trt-hackthon2023 ControlNet-trt优化总结
题目简介
本届赛题是模型优化赛,和上届的hackthon一样,也是借助于TensorRT工具,实现对深度模型的加速,本届赛题要优化的模型为controlNet,即为类SD的图像生成模型。
比赛地址:
https://tianchi.aliyun.com/competition/entrance/532108/information
赛题解读
模型结构
首先stable diffusion(SD)的模型结构如下所示,而controlNet则是其一个变种:
![[Pasted image 20230829220025.png]]

SD模型主要分为3部分,第一部分为AutoEncoderKL模型,这部分负责图像的编解码,其中在训练过程中用到编码部分,在推理阶段用到decode部分。第二部分为UNet部分,生成模型,这部分主要负责去燥和重采样。第三部分为FrozenCLIP部分,这部分是一个tokenizer和transformer,负责将prompt编码为context。
ControlNet的模型结构如下所示:
![[Pasted image 20230829220701.png]]

相比与SDmodel加入了ControlNet,其中ControlNet会根据生成图的约束条件生成一些约束,使用lora方法微调加入一些额外的block。关键点在于zero Convolution,copy了Unet中的下采样部分参数,并在上采样时将对应的feature concat一块,所以调的参数量比较少。
![[Pasted image 20230829220814.png]]
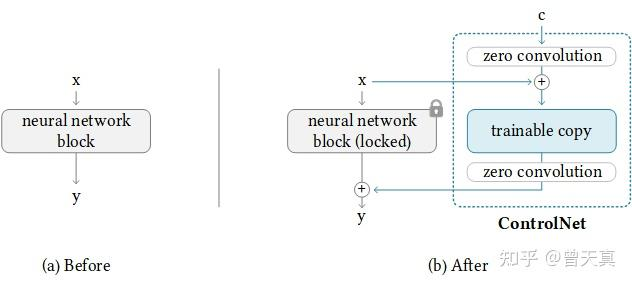
其中zeroConv部分实际上是将原有的参数冻结,然后再前后添加不改变原有形状的zero参数。
输入输出形状
分为4个模型去分析,分别是Controlnet、Unet、CLIP以及Decoder模型。下面是各个模型对应输入大小:
对于control_model,属性名为control_model,类名为ControlNet,其输入形状为:
- x: [1, 4, 32, 48](bs, _, H//8, W//8)
- Hint: [1, 3, 256, 384](bs, ch, h, w)
- timesteps:[1](bs)
- Context: [1, 77, 768] (bs, max_token_len, hidden_size)
- Controls: 13*x 13个上采样的feature,有不同分辨率,[1, 320, 32,48] (bs, ch, H//8, W//8)
对于Unet,实际类名为DiffusionModel,其输入输出形状为:
输入shape:
- x: [1, 4, 32, 48] (bs, _, H//8, W//8)
- Hint: [1, 3, 256, 384](bs, ch, h, w)
- timesteps:[1](bs)
- Context: [1, 77, 768] (bs, max_token_len, hidden_size)
输出shape:
Decoder模型,在类中属性为first_stage_model,实际类名为AutoEncoderKL,其输入输出形状为:
输入shape:
- [1, 4, 32, 48]
输出shape:
对于CLIP模型,属性名为cond_stage_model,类名为FrozenCLIPEmbedder,其输入输出形状为:
输入shape:
- prompt:str
输出shape: - [1, 4, 256, 384]
优化方案设计
策略列表
- 将原torch模型转化为trt模型运行
- 将trt模型转化为fp16半精度模型
- 增大运行batch,将condition和uncondition计算合并为一次运算
- 增加trt运行时的优化等级
- 使用cuda_graph减少kernel间的启动间隙
- 使用Mutil-stream增加异步
- 修改onnx图,增加自定义plugin插件
- 手动使用trt-module构建网络
- 使用int8 加速模型运行
需要注意的点:
- CLIP模型和Decoder模型在FP16模式下会有较大的误差,主要原因在于有些FP下的计算的结果过于小,以至于超出了FP可保存的下限。
具体实现
- torch模型转化为trt模型
这里以controlnet为例,来说明如何将torch模型转化为trt模型。
control_model = self.model.control_model
x_in = torch.randn(1, 4, H//8, W //8, dtype=torch.float32).to("cuda")
h_in = torch.randn(1, 3, H, W, dtype=torch.float32).to("cuda")
t_in = torch.zeros(1, dtype=torch.int32).to("cuda")
c_in = torch.randn(1, 77, 768, dtype=torch.float32).to("cuda")
controls = control_model(x=x_in, hint=h_in, timesteps=t_in, context=c_in)
output_names = []
for i in range(13):
output_names.append("out_"+ str(i))
dynamic_table = {'x' : {0 : 'bs', 2 : 'H', 3 : 'W'},
'hint' : {0 : 'bs', 2 : '8H', 3 : '8W'},
'timesteps' : {0 : 'bs'},
'context' : {0 : 'bs'}}
for i in range(13):
dynamic_table[output_names[i]] = {0 : "bs"}
torch.onnx.export(control_model,
(x_in, h_in, t_in, c_in),
control_onnx_path,
export_params=True,
opset_version=18,
do_constant_folding=True,
keep_initializers_as_inputs=True,
input_names = ['x', "hint", "timesteps", "context"],
output_names = output_names,
dynamic_axes = dynamic_table)
if build_trt and not os.path.isfile(control_trt_path):
cmd = f"trtexec --onnx={control_onnx_path} --saveEngine={control_trt_path} --{opt_fp} \
--optShapes=x_in:1x4x32x48,h_in:1x3x256x384,t_in:1,c_in:1x77x768"
os.system(cmd)
针对control_model, 有X,hint,time,cond等几个常规输入,controlnet是一个包含了13个不同大小分辨率的特征图。使用torch.onnx工具进行导出时,需要声明输入输出变量以及要导出的形状,注意opset小于18时,layernorm算子将不能正常导出。dynamic_table要设置动态shape,以方便在trt中使用动态形状推理。这里使用的是trtexec命令进行转化的,当然也可以使用Polygraphy等工具进行转换。
其运行时环境如下所示:
with open(control_trt_path, 'rb') as f:
engine_str = f.read()
control_engine = trt.Runtime(self.trt_logger).deserialize_cuda_engine(engine_str)
control_context = control_engine.create_execution_context()
control_context.set_binding_shape(0, (1, 4, H // 8, W // 8))
control_context.set_binding_shape(1, (1, 3, H, W))
control_context.set_binding_shape(2, (1,))
control_context.set_binding_shape(3, (1, 77, 768))
self.model.control_context = control_context
通过构建trt_loggerr构建trt_engine,再构建对应的context环境,对于当前的context环境,对每个动态shape的输入进行binding_shape。
buffer_device = []
buffer_device.append(device_view(x_noisy))
buffer_device.append(device_view(cond_hint))
buffer_device.append(device_view(t)) # t.reshape(-1).data_ptr())
buffer_device.append(device_view(cond_txt)) # cond_txt.reshape(-1).data_ptr())
control_out = []
for i in range(3):
temp = torch.zeros(b, 320, h, w, dtype=torch.float32).to("cuda")
control_out.append(temp)
buffer_device.append(device_view(temp)) # .data_ptr())
temp = torch.zeros(b, 320, h//2, w//2, dtype=torch.float32).to("cuda")
control_out.append(temp)
buffer_device.append(device_view(temp)) # .data_ptr())
for i in range(2):
temp = torch.zeros(b, 640, h//2, w//2, dtype=torch.float32).to("cuda")
control_out.append(temp)
buffer_device.append(device_view(temp)) # .data_ptr())
temp = torch.zeros(b, 640, h//4, w//4, dtype=torch.float32).to("cuda")
control_out.append(temp)
buffer_device.append(device_view(temp)) ## .data_ptr())
for i in range(2):
temp = torch.zeros(b, 1280, h//4, w//4, dtype=torch.float32).to("cuda")
control_out.append(temp)
buffer_device.append(device_view(temp)) # .data_ptr())
for i in range(4):
temp = torch.zeros(b, 1280, h//8, w//8, dtype=torch.float32).to("cuda")
control_out.append(temp)
buffer_device.append(device_view(temp))
buffer_device = [buf.ptr for buf in buffer_device]
self.control_context.execute_async_v2(buffer_device, cuda.Stream().ptr)
在真正推理时,需要将数据放入buffer_device中,其实是cuda缓存区,如果是c++则需要将host的内存数据搬到对应的device中去。在python中因为torch提供一种直接访问cuda显存的方式,所以相对就简单一些,然后将准备好的buffer_device送入到context下进行异步执行。
其他模型转化类似可参考。
- 将trt模型转化为fp16半精度模型
将trt转化为fp16运行在实际代码上改动量并不算大,因为tensorrt本身已经对fp16做了比较好的支持,只需要在trtexec时开启fp16选项即可。这里需要注意的是,因为fp16时有溢出,所以某些位置要特殊处理。比如在CLIPmodel中,所有的mask都被置为了-inf, 还有Softmax操作,因为存在指数对数,只需要改为一个特别小的负数即可:
# change onnx -inf to -1e4
for node in new_onnx_model.graph.node:
# if node.name == "/text_model/ConstantOfShape_1":
if node.op_type == "ConstantOfShape":
print(node)
attr = node.attribute[0]
print(attr)
if attr.name == "value" and attr.t.data_type == onnx.TensorProto.FLOAT:
np_array = np.frombuffer(attr.t.raw_data, dtype=np.float32).copy()
print("raw array", np_array)
np_array[np_array == -np.inf] = -100000 # 将所有负无穷的值
attr.t.raw_data = np_array.tobytes()
print("new array", np_array)
print(attr)
onnx.save_model(
new_onnx_model,
new_onnx_path2,
# save_as_external_data=True,
# all_tensors_to_one_file=False
)
注意: fp16转换之后对应的误差在1e-2~1e-3左右。
- 增大运行batch
这里优化的点在于,由于原模型计算condition和uncondition时,是分两步进行计算的,具体实现如下所示:
model_t = self.model.apply_model(x, t, cond_txt, c_hint_in)
model_uncond = self.model.apply_model(x, t, uncond_txt, unc_hint_in)
model_output = model_uncond + unconditional_guidance_scale * (model_t - model_uncond)
那么在优化时,便可以将两次运算合并为同一个batch,然后使用chunk分割计算后的结果,具体实现如下:
model_t, model_uncond = torch.chunk(
self.model.apply_model(
torch.cat((x.detach().clone(), x.detach().clone())),
torch.cat((t.detach().clone(), t.detach().clone())),
torch.cat((cond_txt.detach().clone(), uncond_txt.detach().clone())),
torch.cat((c_hint_in.detach().clone(), unc_hint_in.detach().clone())) ), 2)
def apply_model(self, x_noisy, t, cond_txt, cond_hint=None, *args, **kwargs):
t = torch.tensor(t, dtype=torch.int32)
input_tensor = {
'x': x_noisy,
'hint': cond_hint,
'timesteps': t,
'context': cond_txt
}
input_feed = {k: device_view(v) for k, v in input_tensor.items()}
stream = cuda.Stream()
trt_outputs = self.control_engine.infer(input_feed, stream)
stream.synchronize()
trt_outputs = [t for k, t in trt_outputs.items() if 'out' in k]
control = [c * scale for c, scale in zip(trt_outputs, self.control_scales)]
for i in range(len(control)):
input_tensor[f'control_{i}'] = control[i]
input_tensor.pop('hint')
input_feed = {k: device_view(v) for k, v in input_tensor.items()}
trt_outputs = self.unet_engine.infer(input_feed, stream)
stream.synchronize()
trt_eps = trt_outputs['eps']
# print("eps diff", torch.abs(trt_eps-th_eps).max())
return trt_eps
具体推理代码和上述controlnet类似,但是在转onnx和trt时,需要将动态batch_size的大小设置为2,否则在运行trt时将出现不匹配的情况。另外需要注意的是,由于onnx的某些输入为int64,如果是torch的默认输入,则需要将原有的type int64转化为int32运行,否则在batch为2会出现越界,导致结果不正确,笔者在这点曾困惑很久。
- 增加trt运行时的优化等级
这点不属于认为的优化,是trt本身的优化--builderOptimizationLevel 默认参数为3,可以设置为较大的参数,比如设置为5。当设置为5时,对应算子运行的搜索空间会变大,对应消耗的峰值显存会变大,相应地,构建时间会变长。
比赛总结
以上几点是在比赛中使用到的,并且是有明显的运行加速效果提升的。剩余的几点策略后续看完其他大佬的源码之后再来总结,也是一次非常好的学习机会。
但是反观这次比赛,我觉得有几个痛点在以后的比赛中需要注意:
- 心态问题:起步并不算晚,开始名次还算可以,但后续由于在调batch时耗费了太多时间(其实归根到底是由于粗心大意造成的),导致心态不太稳定,发挥也不太好。
- 多看社区公告:有些软件升级,也有群友提供一些比较好的想法,能够打开一些新的思路。
- 显卡缺乏:目前只有基础的硬件条件,工作区的硬件还是不太够,调试起来很耗费时间。
- 要学习的点还有很多:这次算是入门级,后续要看的东西还很多。
希望下次能够再接再厉,加油!