自然语言是用来表达人脑思维的复杂系统。 在这个系统中,词是意义的基本单元。顾名思义, 词向量是用于表示单词意义的向量, 并且还可以被认为是单词的特征向量或表示。 将单词映射到实向量的技术称为词嵌入。 近年来,词嵌入逐渐成为自然语言处理的基础知识。
为何独热向量是一个糟糕的选择?

自监督的word2vec
word2vec工具是为了解决上述问题而提出的。它将每个词映射到一个固定长度的向量,这些向量能更好地表达不同词之间的相似性和类比关系。word2vec工具包含两个模型,即跳元模型(skip-gram) (Mikolov et al., 2013)和连续词袋(CBOW) (Mikolov et al., 2013)。对于在语义上有意义的表示,它们的训练依赖于条件概率,条件概率可以被看作使用语料库中一些词来预测另一些单词。由于是不带标签的数据,因此跳元模型和连续词袋都是自监督模型。
跳元模型
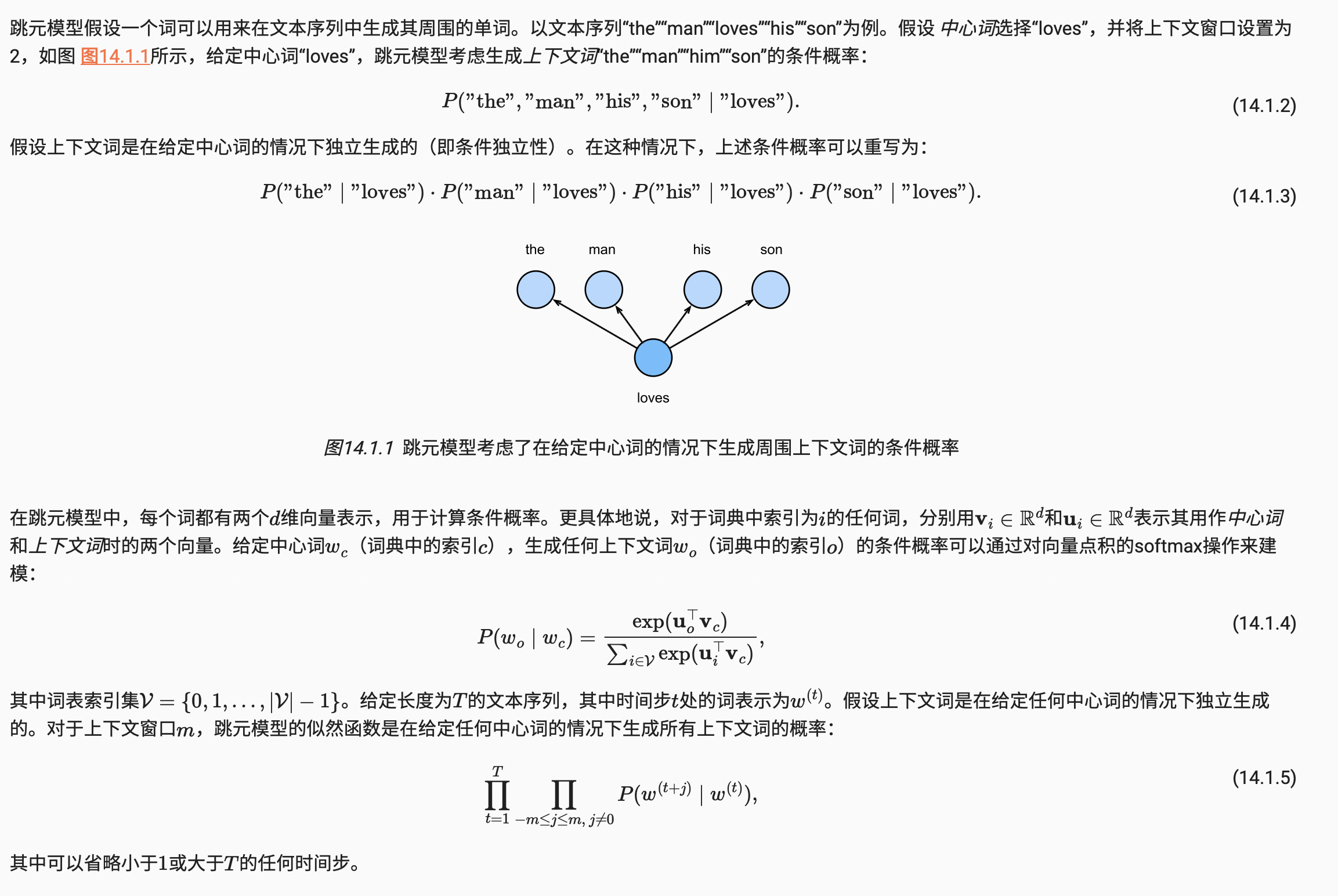
跳元模型训练

连续词袋模型
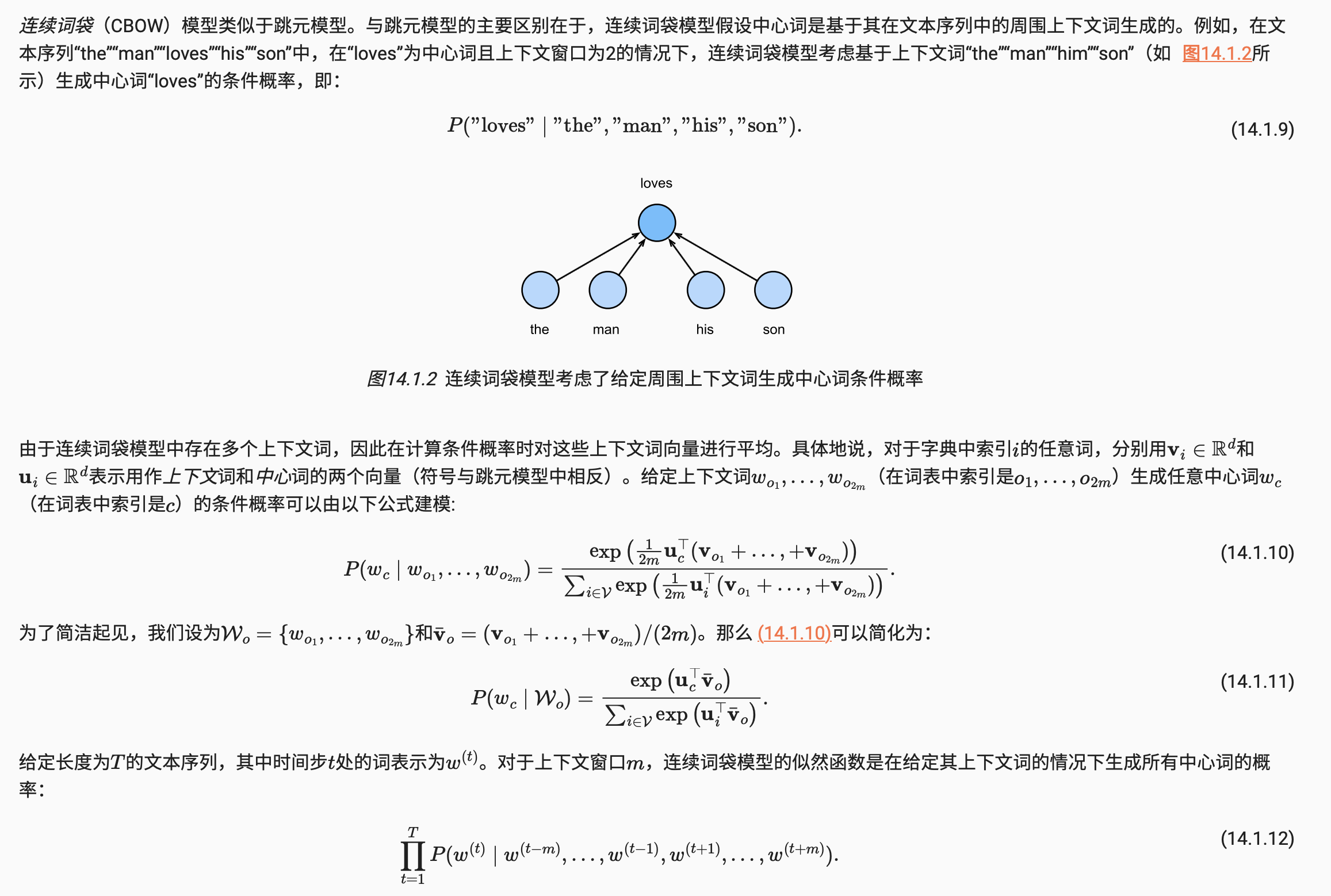
连续词袋模型训练

总结
-
词向量是用于表示单词意义的向量,也可以看作词的特征向量。将词映射到实向量的技术称为词嵌入。
-
word2vec工具包含跳元模型和连续词袋模型。
-
跳元模型假设一个单词可用于在文本序列中,生成其周围的单词;而连续词袋模型假设基于上下文词来生成中心单词。