ControlNet-trt优化总结3:使用multi-stream和cuda-graph构建并行流水线
上节谈到使用TRT-API来构建网络,在这一节中总结一些trick来提升模型的运行效率,这些trick在所有的trt优化中均可使用,主要有以下几点:
- 使用cuda_graph减少kernel间的启动间隙
- 使用Mutil-stream增加异步
cuda_graph
cuda_graph的引入是为了解决kernel间launch的间隙时间问题的,尤其是有一堆小kernel,每个kernel启动也会带来一些开销,如果这些kernel足够多,那么就可能会影响系统的整体性能,cuda_graph的引入就是为了解决这个问题的,它会将stream内的kernel视为一整个graph,从而减少kernel的launch间隙时间。
cuda_graph基础
根据官方的源码示例,对cuda_graph的示例进行了补充,以下是完整代码示例:
#include <iostream>
#include <cuda_stream.h>
const int N = 5000;
const int NSTEP = 1000;
const int NKERNEL = 20;
const int blocks = 32;
const int threads = 512;
__global__ void shortKernel(float *out_d, float *in_d){
int idx=blockIdx.x*blockDim.x+threadIdx.x;
if(idx<N){
out_d[idx]=1.5*in_d[idx];
}
}
void run1(cudaStream_t &stream, float *out_d, float *in_d){
// start CPU wallclock timer
for(int istep=0; istep<NSTEP; istep++){
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(out_d, in_d);
cudaStreamSynchronize(stream);
}
}
}
void run2(cudaStream_t &stream, float *out_d, float *in_d){
// start wallclock timer
for(int istep=0; istep<NSTEP; istep++){
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(out_d, in_d);
}
cudaStreamSynchronize(stream);
}
//end wallclock timer
}
void run3(cudaStream_t &stream, float *out_d, float *in_d){
bool graphCreated=false;
cudaGraph_t graph;
cudaGraphExec_t instance;
for(int istep=0; istep<NSTEP; istep++){
if(!graphCreated){
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(out_d, in_d);
}
cudaStreamEndCapture(stream, &graph);
cudaGraphInstantiate(&instance, graph, NULL, NULL, 0);
graphCreated=true;
}
cudaGraphLaunch(instance, stream);
cudaStreamSynchronize(stream);
}
}
int main(int argc, char const *argv[])
{
/* code */
cudaStream_t stream;
cudaStreamCreate(&stream);
float* in_h = new float[N];
float* out_h = new float[N];
int nBytes = N * sizeof(float);
// float *in_h, *out_h;
// in_h = (float*)malloc(nBytes);
// out_h = (float*)malloc(nBytes);
for (int i=0;i<N;i++){
in_h[i] = i+1;
}
float *in_d, *out_d;
cudaMalloc((void **)&in_d, nBytes);
cudaMalloc((void **)&out_d, nBytes);
cudaMemcpy(in_d, in_h, nBytes, cudaMemcpyHostToDevice);
// run1(stream, out_d, in_d);
// run2(stream, out_d, in_d);
run3(stream, out_d, in_d);
cudaMemcpy(out_h, out_d, nBytes, cudaMemcpyDeviceToHost);
for (int i=0;i<N;i++){
printf("%f\n", out_h[i]);
}
cudaFree(in_d);
cudaFree(out_d);
delete[] in_h;
delete[] out_h;
return 0;
}
这里run1对应的是每个kernel都要进行同步,两个kernel之间会有大量的launch时间,对应的profile就像下图一样,可以看到每个kernel之间的gap时间是大于kernel本身的计算时间的,这就带来了极大的开销。
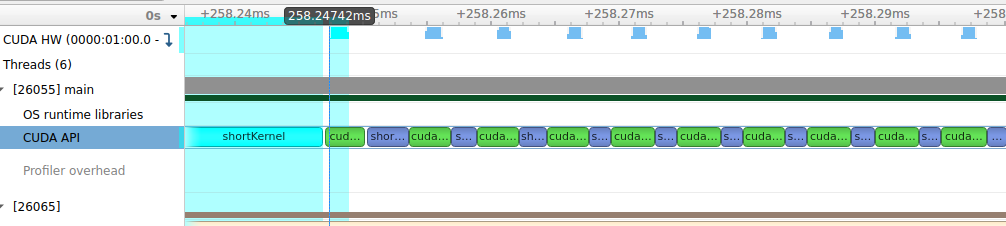
)
这里run2对应的是每20次kernel进行一次同步,也即视为每20个kernel相互间是独立的,这样20个kernel间便可以不等上一个kernel结束便开始下一轮启动,中间就可以overlap掉一部分开销,不过在同步之间的gap依然很大,profile图示如下:
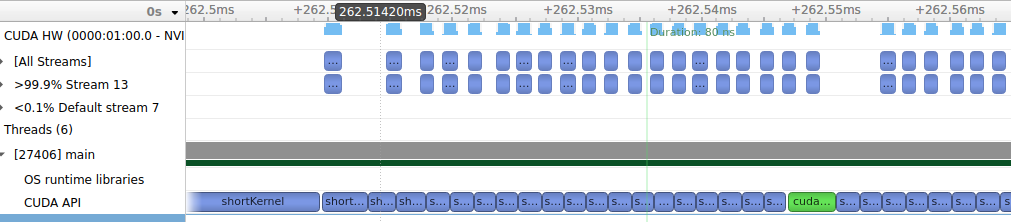
这里run2对应的是将每20个小kernel进行capture得到一个cuda_graph,然后在后续的每次运行时只需launch这个cuda_graph即可,对于这20个小kernel,便是连续的没有中间启动时间开销的,这样就可以加快运行速度,其profile图示如下所示:
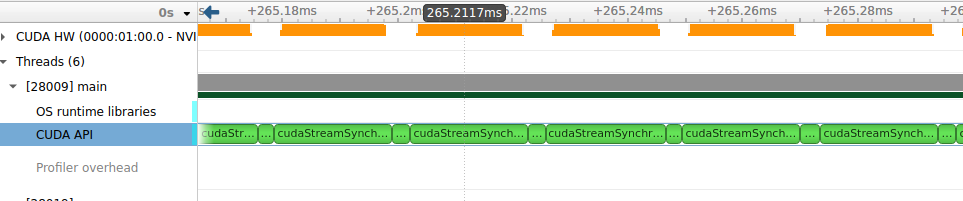
controlnet-cuda_graph优化
理解了上面cuda_graph运行原理,那么便不难写出优化代码了,具体如下:
with open('trt/{}.plan'.format(model), 'rb') as f, trt.Runtime(trt_logger) as runtime:
trt_engine = runtime.deserialize_cuda_engine(f.read())
trt_ctx = trt_engine.create_execution_context()
for index in range(trt_engine.num_io_tensors):
name = trt_engine.get_binding_name(index)
if 'vae' in model:
if name == 'z':
trt_ctx.set_tensor_address(name, self.tensors['x'].data_ptr())
if name == 'out':
trt_ctx.set_tensor_address(name, self.tensors['img_out'].data_ptr())
else:
trt_ctx.set_tensor_address(name, self.tensors[name].data_ptr())
trt_ctx.execute_async_v3(stream)
if useGraph:
cudart.cudaStreamBeginCapture(stream, cudart.cudaStreamCaptureMode.cudaStreamCaptureModeGlobal)
trt_ctx.execute_async_v3(stream)
graph = cudart.cudaStreamEndCapture(stream)[1]
graph_instance = cudart.cudaGraphInstantiate(graph, 0)[1]
else:
graph_instance = None
self.engine_context_map[model] = trt_ctx
关键在于在每次运行前都capture对应的stream,形成graph_instance,而在具体使用时,只需要将对应的graph_instance启动起来即可:
if useGraph:
cudart.cudaGraphLaunch(self.control_fp16_graph_instance, self.stream1)
cudart.cudaEventRecord(self.event1, self.stream1)
cudart.cudaGraphLaunch(self.unet_input_fp16_graph_instance, self.stream)
cudart.cudaStreamWaitEvent(self.stream, self.event1, cudart.cudaEventWaitDefault)
cudart.cudaGraphLaunch(self.unet_output_fp16_graph_instance, self.stream)
else:
self.engine_context_map['sd_control_fp16'].execute_async_v3(self.stream1)
cudart.cudaEventRecord(self.event1, self.stream1)
self.engine_context_map['sd_unet_input_fp16'].execute_async_v3(self.stream)
cudart.cudaStreamWaitEvent(self.stream, self.event1, cudart.cudaEventWaitDefault)
self.engine_context_map['sd_unet_output_fp16'].execute_async_v3(self.stream)
Multi-stream
cudaStream分为隐式流(默认流)和显式流。
对于隐式流:
- 所有的CUDA操作默认运行在隐式流里;
- 隐式流里的GPU 操作和CPU 操作两者是同步的;
对于显式流:
- CPU计算和kernel计算并行;
- CPU计算和数据传输并行;
- 数据传输和kernel计算并行
- 不同显式流的kernel计算并行
对于controlnet,可以将clip编码部分和vae的解码部分分割维两个不同的流,这样就可以利用输入输出的pipeline,上一个数据的解码便可以与下一个数据的编码同时进行。对于Unet和control部分,也可以通过分割为两个不同的stream进行处理。
self.stream = cudart.cudaStreamCreateWithPriority(cudart.cudaStreamNonBlocking, 0)[1]
self.stream1 = cudart.cudaStreamCreateWithPriority(cudart.cudaStreamNonBlocking, 0)[1]
self.event = cudart.cudaEventCreateWithFlags(cudart.cudaEventDisableTiming)[1]
self.event1 = cudart.cudaEventCreateWithFlags(cudart.cudaEventDisableTiming)[1]
self.clip_instance = self.load_engine('sd_clip', self.stream1)
self.vae_instance = self.load_engine('sd_vae_fp16', self.stream)
self.control_fp16_graph_instance = self.load_engine('sd_control_fp16', self.stream1)
self.unet_input_fp16_graph_instance = self.load_engine('sd_unet_input_fp16', self.stream)
self.unet_output_fp16_graph_instance = self.load_engine('sd_unet_output_fp16', self.stream)
在数据同步上,通过cudaEventRecord标记同步点,通过cudaStreamWaitEvent同步时间,其实是同步不同stream之间的数据,保持数据一致性,下面的例子中clip模型要等待前面tokenizer操作完成,才能进行下操作,保持stream1开始前所有stream流中的数据都处理好了,重叠的是第二次的tokenizer和第一次的clip操作,这样整个运行是个流水线。最后通过cudaStreamSynchronize来保持所有同步。
cudart.cudaEventRecord(self.event, self.stream)
cudart.cudaStreamWaitEvent(self.stream1, self.event, cudart.cudaEventWaitDefault)
if useGraph:
cudart.cudaGraphLaunch(self.clip_instance, self.stream1)
else:
self.engine_context_map['sd_clip'].execute_async_v3(self.stream1)
cudart.cudaEventRecord(self.event1, self.stream1)
参考
- nvidia cuda-graphs: https://developer.nvidia.com/blog/cuda-graphs/
- nvidia developer blogs:https://developer.nvidia.com/zh-cn/blog/how-overlap-data-transfers-cuda-cc/