来控制。 - 该分数衡量映射细胞的基因表达与空间数据之间的相似性:分数越高意味着映射越好。
- 请注意,即使 Tangram 收敛到较低的分数(典型的情况是当空间数据非常稀疏时),我们也获得了极好的映射:我们使用分数只是为了评估收敛性。
- 如果您使用 GPU 运行 Tangram,请取消对
device=cuda:0的注释,并对device=cpu行进行注释。在 MacBook Pro 2018 上,运行大约需要 1 小时。在 P100 GPU 上,它应该在几分钟内完成。
ad_map = tg.map_cells_to_space(
adata_sc=ad_sc,
adata_sp=ad_sp,
#device='cpu',
device='cuda:0',
)
- 映射结果存储在返回的
AnData结构中,另存为ad_map,结构如下:- cell-by-spot 矩阵
X包含 cell i 在 spot j 的概率。 obsdataframe 包含单细胞的 metadata。vardataframe 包含空间组数据的 metadata。uns字典包含具有关于训练基因的各种信息的 dataframe(保存为train_genes_df)。
- cell-by-spot 矩阵
- 我们现在可以保存映射结果以进行后期分析。
7 分析
- 将单细胞数据映射到空间上最常见的应用程序是将细胞类型注释 transfer 到空间上。
- 这是通过
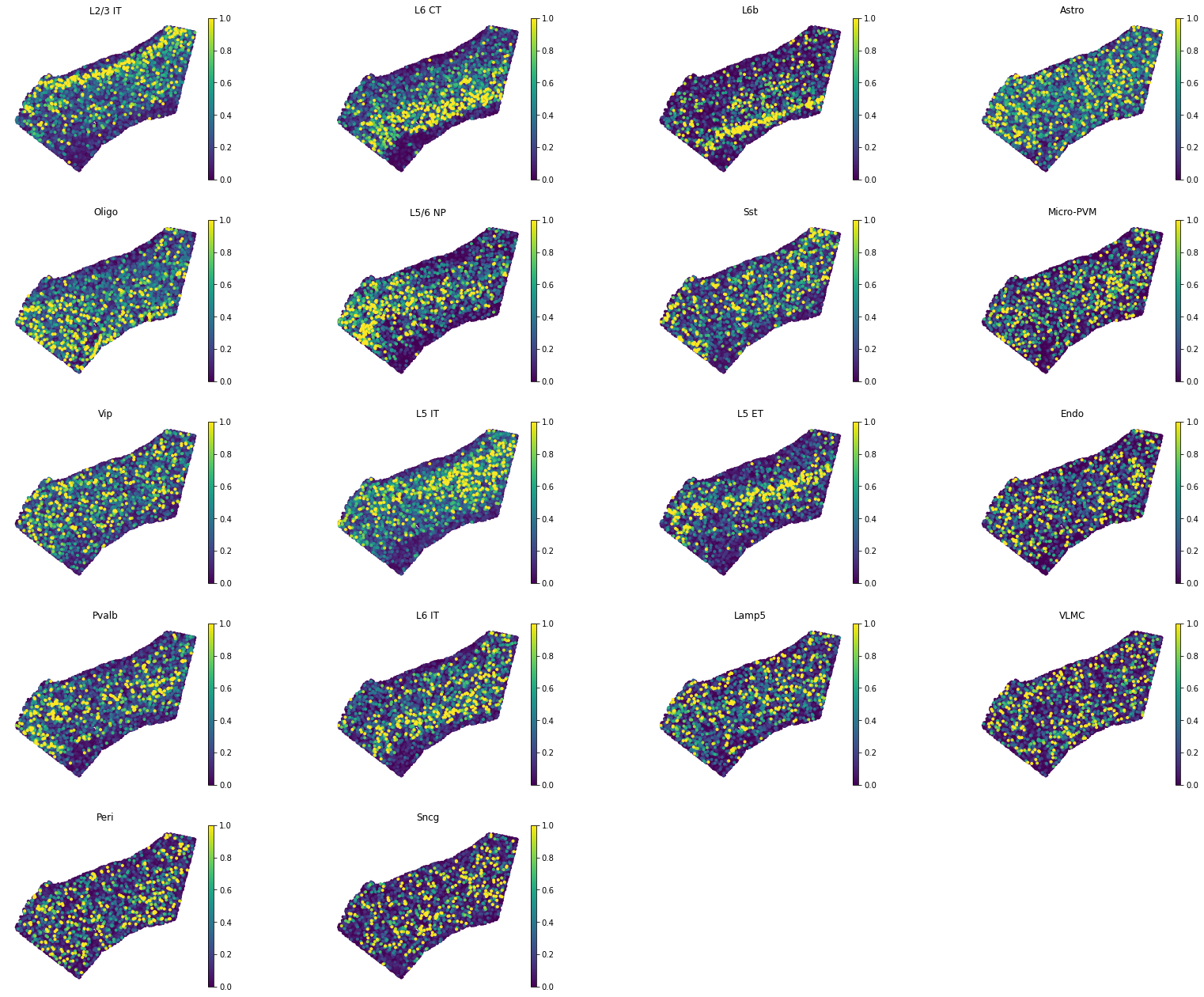
plot_cell_anotation实现的,它可视化了obsdataframe 中注释的空间概率映射(此处为subclass_label字段)。您可以将robust参数设置为True,同时将perc参数设置为 colormap 的范围,这将有助于删除异常值。 - 下图恢复了兴奋性神经元的皮质层和神经胶质细胞的稀疏模式。皮质的边界由 layer 6b (细胞类型 L6b)定义,并且发现少突胶质细胞集中在皮质下区域,正如预期的那样。
- 然而,VLMC 细胞类型模式似乎并不正确:VLMC 细胞聚集在第一皮质层,而此处在 ROI 中稀疏。这通常意味着(1)我们在训练基因中没有为 VLMC 细胞使用良好的标记基因(2)当前的标记基因在空间数据中非常稀疏,因此它们不包含良好的映射信号。
tg.project_cell_annotations(ad_map, ad_sp, annotation='subclass_label')
annotation_list = list(pd.unique(ad_sc.obs['subclass_label']))
tg.plot_cell_annotation_sc(ad_sp, annotation_list,x='x', y='y',spot_size= 60, scale_factor=0.1, perc=0.001)
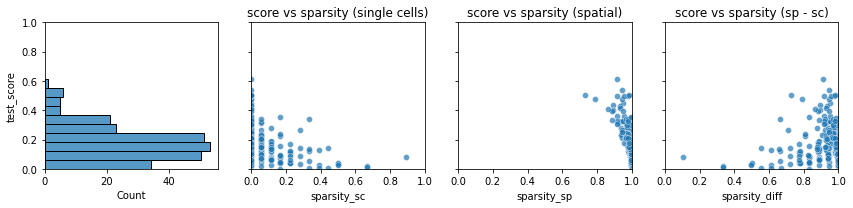
- 让我们尝试更深入地了解这个映射有多好。一个好帮手是
plot_training_scores,它为我们提供了四个面板:- 第一个面板是每个训练基因的相似性得分的直方图。大多数基因都具有非常高的相似性 (> 0.9),尽管其中很少有得分低于 0.5。我们想了解为什么这些基因的得分较低。
- 第二张图显示,基因的训练得分(y 轴)与 snRNA-seq 数据中该基因的稀疏性(x 轴)之间存在紧密的相关性。每个点都是一个训练基因。趋势是基因越稀疏,得分越高:这种情况通常会发生,因为非常稀疏的基因更容易映射,因为通过在正确的位置放置一些 "jackpot cells" 来匹配它们的模式。
- 第三个面板与第二个面板类似,但包含空间数据的基因稀疏性。空间数据通常比单细胞数据更加稀疏,这种差异通常是造成低质量映射的原因。
- 在最后一个面板中,我们将训练分数显示为数据集之间稀疏度差异的函数。对于具有相当稀疏性的基因,映射的基因表达与空间数据中的基因表达非常相似。然而,如果某个基因在一个数据集中(通常是空间数据)非常稀疏,但在其他数据集中则不然,则映射分数会较低。出现这种情况是因为 Tangram 无法正确匹配基因模式,因为数据集之间的丢失数量不一致。
tg.plot_training_scores(ad_map, bins=10, alpha=.5)

- 尽管上图为我们提供了单基因水平的分数摘要,但我们需要知道哪些基因的分数较低。
- 这些信息可以从映射结果的 dataframe
.uns['train_genes_df']访问;这是用于构建上面四个图的 dataframe。 - 我们想要检查低分映射的训练基因的基因表达,以了解映射的质量。
- 首先,我们需要使用映射的单细胞生成“新的空间数据”:这是通过
project_genes完成的。 - 该函数接受映射 (
adata_map) 和相应的单细胞数据 (adata_sc) 作为输入。 - 结果是一个 voxel-by-gene
AnnData,形式上类似于ad_sp,但包含来自映射的单细胞数据而不是 Slide-seq 的基因表达。
ad_ge = tg.project_genes(adata_map=ad_map, adata_sc=ad_sc)
ad_ge
## AnnData object with n_obs × n_vars = 9852 × 26496
## obs: 'orig.ident', 'nCount_RNA', 'nFeature_RNA', 'x', 'y', 'uniform_density', 'rna_count_based_density'
## var: 'n_cells', 'sparsity', 'is_training'
## uns: 'training_genes', 'overlap_genes'
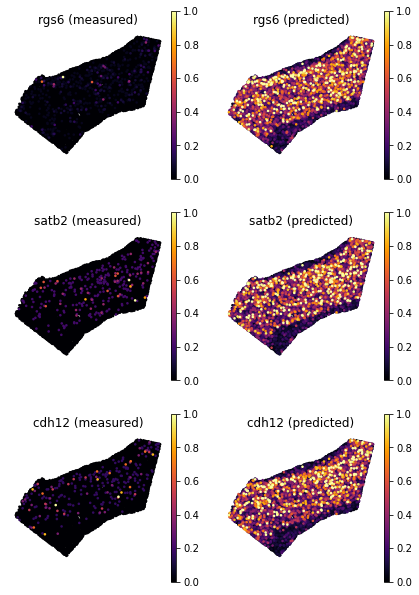
- 我们现在选择一些低分映射的训练基因。
genes = ['rgs6', 'satb2', 'cdh12']
ad_map.uns['train_genes_df'].loc[genes]
## train_score sparsity_sc sparsity_sp sparsity_diff
## rgs6 0.462164 0.305172 0.941941 0.636769
## satb2 0.501113 0.455904 0.969549 0.513645
## cdh12 0.417188 0.384889 0.972594 0.587705
- 为了可视化基因模式,我们使用辅助程序
plot_genes。该函数接受两个 voxel-by-geneAnnData:实际空间数据 (adata_measured) 和 Tangram 空间预测 (adata_predicted)。该函数从基因上的两个空间AnnData返回基因表达图。 - 正如预期的那样,尽管捕获了主要模式,但预测的基因表达不太稀疏。对于这些基因,我们更信任映射的基因模式,因为 Tangram 通过在空间中对齐稀疏数据来“纠正”基因表达。
tg.plot_genes_sc(genes, adata_measured=ad_sp, adata_predicted=ad_ge, spot_size=50,scale_factor=0.1, perc=0.02, return_figure=False)
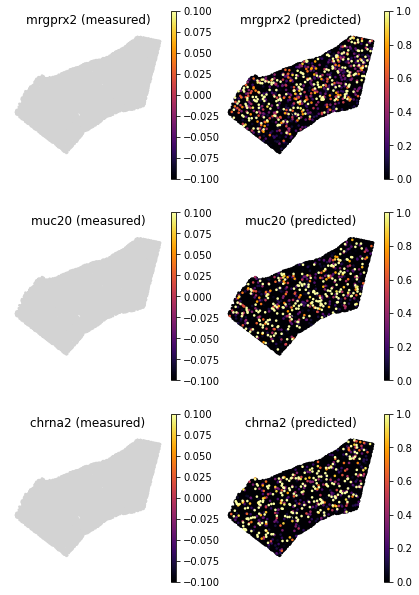
- 一个更强有力的例子是在空间数据中未检测到但在单细胞数据中检测到的基因。在使用
pp_adatas函数进行训练之前将它们删除。但 Tangram 仍然可以产生对空间模式的洞察。
genes=['mrgprx2', 'muc20', 'chrna2']
tg.plot_genes_sc(genes, adata_measured=ad_sp, adata_predicted=ad_ge, spot_size=50, scale_factor=0.1, perc=0.02, return_figure=False)
- 到目前为止,我们只检查了用于对齐数据的基因(训练基因),但映射的单细胞数据
ad_ge包含整个转录组。其中包括超过 26k 个测试基因。
(ad_ge.var.is_training == False).sum()
## 26247
- 我们可以使用
plot_genes来检查非训练基因的基因表达。这是一个重要的步骤,因为基因表达的预测是我们验证映射的方式。 - 在此之前,可以方便地计算所有基因的相似性分数,这可以通过
compare_spatial_geneexp来完成。该函数接受两个空间AnnData(即 voxel-by-gene),并返回一个包含所有基因相似度分数的 dataframe。训练基因由布尔字段is_training标记。 - 如果我们还将单细胞
AnnData传递给Compare_spatial_geneexp函数,如下所示,则会返回带有附加稀疏列的 dataframe - sparsity_sc(单细胞数据稀疏度)和 sparsity_diff (空间数据稀疏度 - 单细胞数据稀疏度)。如果我们想稍后使用从compare_spatial_geneexp函数返回的 datafrme 调用plot_test_scores函数,这是必需的。
df_all_genes = tg.compare_spatial_geneexp(ad_ge, ad_sp, ad_sc)
df_all_genes
- 下图总结了测试基因在单基因水平上的得分
tg.plot_auc(df_all_genes)
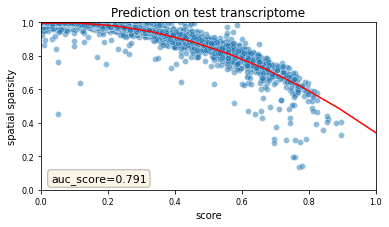
- 让我们绘制测试基因的分数,看看它们与训练基因的比较如何。按照前面图中的策略,我们将分数可视化为空间数据稀疏性的函数。
- (我们还没有将此调用包装到函数中)。
- 同样,空间数据中稀疏基因的预测得分较低,这是由于空间数据中存在丢失。
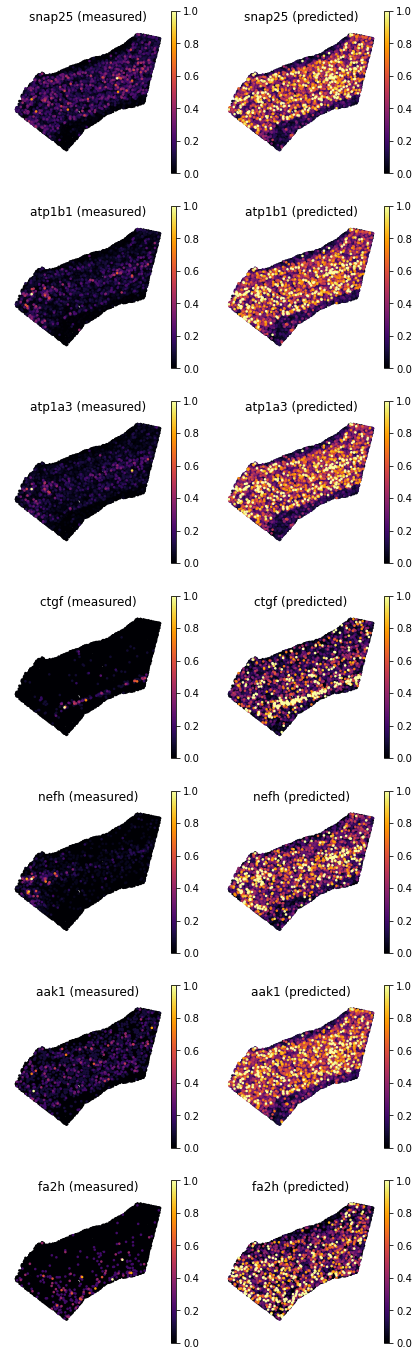
- 让我们选择一些具有不同分数的测试基因,并将预测与测量的基因表达进行比较。
genes = ['snap25', 'atp1b1', 'atp1a3', 'ctgf', 'nefh', 'aak1', 'fa2h', ]
df_all_genes.loc[genes]
- 我们可以再次使用
plot_genes来可视化基因模式。 - 有趣的是,基因
Atp1b1或Apt1a3的一致性似乎不如Ctgf和Nefh好,尽管前基因的得分较高。这是因为即使后面的基因模式定位正确,它们的表达值也没有很好的相关性(例如,在 Ctgf 中,“亮黄点”位于第 6b 层的不同部分)。相比之下,对于 Atpb1,尽管空间数据中的整体基因表达更加暗淡,但基因表达模式很大程度上恢复了。
tg.plot_genes_sc(genes, adata_measured=ad_sp, adata_predicted=ad_ge, spot_size=50,scale_factor=0.1, perc=0.02, return_figure=False)
8 留一交叉验证(LOOCV)
- 如果基因数量较少,Tangram 支持 Leave-One-Out cross validation (LOOCV) 来评估映射性能。
- Tangram 支持的 LOOCV:
- 假设数据集中的基因数量为 N。
- LOOCV 将迭代并映射基因数据集 N 次。
- 每次它都会保留一个基因作为测试基因(1 test gene)并训练其余的所有基因(N-1 training genes)。
- 所有训练完成后,将计算平均测试/训练分数以评估映射性能。
- 假设我们拥有的所有基因都是上例中的训练基因。在这里,我们演示了 cluster level 的 LOOCV 映射。
- 重新启动内核并加载单细胞、空间和基因标记数据
- 运行
pp_adatas准备映射数据
import os, sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scanpy as sc
import torch
import tangram as tg
path = os.path.join('./data/without', 'slideseq_MOp_1217.h5ad')
ad_sp = sc.read_h5ad(path)
path = os.path.join('data/without','mop_sn_tutorial.h5ad')
ad_sc = sc.read_h5ad(path)
sc.pp.normalize_total(ad_sc)
df_genes = pd.read_csv('data/without/MOp_markers.csv', index_col=0)
markers = np.reshape(df_genes.values, (-1, ))
markers = list(markers)
tg.pp_adatas(ad_sc, ad_sp, genes=markers)
cv_dict, ad_ge_cv, df = tg.cross_val(
ad_sc,
ad_sp,
device='cuda:0',
mode='clusters',
cv_mode='loo',
num_epochs=1000,
cluster_label='subclass_label',
return_gene_pred=True,
verbose=False,
)
cross_val函数将在LOOCV模式下返回cv_dict和ad_ge_cv和df_test_genes。cv_dict包含交叉验证的平均分数,ad_ge_cv存储每个基因的预测表达值,df_test_genes包含每个测试基因的分数和稀疏度。
cv_dict
## {'avg_test_score': 0.1850331576345662, 'avg_train_score': 0.2960305047561845}
- 我们可以使用
plot_test_scores来显示每个基因与稀疏性的交叉验证测试分数的概述。
tg.plot_test_scores(df, bins=10, alpha=.7)
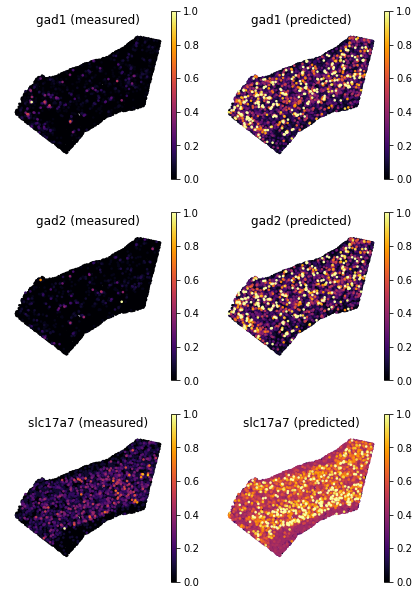
- 现在,让我们通过调用函数
plot_genes来比较一些基因的真实情况和交叉验证预测的空间模式
ad_ge_cv.var.sort_values(by='test_score', ascending=False)
ranked_genes = list(ad_ge_cv.var.sort_values(by='test_score', ascending=False).index.values)
top_genes = ranked_genes[:3]
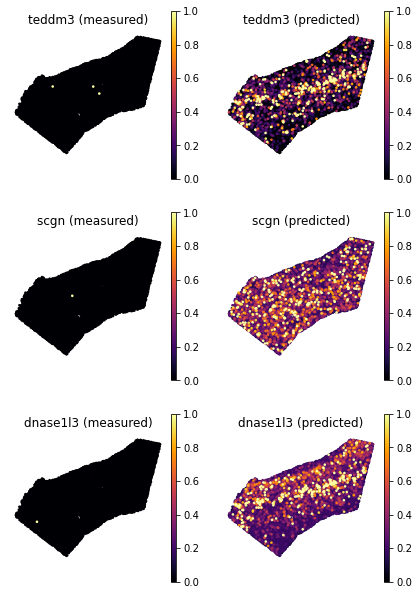
bottom_genes = ranked_genes[-3:]
tg.plot_genes_sc(genes=top_genes, adata_measured=ad_sp, adata_predicted=ad_ge_cv, x = 'x', y='y',spot_size=50,scale_factor=0.1, perc=0.02, return_figure=False)
tg.plot_genes_sc(genes=bottom_genes, adata_measured=ad_sp, adata_predicted=ad_ge_cv,x='x', y='y', spot_size=50,scale_factor=0.1, perc=0.02, return_figure=False)

本文由mdnice多平台发布