深度卷积模型:案例探究
为什么要学习一些案例呢?
就像通过看别人的代码来学习编程一样,通过学习卷积神经模型的案例,建立对卷积神经网络的(CNN)的“直觉”。并且可以把从案例中学习到的思想、模型移植到另外的任务上去,他们往往也表现得很好。
接下来要学习的神经网络:
- 经典模型:LeNet5、AlexNet、VGG
- ResNet:Residual Networt,训练了一个深达152层的神经网络
- Inception
经典模型
LetNet-5
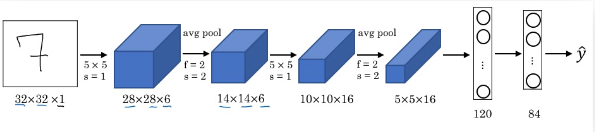
- 每次经过卷积计算后,高度和宽度都在减小,通道数在增加
- 模型有大约60k个参数,而现今的卷积网络通常都有10m-100m个参数
- LetNet-5模型的结构十分典型,到如今都很常见。即一个或多个Conv 层后跟一个Pooling层,最后为多个全连接层。
- LetNet-5 采用平均池化,现在大都最大池化;LetNet-5 隐藏层采用sigmoid/tanh作为激活函数,现在有表现更好得ReLU;现在的网络模型最后会用到softmax回归代替多个classifier
AlexNet
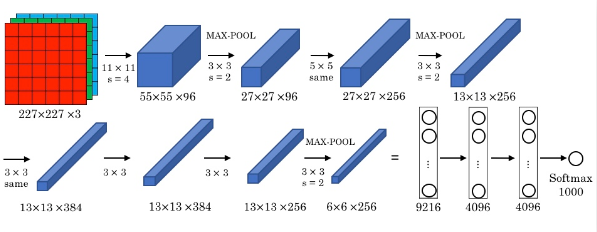
- 与LetNet-5相似,但是拥有更深的结构,因此也有更多参数,大约60m
- 使用ReLU作为激活函数
- 最终的结果从1000个分类中识别出来
- AlexNet使用了Local Response Normalization(LRN),但现在已经不怎么用了
- 为了解决GPU不足,论文中有如何在调度两个GPU的内容
VGG-16
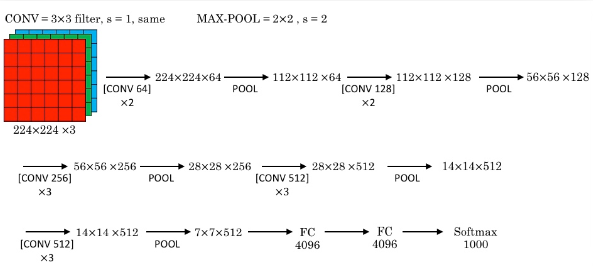
- VGG-16中16的含义是16个有参数的隐藏层
- VGG-16模型的结构比较简洁,只用了两个典型的单元(CONV=3×3filter, s=1, same;MAX-POOL=2×2, s=2)。每一个层都在翻倍filter数,从64直到512.
- 结构规整,可以描述为若干个same卷积层跟一个最大池化层。虽然模型很深,但是参数没有非常多,大约有138m个,这也是得益于其简洁的结构。
- VGG-16同样也反映了在不断加深的网络中,高度、宽度减小,而通道数增加这一结构的合理性。
- VGG-19和VGG-16表现差不多,所以VGG-16更常用
ResNets
由于梯度消失和梯度爆炸的问题,导致超大型的神经网络难以训练。
残差块
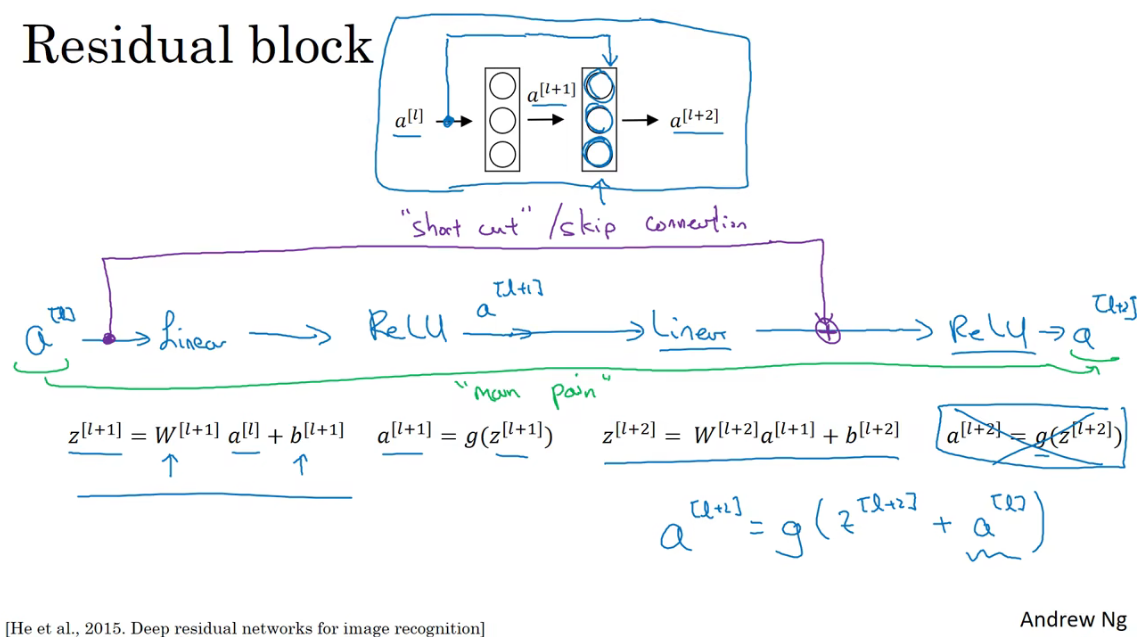
a[l]跳过两层,把信息传递给更深层的激活函数
上图中包含捷径或者跳越连接的的层组成了一个残差块,多个残差块构成了残差网络。如下图所示。ResNet在训练深层神经网络这方面非常有效。
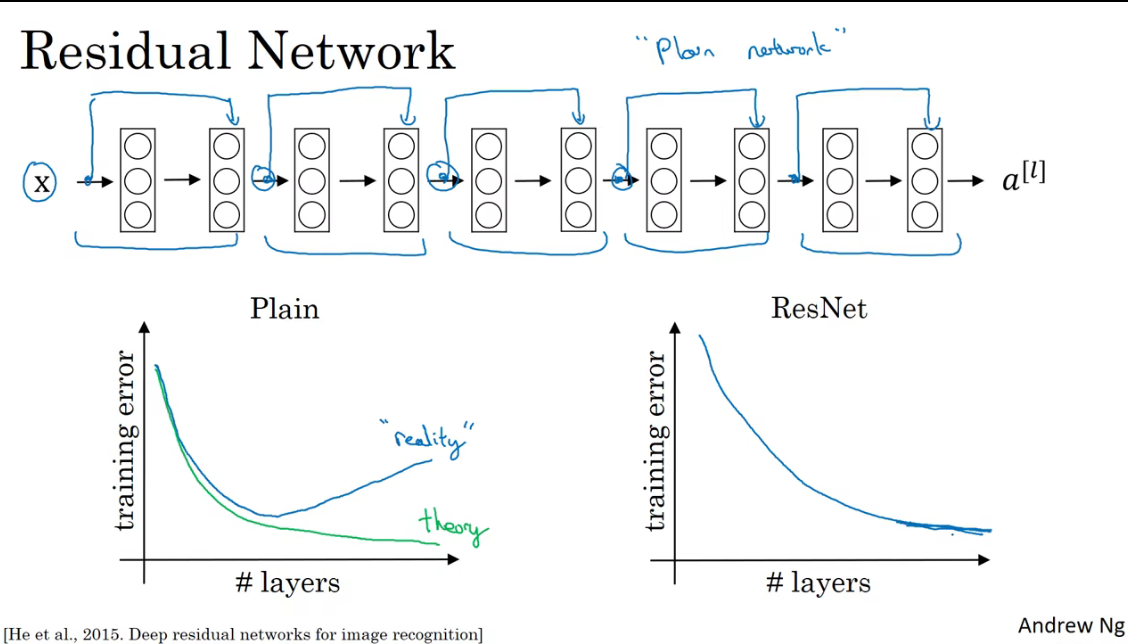
理论上,在相同优化条件下随着层数的增加,训练的错误应该越来越小。但是实际上,当层数达到一定程度后,错误率反而会上升。这可能是由于所选择的随机梯度下降策略所导致的,往往没有取到全局最优解,而是局部最优解。
ResNet为什么可以训练更深层的网络?
对于一个大型的网络如下:

在此基础上增加一个残差块,
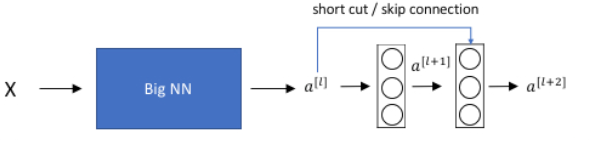
那么根据上面学到的,可以得到\(a^{[l+2]}=g(z^{[l+2]}+a^{[l]} )\),再进一步得出\(a^{[l+2]}=g(w^{[l+2]}\times a^{[l+1]}+b^{[l+1]}+a^{[l]} )\)
在很深的网络中,(正则化也会会让\(w^{[l+2]}\)是一个很小的值)可能会产生梯度消失或梯度爆炸的问题导致\(w^{[l+2]}=0\),同时也假设\(b^{[l+1]}=0\),由于使用的是ReLU作为激活函数,所以可以得到$a{[l+2]}=a $。
也就是说在很深的神经网络中,ResNet很容易学习到一个恒等函数,这样就相当于可以跳过有梯度爆炸或消失的层。即使\(w^{[l+2]}\)不是趋近于0,没有产生问题,在最后加上一个\(a^{[l]}\)也至少不会影响到网络的性能,甚至会提高效率,因为保留前面几层的更多的特征。
另外$z{[l+2]}+a \(需要保持维度一致,通常使用same 卷积计算一起使用就保持了维度。如果维度不一致,可以增加一个\)W_s\(调整\)a^{[l]}\(为\)W_s a{[l]}$。$W_s$是一个固定的矩阵,只用作把$a\(的维度和\)z^{[l+2]}$一致,对应位置填充1,其他位置填充0。
1x1的卷积
当filter的维度是1x1,对于一个6x6通道为1的图片,也只是将对应元素乘以filter的数字,填入到新的矩阵中,这样对卷积计算好像也没有什么具体的效果。
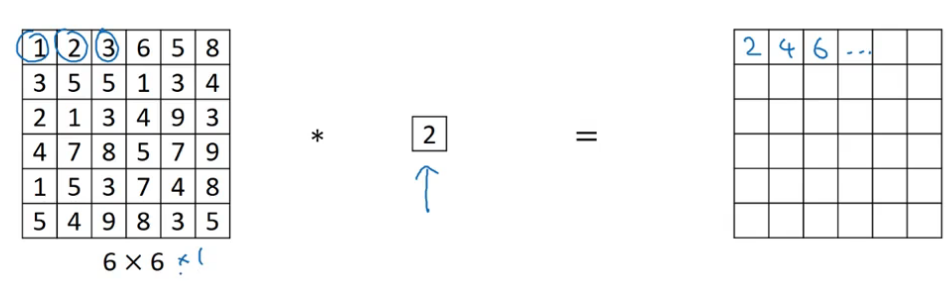
如果是对于一个有多个通道的图片可能会有比较好的卷积效果。
把6x6图片中每个位置上全通道的元素去和filter做线性组合,然后做再将结果应用于激活函数(ReLU)。
就像是这32个通道和filter建立了全连接层。(全连接层输入是32,对应的输出是filter的数量)。
因此,1x1 Convolutions也称为Network in Networks。如果有多个1x1 Convolutions,则输出矩阵也是多个channel的。
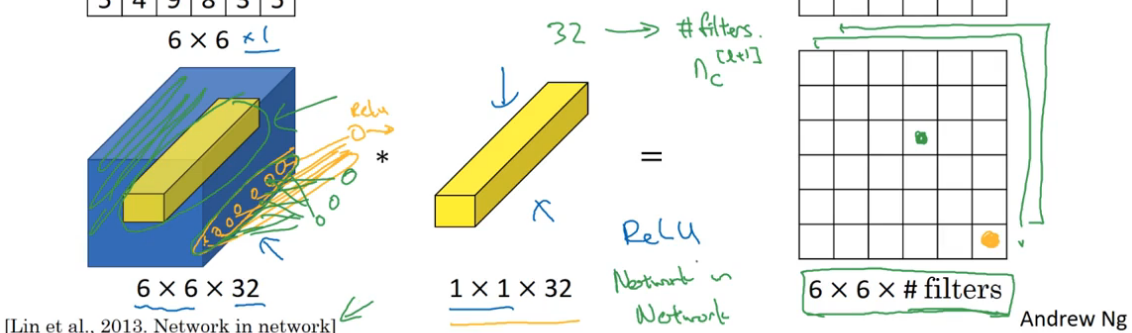
1x1卷积的效果:
- 在不改变长度和宽度的情况下,对通道数进行调整,并不损失特征信息
- 增加了非线性性质
- 降低计算量的思想
Inception Network
Inception的核心思想
构建卷积网络时,需要去手动选择用使用多大的filter,是1x1或3x3或5x5,以及是否需要使用池化层,而Inception Network的作用就是代替你来做决定,虽然因此网络结构会变得很复杂,但是结果表现得非常好。
Inception Network所作得就是在各种形状的filter进行卷积运算,运算结果将保持原来的长度和宽度但是有不同的通道数。并将这些长宽相同的运算结果叠加在一起,形成Inception层的输出。
Inception层或者说Inception模块,最后会再进行一次特殊的池化操作,称为same池化,也叠加到上面所说的运算结果上。这里的same池化之所以会保持长宽一致,是因为将步长设置为1,以及在池化之后,进行了1x1的卷积操作去压缩通道。
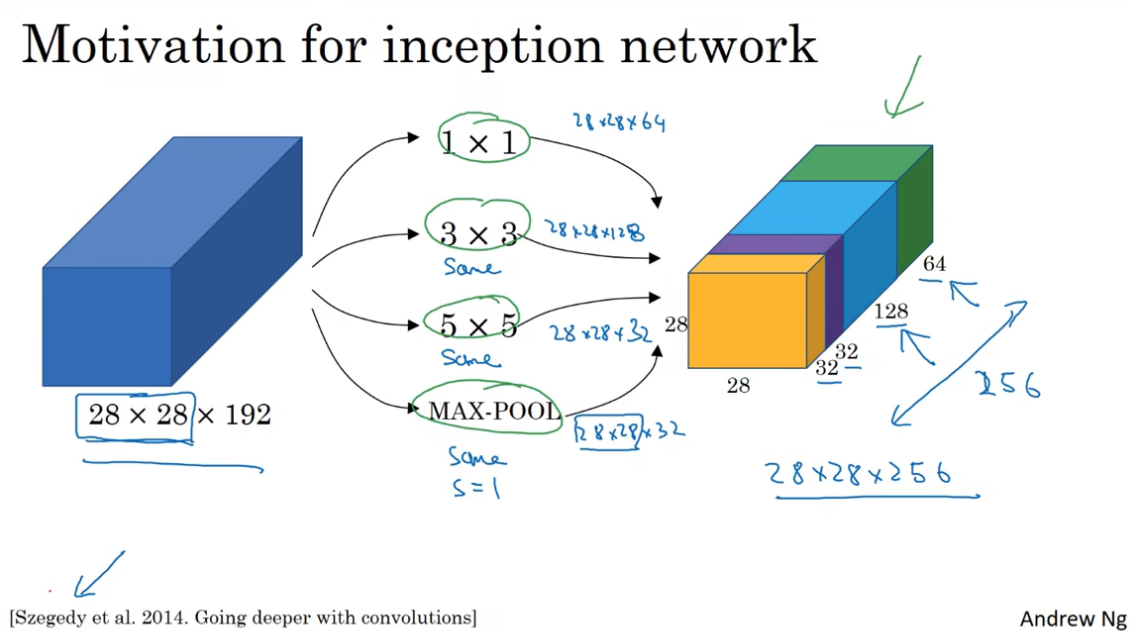
基本思想是:与其你去选择filter的大小,不如将所有可能的filter都加入,并将输出连接在一起,让网络自己学习该应用什么样的参数,采用怎样的过滤器组合。
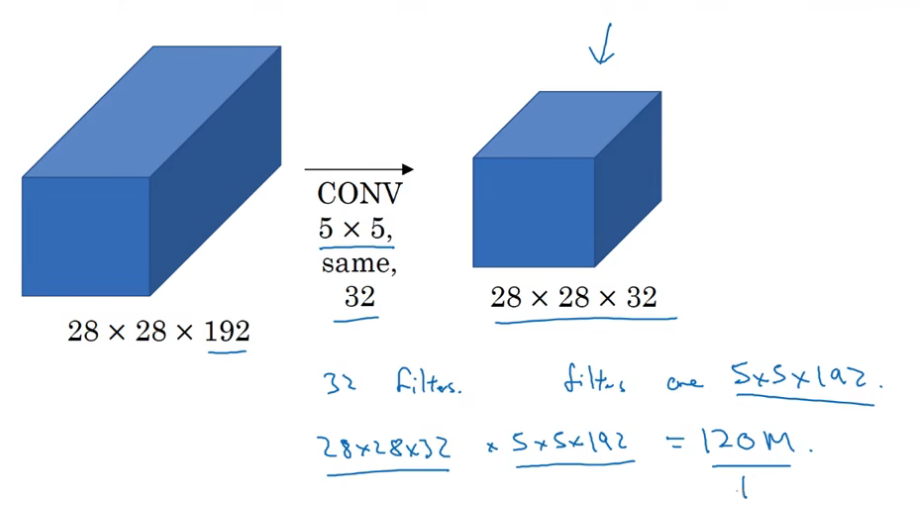
Inception Network带来的一个问题是,大幅的计算量。以上图中5x5filter部分的计算,计算的次数达到了28x28x32x5x5x192,大约是120m
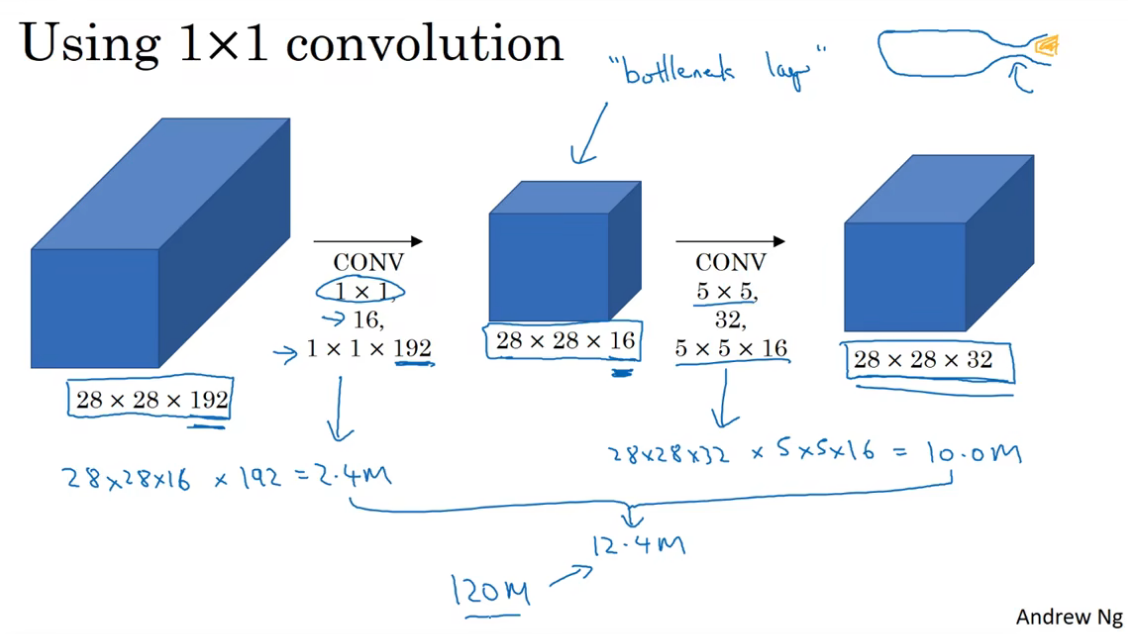
采用1x1卷积的思想来优化计算量大这一问题。
在上述的5x5filter例子中,添加一层1x1卷积去压缩通道,再使用5x5filter的same卷积,就可以大幅下降计算量。具体的计算量是8x28x16x1x1x192 + 28x28x32x5x5x16,约12.4m,降到了之前的10%。
1x1的卷积层在模块中就像时一个瓶子的瓶颈,将瓶身通道缩到了瓶盖大小,所以也称为bottleneck,瓶颈层。
总结,在神经网络的一层中,当你不知道该如何选择使用多大卷积核、还是使用池化层时,那么Inception模块就是最好的选择。其次通过1x1的卷积去构建“bottle neck”层来降低Inception模块中的计算成本。
Inception Network的具体实现
上面已介绍了构建Inception Network基本要素,现在可以构建一个完整的Inception Network了。
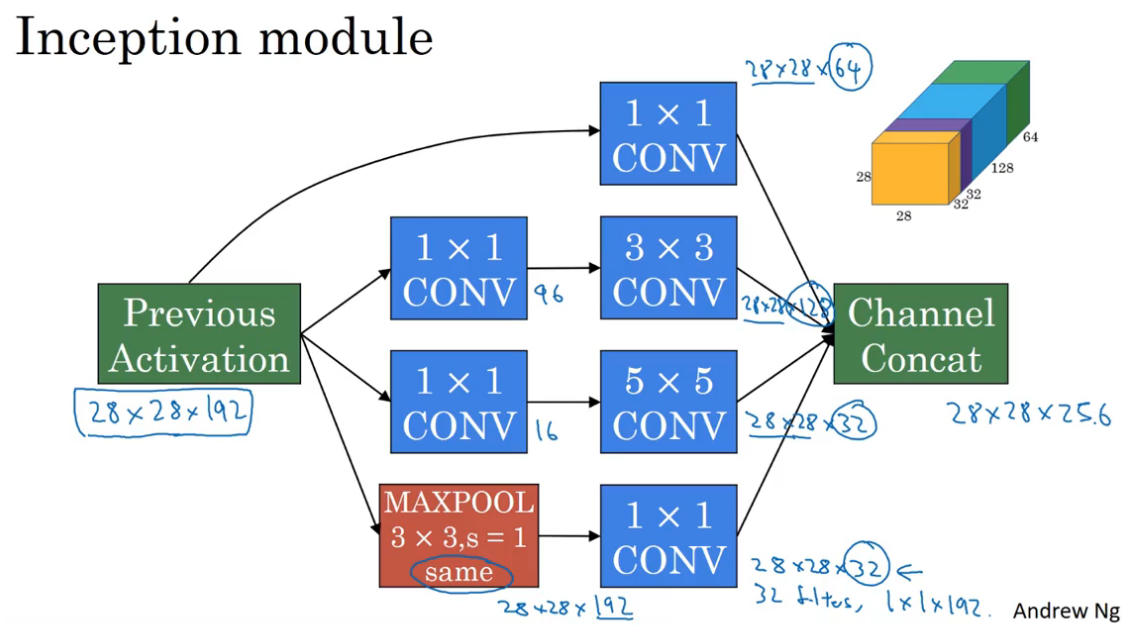
- 除了filter大小为1x1的卷积层以外,其余卷积层都用1x1卷积降低计算成本
- 池化层使用特殊的池化操作,same池化,并使用1x1卷积压缩通道数
- 将所有层的输出连接在一起形成Inception模块的输出
在Inception Network中间的隐藏层还有分支,这些分支是全连接层,做softmax的输出。使用隐藏层直接做预测,可以看作是对最后分类结果的微调。表明中间隐藏层的特征也参与了最后的预测,能防止网络发生过拟合。
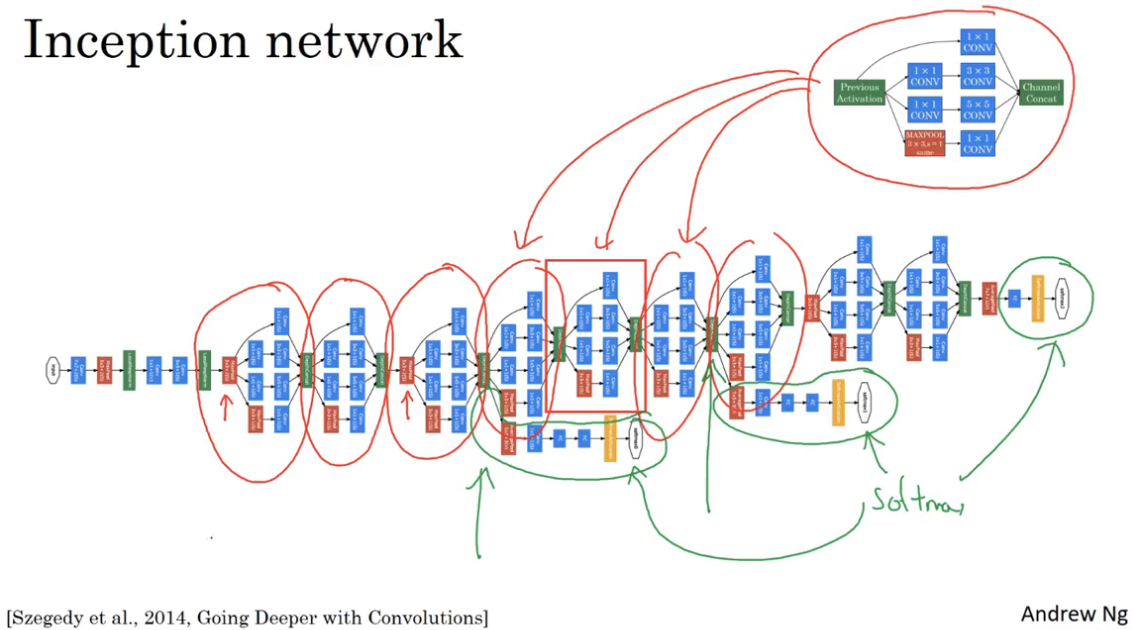
Inception Network也发展出了很多版本,比如结合Skip Connection。Inception也叫GooLeNet,致敬LeNet,命名Inception也是盗梦空间中的梗。

构建卷积模型的意见
使用开源的实现方案
因为神经网络的复杂和细致,直接参考论文去复现也很难成功。所以更好的方案是从开源代码开始。这些网络已经经过了长时间的训练,对这网络进行迁移学习,开始构建网络。
迁移学习
构建计算机视觉任务,相比于从头训练权重或者说从随机初始化权重开始不如使用别人已经训练好的网络架构和权重参数,把其作为一个很好的初始化,再把要实现的任务迁移过去,通常能够进展地比较快。
计算机社区有很多共享的数据集,比如:Image Net、MS COCO、Pascal types of date sets。
比如,要实现一个识别两只宠物猫的网络,对于训练集的数量级,可以有不同的迁移方案。
先下载一个图片识别的开源实现,包括训练好的参数。迁移到当前项目上,要先把softmax替换成任务中需要的样子。
当只有少量的训练集 ,只训练和softmax相关的参数。可以前面的层都认为是冻结的(freeze),保持前面这些层的参数不变,通过深度学习框架可实现这一点。
前面层的参数都被冻结了,所以可以把冻结的这部分认为是一个固定函数,取X到最后一个激活函数的映射,然后把这些数据存储起来,这样每次训练就直接从这个存储开始,就不用每次都过一遍前面的网络结构了。就相当于训练了一个只有一层的千层神经网络
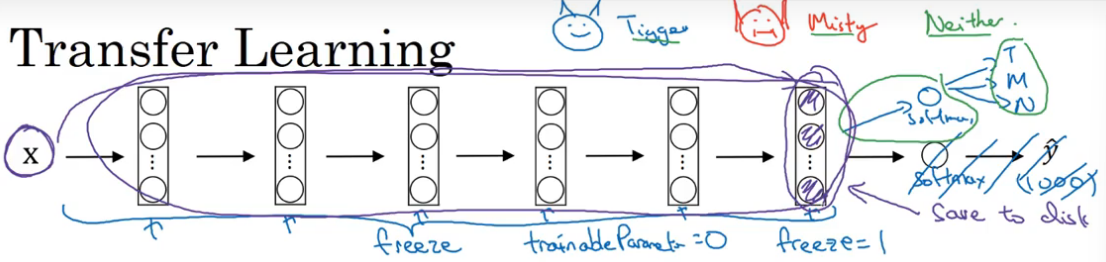
如训练集比较大,可以少冻结几个隐藏层;如果训练集非常大,那就不需要冻结了,只需要把别人训练好的权重参数作为初始化参数,以此为基础开始训练。
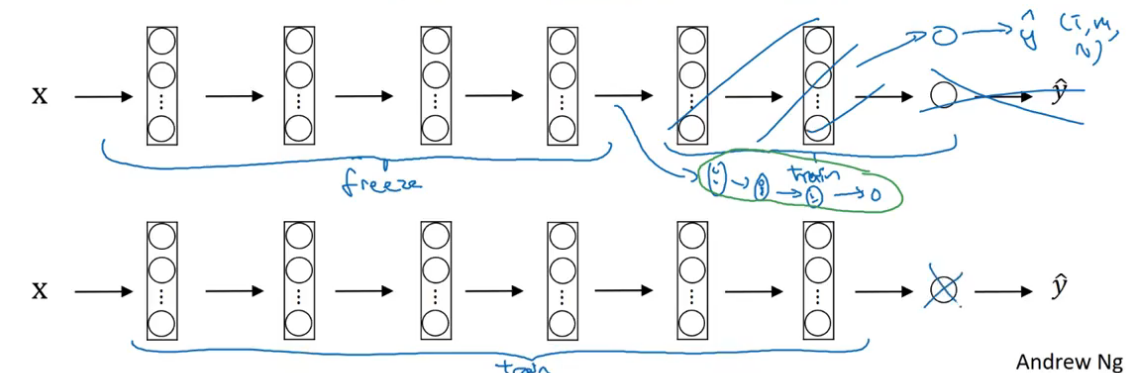
总结来说,计算机视觉领域非常适合采用迁移学习的手段,当然如果有十分大的数据集,也可以从头开始训练所有东西。
数据增强
数据扩充是是增加训练数据的一种方法,来通过计算机视觉系统的表现。
常用的数据扩充的方法有:镜像、随机裁剪、反转、颜色调整等。这些方法可以让系统更加健壮,比如颜色调整,可以让系统在遇到颜色不是很好的图片上表现得更好一些。
通常,使用一个线程去存储空间里读取图片,并进行数据扩充的操作(上面提到的),然后输入另一个线程的神经网络训练。也就是说数据扩充和训练往往是并行的。
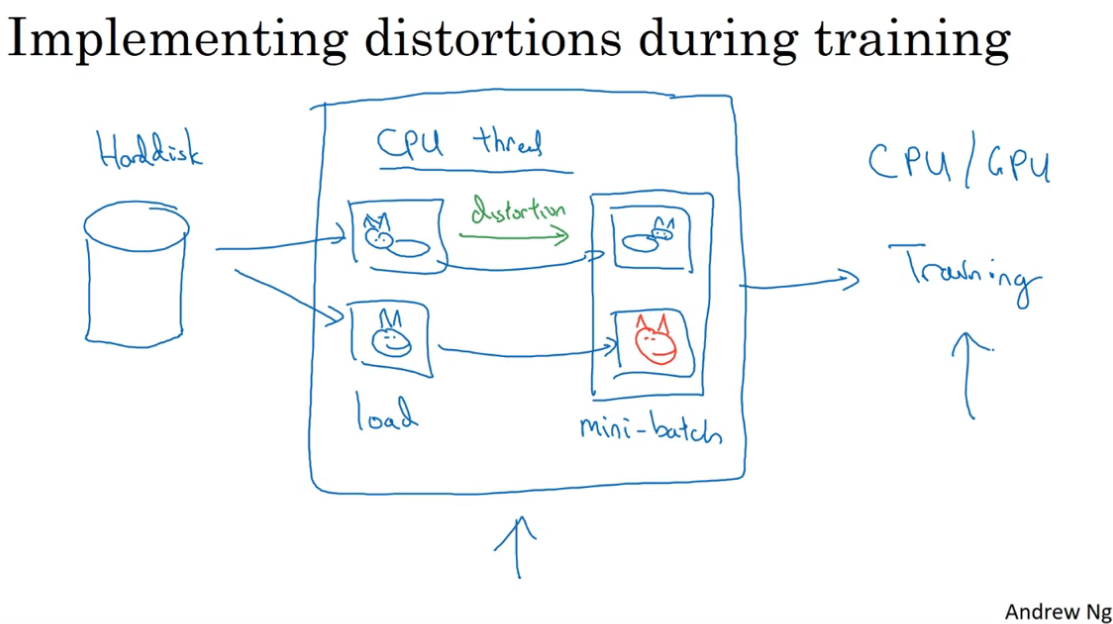
另外数据扩充也增加了一些超参数,比如图片裁剪的比例,颜色修改的力度等。
计算机视觉领域现状
手工工程(hand-engineering或hack),是指人为精心的设计特征、神经网络架构或其他系统组件。
数据量越大,用的算法也更简单,hand-engineering或hack的成分更少;相反数据不足的情况下,hand-engineering或hack的成分更大,也更有效。即形成了下面的特点:
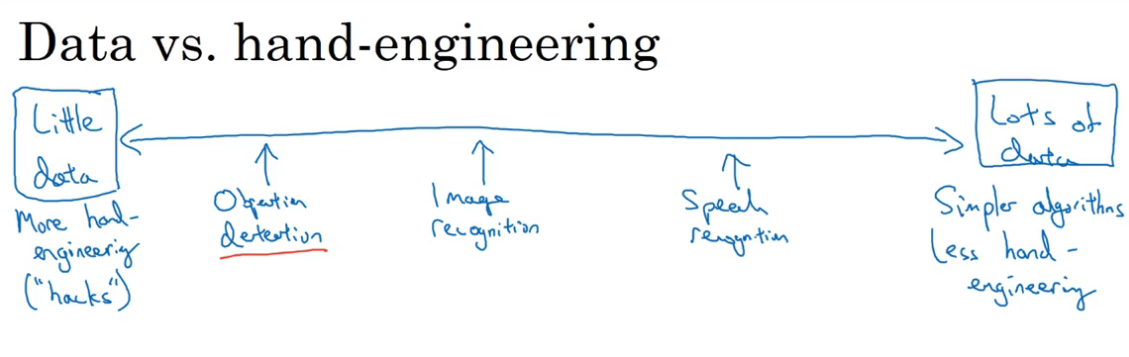
计算机视觉领域的数据集还是相对较少的,特别是计算机视觉还需要训练一个相当复杂的网络。尤其是Object detection,标注的成本很大,因此数据集更少。
因此直到现在,计算机视觉领域还需很多hand-engineering(复杂的超参数调整、数据标注)
学习算法的两种指数来源:
- 被标记的数据(Labeled Data)
- 手工设计的功能/网络架构/其他组件(Hand engineered features/network architecture/other components)
**Tips for doing well on benchmarks/Winning competitions **
- Ensembling 即独立的训练多个神经网络,然后取所有网络的输出平均值。
- Multi-crop at test time 将Data Augmentation应用到测试集,对结果进行平均。
上面这些技巧对结果的提升比较小,但是会占用更多的性能和时间,对于落地于实际的生产环境意义不大,因为没有客户愿意为这点提升付出根本代价。
最后,对于计算机视觉领域比较好的方案还是采用迁移学习,用开源的或者是论文中验证比较好的网络结构已经参数(超参数啊、权重啊)作为基础,再用自己的数据调优。