基于jieba、TfidfVectorizer、LogisticRegression的垃圾邮件分类 - 简书 (jianshu.com)
学习这篇文章中遇到的一些问题。
1、
到2018年9月27日仍为最新版本的anaconda下载链接: https://pan.baidu.com/s/1pbzVbr1ZJ-iQqJzy1wKs0A 密码: g6ex
官网下载地址:https://repo.anaconda.com/archive/Anaconda3-5.2.0-Windows-x86_64.exe
下面代码的开发环境为jupyter notebook,使用在jupyter notebook中的截图表示运行结果。”
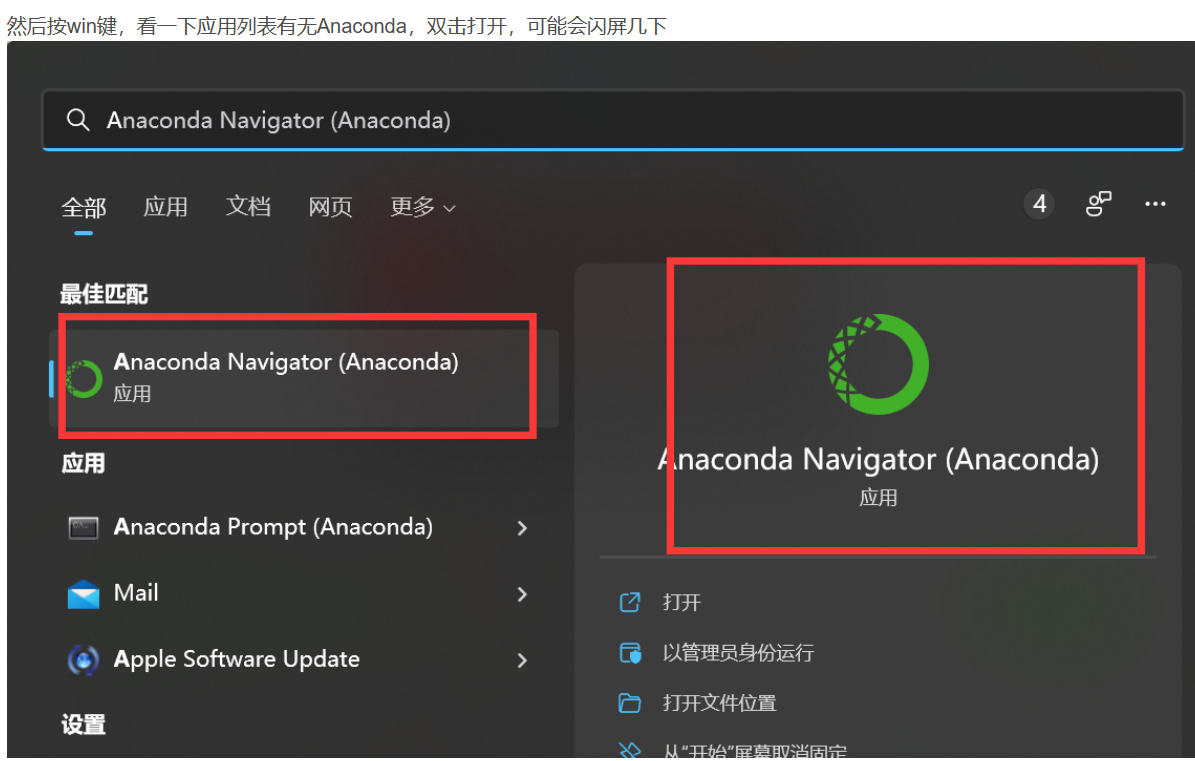
这里我也按教程搜索了Anaconda Navigator,但我并没有出现如上述一样成功打开的页面,反而一直停在load application,进不到正常页面。
于是百度搜索解决办法,找到一文解决安装Anaconda卡在Loading applications的问题!_安装anaconda卡住不动_研行笔录的博客-CSDN博客,用此博主的办法成功解决问题!
在此过程中我还尝试了其他博主文章中提到的办法但是均没有解决:

修改了提到的文件,但是没有用,但是也学到一个小tip,那就是在pycharm中使用crtl+f可以实现搜索某个语句。
(2)关于Anaconda navigator一直显示loading......的问题_python_ChanicaBang-DevPress官方社区 (csdn.net)

这个方法也并没有用。
还有一个问题:there is an instance of anaconda navigator

1.数据下载
数据文件下载链接: https://pan.baidu.com/s/1kqOFq8Ou_2D3fIKp0l62qQ 提取码: eu5x
压缩文件trec06c.zip当中含有64000多个包含邮件内容的文本文件。
2.数据观察
查看文件需要安装Notepad++,安装软件后鼠标右击文件,从Notepad++中打开。
由于我对trec06c数据集很了解了,所以忽略这一部分。
3.2.3 定义getFilePathList2函数
第3种是定义getFilePathList2函数,函数中主要使用os.walk方法,获取目录下所有的文件。
os.walk方法的返回结果的数据类型是列表,列表中的元素的数据类型是元组。“元组可以存储任意数量、任意类型的数据元素,如(1, 2, 3, 'apple', 'banana', 'cherry')”
元组的第1个元素,即walk[0]为表示路径的字符串;
元组的第2个元素为第1个元素所表示路径下的文件夹;
元组的第3个元素,即walk[2]为第1个元素所表示路径下的文件;
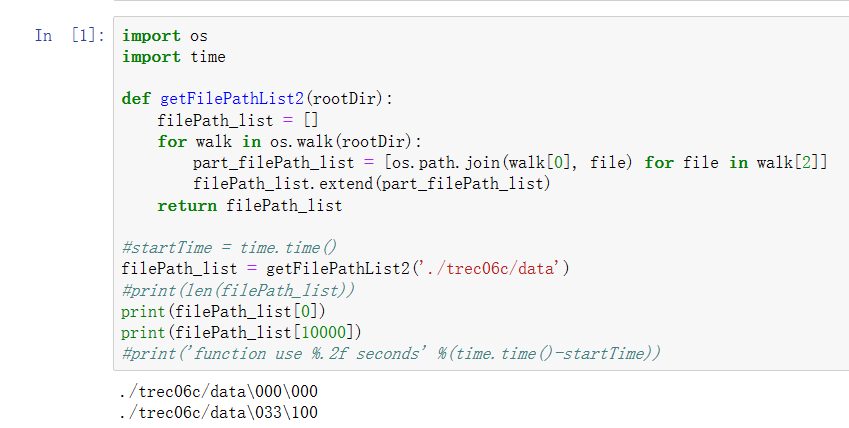
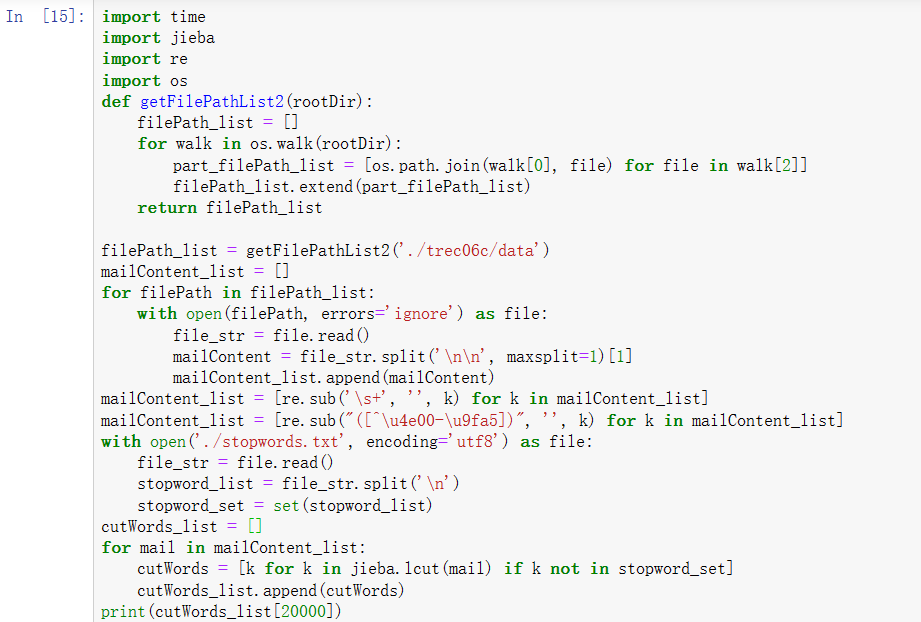
1 import os 2 import time 3 4 def getFilePathList2(rootDir): 5 filePath_list = [] 6 for walk in os.walk(rootDir): 7 part_filePath_list = [os.path.join(walk[0], file) for file in walk[2]] 8 filePath_list.extend(part_filePath_list) 9 return filePath_list 10 11 startTime = time.time() 12 filePath_list = getFilePathList2('./trec06c/data') 13 print(len(filePath_list)) 14 print(filePath_list[0]) 15 print(filePath_list[1]) 16 print('function use %.2f seconds' %(time.time()-startTime))
上面一段代码的运行结果如下:
64620
./trec06c/data\000\000
./trec06c/data\000\001
function use 0.64 secondsChatGPT中关于元组的介绍:
我自己的运行结果也差不多。此函数的作用是得到一个列表,存储每封邮件的路径。
3.3 邮件内容
3.3.1 加载邮件内容
本文作者在此项目开发中,采用快速迭代开发策略。
第1个迭代版本丢弃邮件头,内容作为特征,就取得98%左右的准确率。邮件内容列表赋值给变量mailContent_list,代码如下:
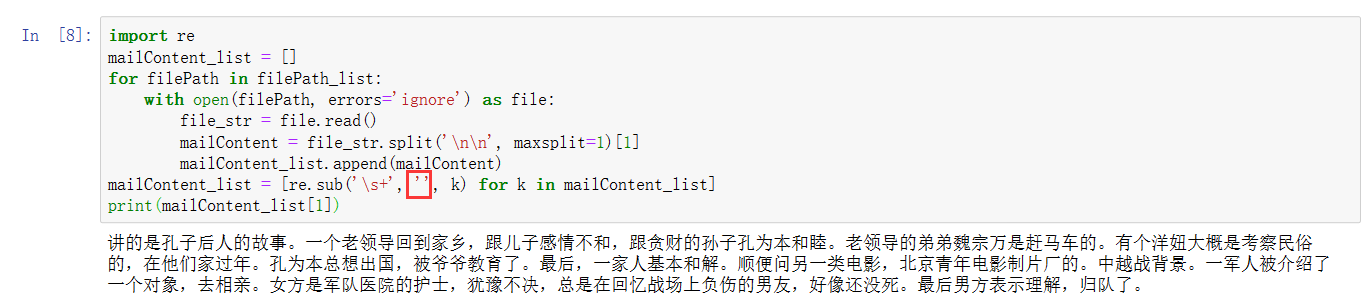
1 mailContent_list = [] 2 for filePath in filePath_list: 3 with open(filePath, errors='ignore') as file: 4 file_str = file.read() 5 mailContent = file_str.split('\n\n', maxsplit=1)[1] 6 mailContent_list.append(mailContent) 7 print(mailContent_list[1])打开分享的文件发现里面还有英文,就不用他的了。
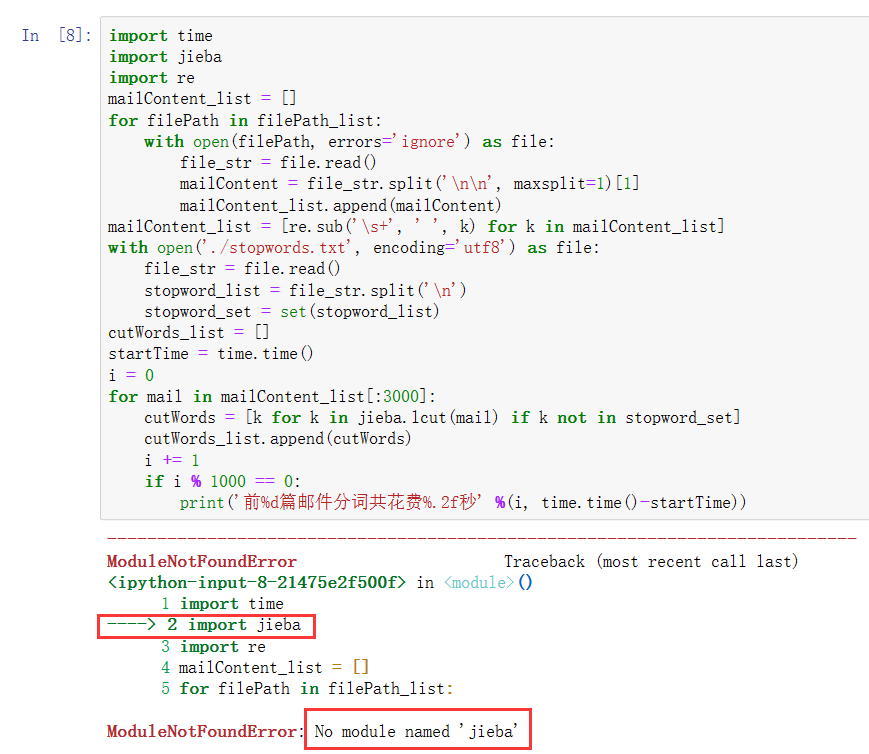
分词时import jieba出错了,显示没有jieba这个模块:
由于是头天的晚上出现的这个错误,在网上搜索了一下,发现可以下载jieba库,于是也我打算这样做,但是刚好电脑没电了,于是就没弄。
第二天起来就又搜索了一下这个问题,看了此博主的博客 在jupyter安装jieba出错ModuleNotFoundError: No module named ‘jieba‘的解决办法-CSDN博客 提到的方法5:
于是我发现这个方法我在头天晚上就试过了,但是出错了
但是我又按照它的提示,通过python -m pip install --upgrade pip升级pip,但是又出错了
这里虽然告诉我了错误原因,但我并没有去百度这个错误了。
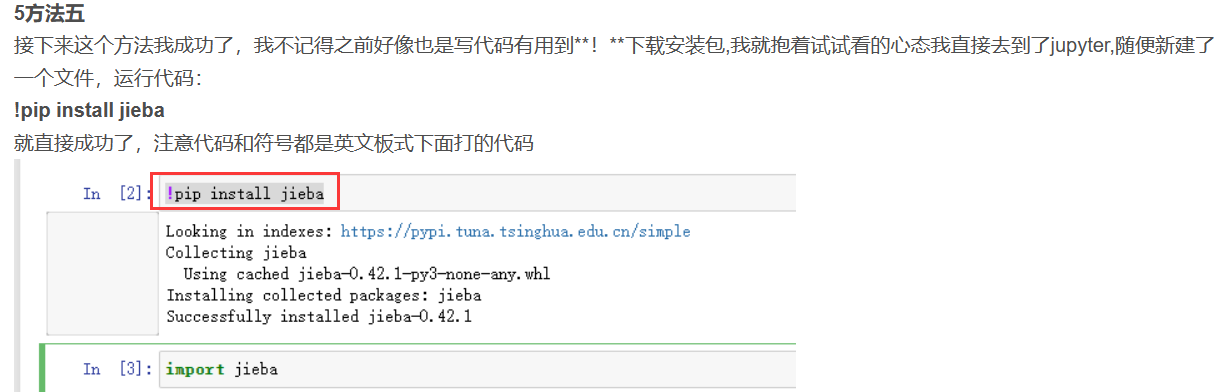
而是去看没有jieba库的解决办法了,又看到这个博主 python3安装jieba成功,但是导入仍然错误 - 简书 (jianshu.com)
于是我也就按照他输入了!pip3 install jieba,
提示有jieba库,不过它既然有这个库为什么会提示我这个错,到现在我已经忘记我为什么会出现这个错误了,好像自己突然就行了。
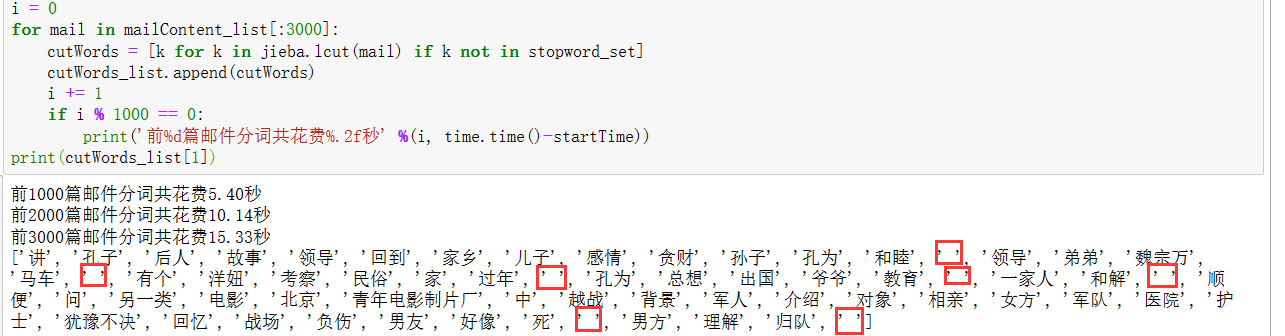
不过至此我又发现一个问题就是对一封邮件分完词后,会出现把空格也当成词分进去了:
于是我好奇为什么会这样呢,往上看代码发现,提取的邮件正文内容中并没有把空格全部去:
于是分词的时候就出现错误了。
现在开始想解决办法,想到我之前看到的一篇文章里有提到他是如何去空格的,看了一下:
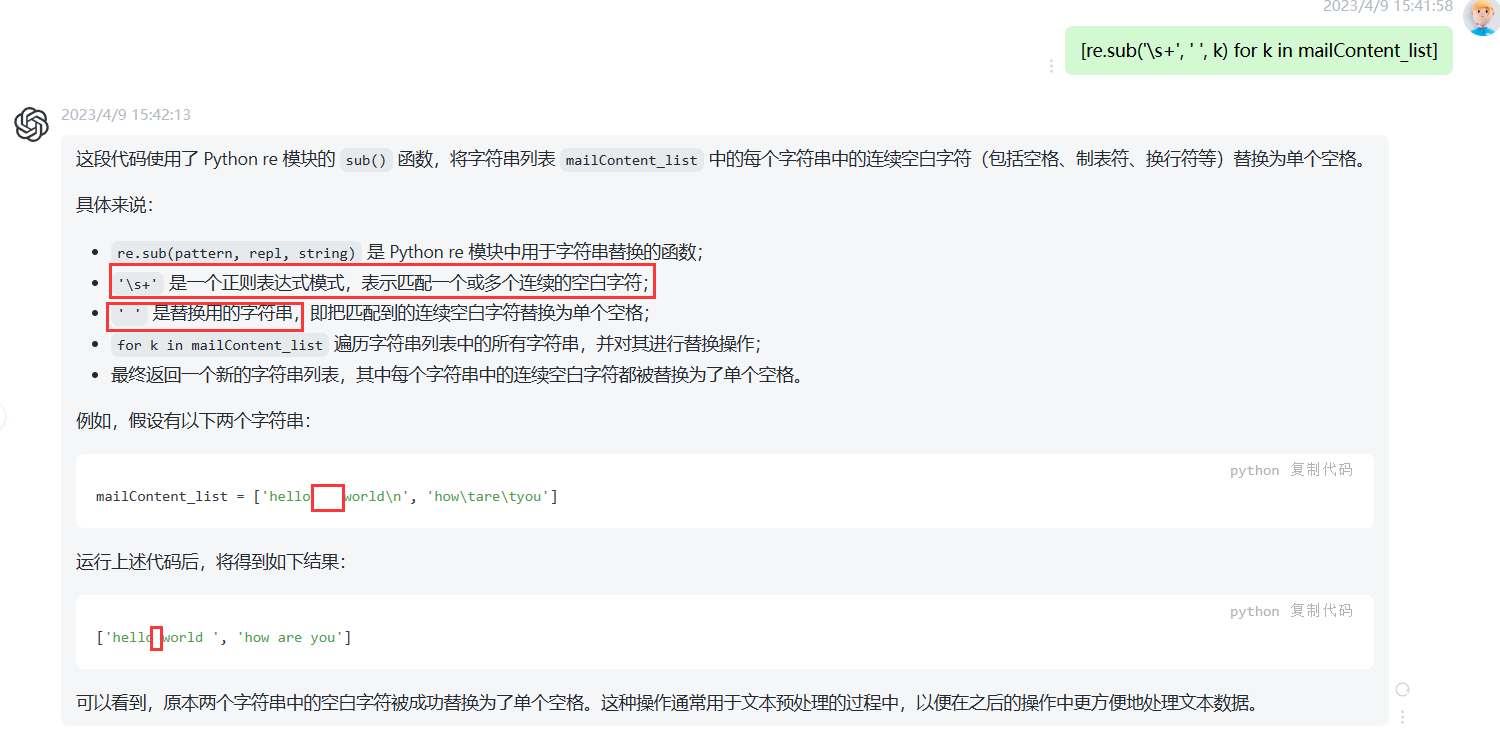
把空格去掉是这种方式,但是又无法下手,于是去chatGPT搜索了一下这个语句:[re.sub('\s+', '', k) for k in mailContent_list]的作用,解释如下:
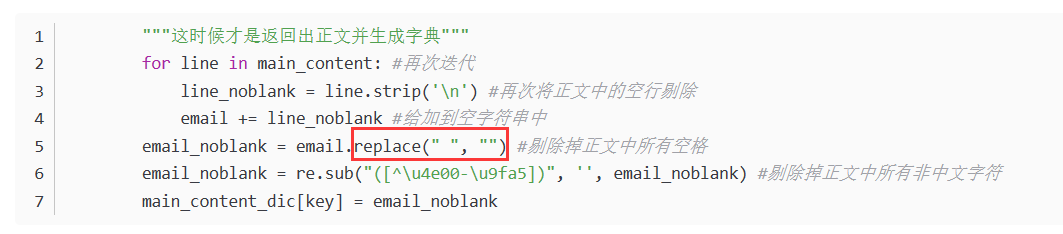
发现这个语句的作用是把多个空格替换为单个空格,这跟我去掉所有空格的理念不符啊,于是再结合另一个博主提到的replace(" ",""),所以我想到
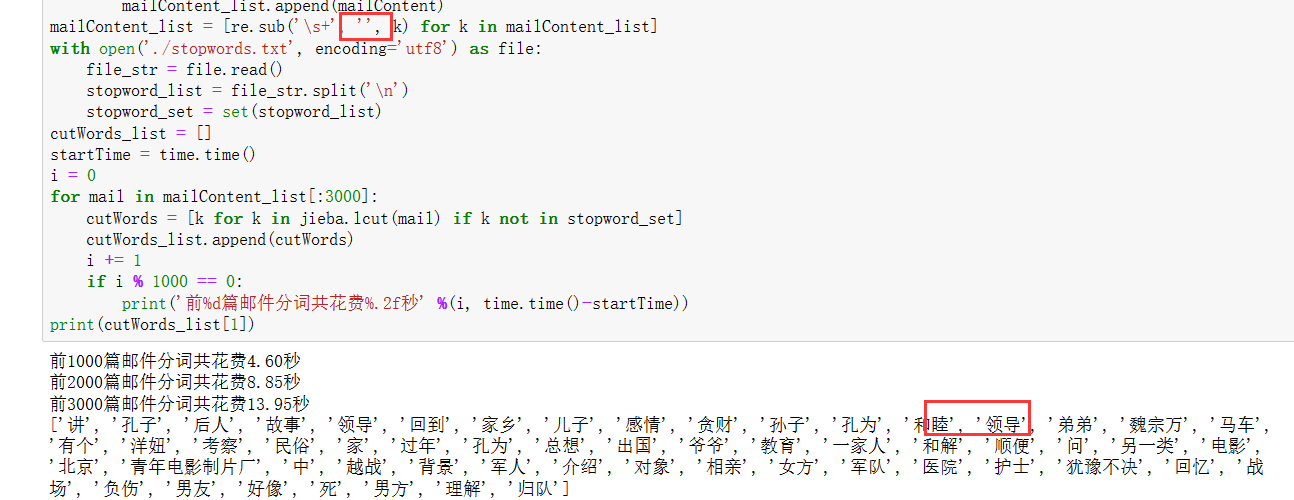
[re.sub('\s+', ' ', k) for k in mailContent_list]中' '的这个替换为'':
发现就把多余的空格去掉了,好耶nice!
但是在操作中我以为改了结果没改,然后又运行一遍发现还是有空格,以为我想错了,检查一遍才发现没去掉。
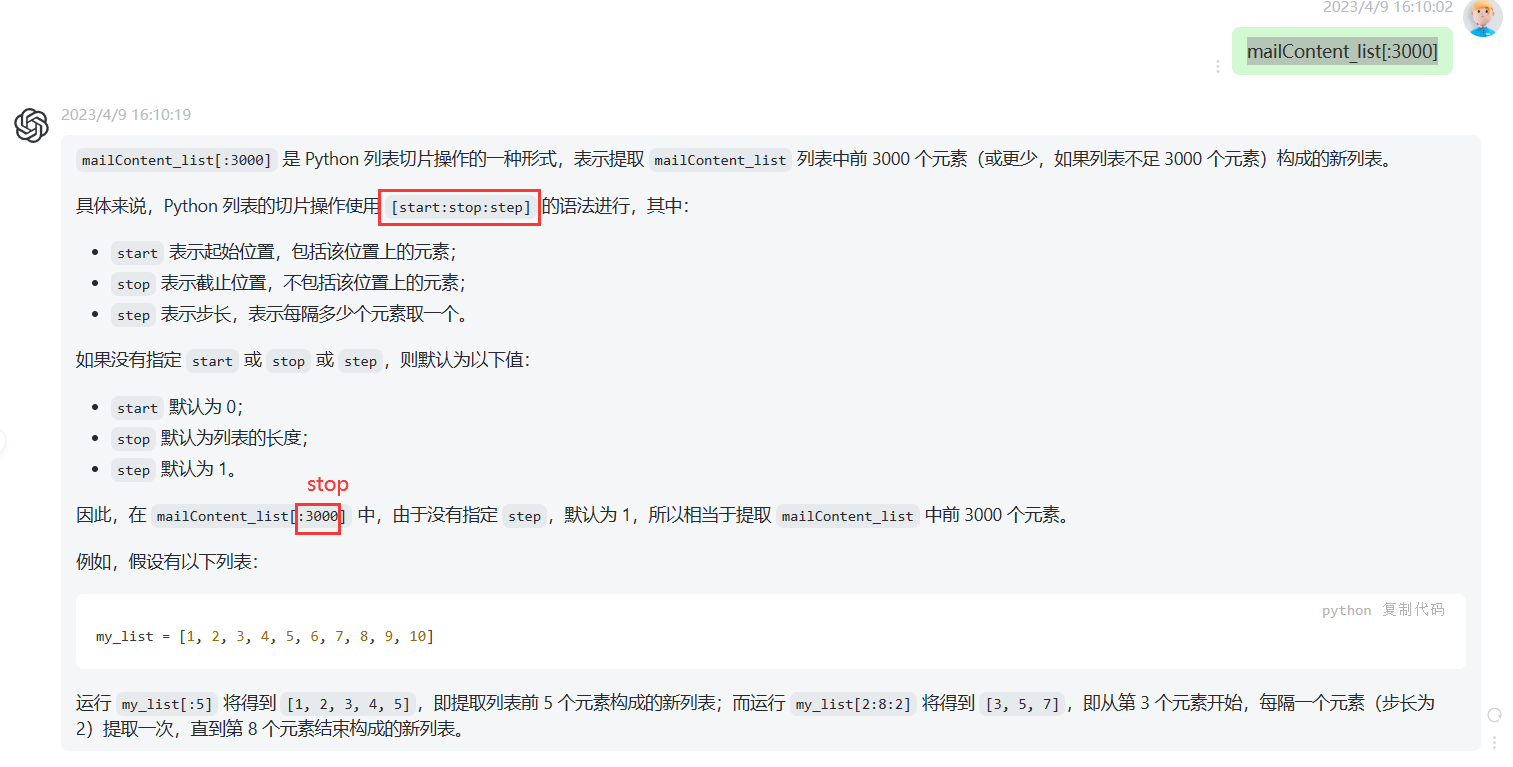
关于语句:mailContent_list[:3000]的作用我不太会,所以搜索了一下:
“从上面2种方法运行时间的对比可以看出,判断1个元素是否在集合中比判断1个元素是否在列表中效率要高。
判断1个元素是否在集合中,使用hash算法,时间复杂度为O(1);
判断1个元素是否在列表中,使用循环遍历对比的方法,时间复杂度为O(n)。
在此次分词结果去除停顿词的实践中,使用判断1个元素是否在集合中的方法,效率是判断1个元素是否在列表中的3倍左右。
64000多篇邮件分词去除停顿词共花费350秒左右,即6分钟左右。”64000多封邮件我并没有花时间去试。4.3 保存分词结果
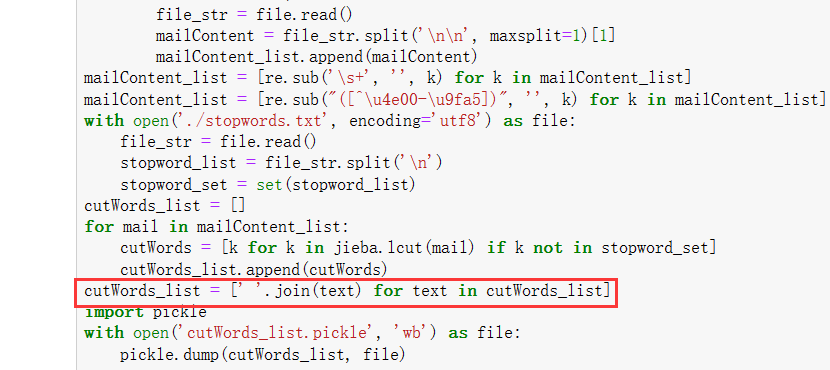
第1行代码导入pickle库
第3行代码open方法中的'wb'表示文件以二进制形式写入。
第4行代码调用pickle.dump方法将python中的对象保存到文件中。1 import pickle 2 with open('cutWords_list.pickle', 'wb') as file: 3 pickle.dump(cutWords_list, file)4.4 加载分词结果
本文作者提供已经完成的分词结果,下载链接: https://pan.baidu.com/s/1bjPgrsXKkovdgbdpzNXOmQ 提取码: x71b
压缩文件cutWords_list.zip下载完成后,其中的文件cutWords_list.pickle解压到代码文件同级目录。因为之前已经下载过这个文件,并且已经发送到QQ文件助手,所以回到文件助手中去找文件,但是提示文件发送一半,所以我又点了一下接着发送,同时我也在代码运行了
等QQ下载完后,准备复制到目录下,发现已经有了,还是代码运行比较快。
为什么要把分完后的词写入一个文件呢,我猜是分完的词要用到,如果每次用代码现分太麻烦了,所以写入文件后面只调用就可以了。
于37:55开始运行,大概42:50运行完,也差不多六分钟左右,跟博主差不多。
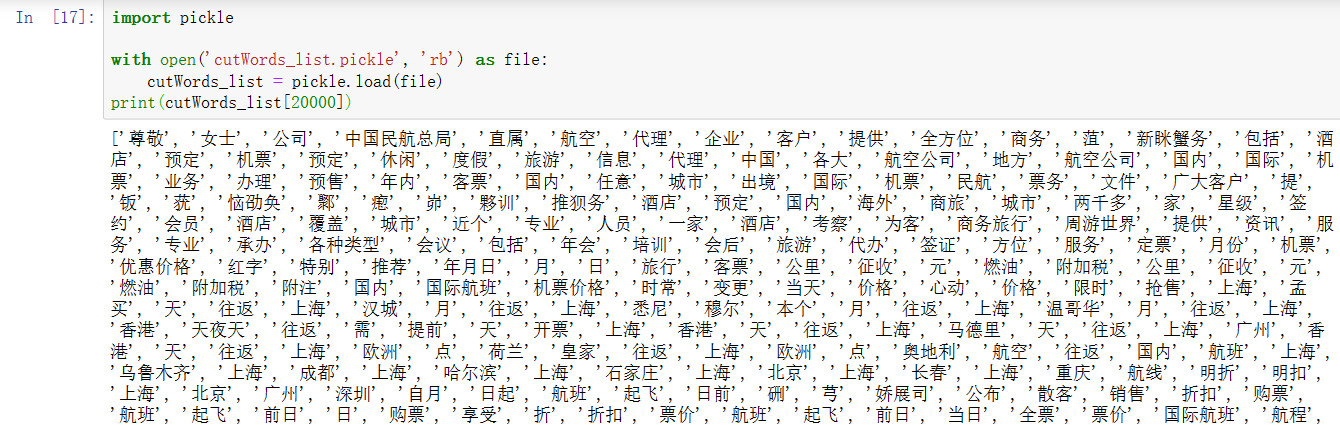
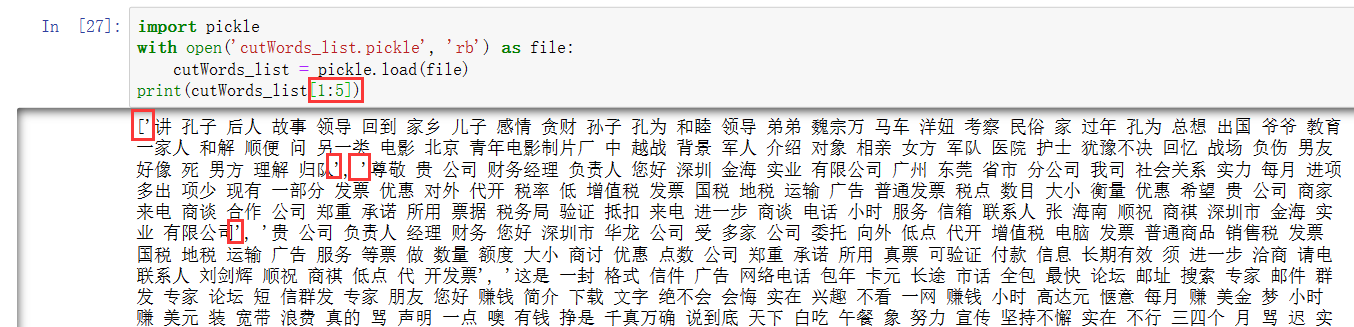
想看一下文件里的内容,于是输出第20000:
import pickle with open('cutWords_list.pickle', 'rb') as file: cutWords_list = pickle.load(file) print(cutWords_list[20000]
但是却发现有一些奇怪的东西出现在里面,这些可以忽略吗,不能忍受,所以我要想办法把它们去掉!由于列表的下标是从0开始,所以我输出的是第20001封邮件的分词结果,20001/300=60......201就是data文件夹下059/200,打开之后发现更离谱,跟上面的分词结果更不像,哈哈哈。还不如199打开的内容,因为其实下面的图显示的内容是199文件下的内容:
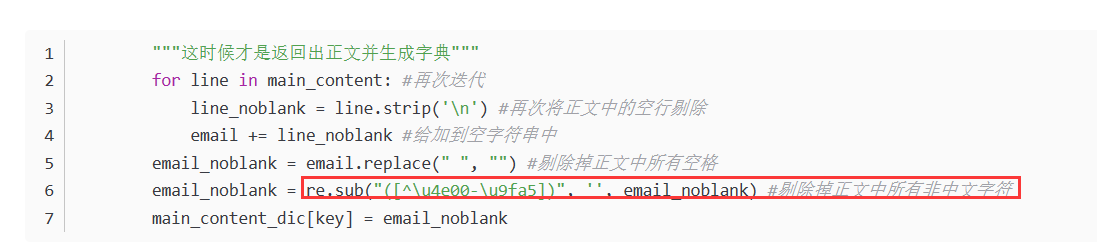
通过与分词结果对比发现好像不太一样,不管了。下面加了一个去掉所有非中文字符:
运行结果如下:
没有奇怪的字符了。bingo!
于是再次写入pickle文件,于11:40运行,17:10结束,差不多6分钟。
运行结果如下:
其实分词这一步我也弄过好多遍了,没什么问题,重要的是下面的。
5.TfidfVectorizer模型
调用sklearn.feature_extraction.text库的TfidfVectorizer方法实例化模型对象。
TfidfVectorizer方法需要3个参数。
第1个参数是分词结果,数据类型为列表,其中的元素也为列表;
第2个关键字参数min_df是词频低于此值则忽略,数据类型为int或float;
第3个关键字参数max_df是词频高于此值则忽略,数据类型为Int或float。
查看TfidfVectorizer方法的更多参数用法,官方文档链接:http://sklearn.apachecn.org/cn/0.19.0/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html1 from sklearn.feature_extraction.text import TfidfVectorizer 2 tfidf = TfidfVectorizer(cutWords_list, min_df=100, max_df=0.25)我发现文章在刚开始都很认真,但后面就慢慢不认真了。
6.1 特征矩阵
“第1行代码调用TfidfVectorizer对象的fit_transform方法获得特征矩阵;
第2行代码打印查看TfidfVectorizer对象的词表大小;
第3行代码查看特征矩阵的形状。”1 X = tfidf.fit_transform(mailContent_list) 2 print('词表大小:', len(tfidf.vocabulary_)) 3 print(X.shape)输出结果为下图:
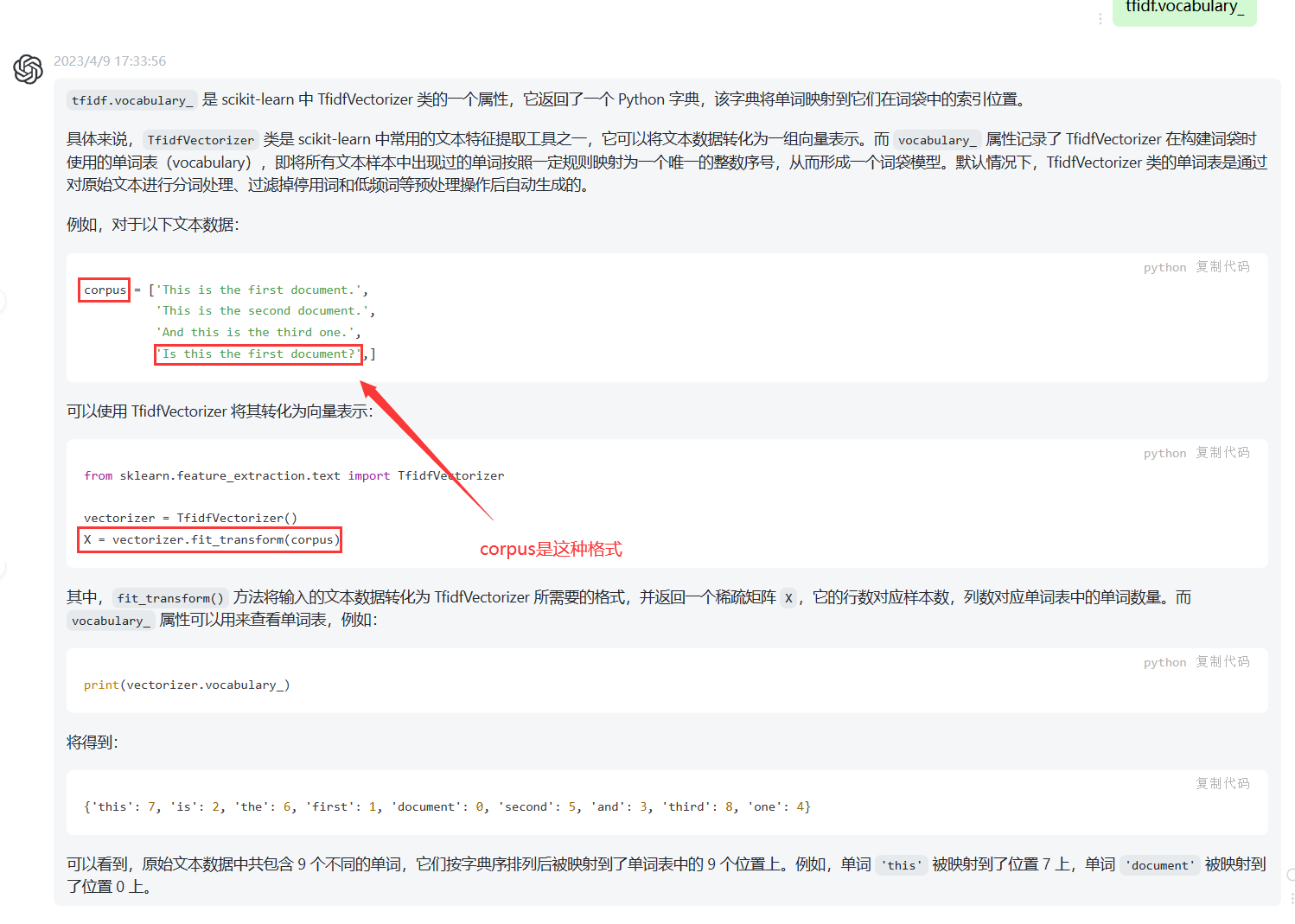
但是我觉得这个结果好奇怪啊,怎么可能只有44个特征词。于是我去搜了一下tfidf.vocabulary_
博客园中编辑图片想要删除的话,选中之后用delete键删除,backspace键总是跳来跳去,很烦。
我觉得作者对TfidfVectorizer的用法是错误的,正确的应该是上图的样子:
1 # 准备输入的文本数据,我们准备的文本数据是cutWords_list 2 corpus = ['This is the first document.', 3 'This is the second document.', 4 'And this is the third one.', 5 'Is this the first document?',] 6 # 实例化TfidfVectorizer 类 7 vectorizer = TfidfVectorizer() 8 # 将文本数据转化为向量表示 9 X = vectorizer.fit_transform(corpus)但是我自己生成的cutWords_list中的词格式是['你好','公司',...,]这种,但是方法fit_transform()的参数不能是这种,而是['你好 公司...']这种以空格连接的。那么这种格式怎么做到呢,可以用方法
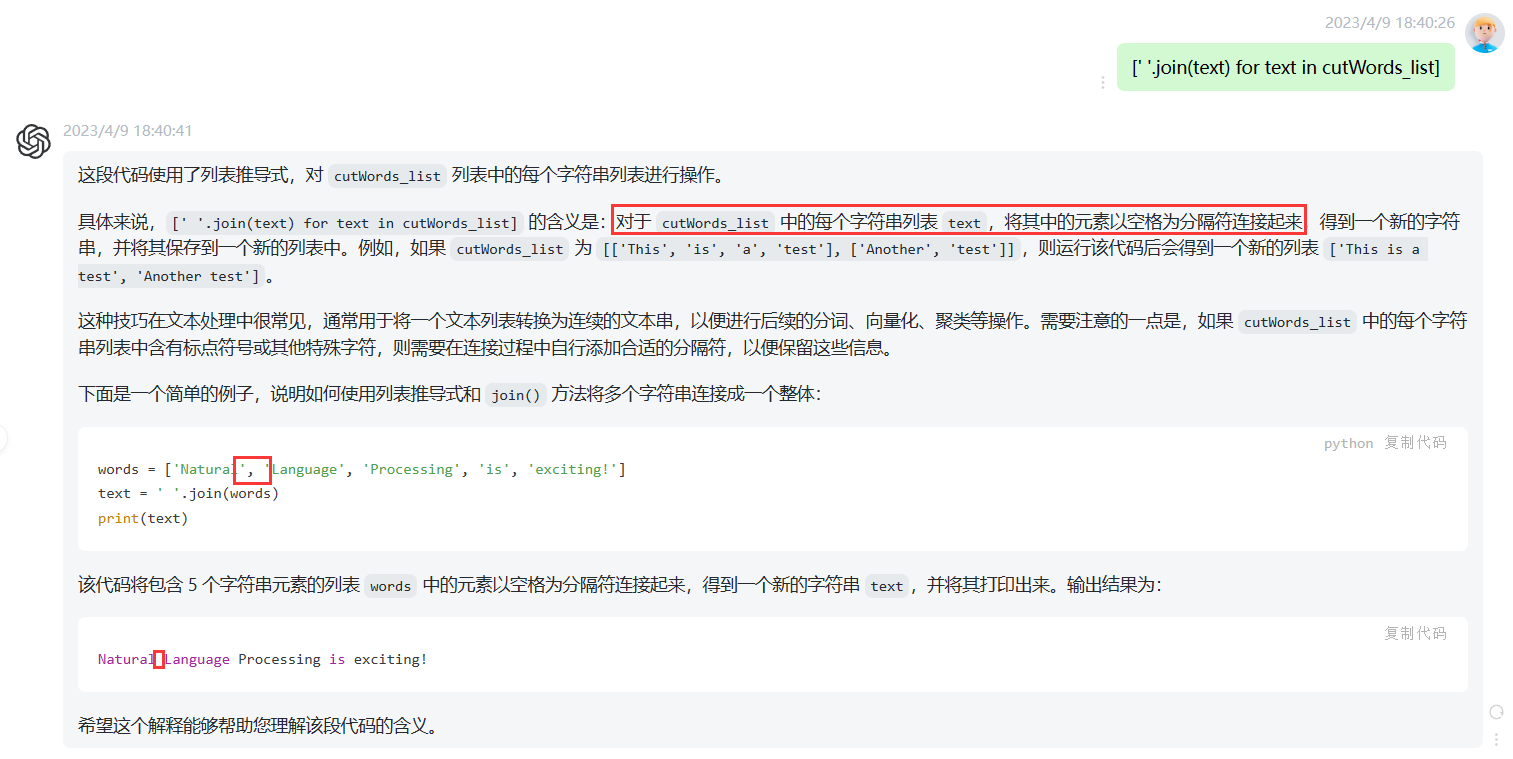
[' '.join(text) for text in cutWords_list]来做到,即将列表中的元素以空格连接。
加入这样一段话:cutWords_list = [' '.join(text) for text in cutWords_list]
根据上面的话,下面的语句就不会出错了:
1 from sklearn.feature_extraction.text import TfidfVectorizer 2 tfidf = TfidfVectorizer(token_pattern=r"(?u)\b\w\w+\b", min_df=100, max_df=0.25) 3 X = tfidf.fit_transform(cutWords_list)6.2 预测目标值
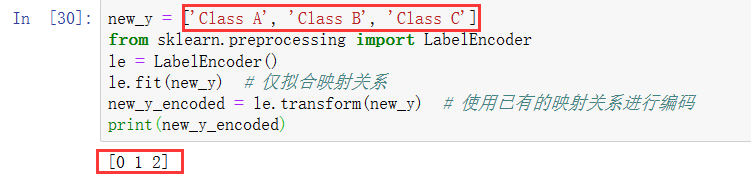
第1行代码导入sklearn.preprocessing库的LabelEncoder类;
第3行代码调用LabelEncoder()实例化标签编码对象;
第4行代码调用标签编码对象的fit_transform方法获取预测目标值。1 from sklearn.preprocessing import LabelEncoder 2 labelEncoder = LabelEncoder() 3 y_encode = labelEncoder.fit_transform(y)看到这个代码觉得有些陌生,这个y我好像并没有见过,但是回去看作者的评论可以发现是有的:
1 with open('./trec06c/full/index') as file: 2 y = [k.split()[0] for k in file.readlines()]
这个y_encode的结果就是0,1。
即将A,B,C变成整数0,1,2;那么数字0就表示了类别A。
7.逻辑回归模型
7.1 模型训练
最后1行代码ndarray对象的round方法表示小数点保留位数。
1 from sklearn.linear_model import LogisticRegressionCV 2 from sklearn.model_selection import train_test_split 3 train_X, test_X, train_y, test_y = train_test_split(X, y_encode, test_size=0.2) 4 logistic_model = LogisticRegressionCV() 5 logistic_model.fit(train_X, train_y) 6 logistic_model.score(test_X, test_y).round(4)
输出结果为0.9917。
到目前为止已经完全做出来了,作者后面还有一些步骤。