python网络爬虫课程设计--探索Taylor Swift歌词
一、选题的背景
泰勒·斯威夫特(Taylor Swift),1989年12月13日出生于美国宾夕法尼亚州,美国乡村音乐、流行音乐创作女歌手、演员、慈善家。
2006年,与独立唱片公司大机器唱片签约,推出首支单曲《Tim McGraw》与发行首张同名专辑《Taylor Swift》,获得美国唱片业协会的5倍白金唱片认证。2008年11月11日,发行第二张专辑《Fearless》,在美国公告牌二百强专辑榜上一共获得11周冠军,被美国唱片业协会认证为6倍铂金唱片,凭借该专辑获得第52届格莱美奖年度专辑奖,专辑歌曲《White Horse》获得最佳乡村歌曲与最佳乡村女歌手奖。2013年11月,获颁第47届乡村音乐协会奖“最高荣誉”巅峰奖。2014年10月27日,发行第五张专辑《1989》 ,发行首周售出128万余张,成为美国唱片市场近十二年最高的首周销量纪录,也凭这张专辑成为唯一一位拥有三张首周百万销量的歌手。2017年11月10日,发行新专辑《举世盛名》(Reputation)。2017年,被《时代周刊》选为年度人物。2018年10月10日,获2018全美音乐奖年度艺人奖、年度巡演奖、最受欢迎流行/摇滚女歌手奖、凭借《reputation》获最受欢迎流行/摇滚专辑奖。2019年8月23日,发行第七张专辑《Lover》;11月10日,参加2019年双十一晚会;11月24日,2019全美音乐奖授予“十年艺术家奖”的殊荣。2020年,发行音乐专辑《folklore》《evermore》,前者获第63届格莱美奖年度专辑奖。
综上所述,本次课程设计将针对与Taylor的歌词进行分析。
二、数据分析设计方案
数据集来源:kaggle,网址:https://www.kaggle.com/
数据集涵盖了与Taylor相关的歌词,以及歌曲当中出现次数最多的几个单词,Taylor的专辑里面包含的歌曲。
经检查,数据中没有缺失值,也没有重复值。但数据中存在一部分的分类型变量,需要对其进行编码,方便考察变量之间相关性以及后续的预测。
使用第三方库:pandas库
matplotlib库
numpy库
wordcloud库等对Taylor的歌词数据进行可视化分析。
本篇重难点:散点文本。
用于以独立于语言的方式可视化文档类别之间的语言变化。该工具提供了一个散点图,其中每个轴对应于一个术语在一类文档中出现的排名频率。通过打破平局的策略,该工具能够显示数千个可见的术语表示点,并找到空间清晰地标记数百个点。散点文本还可用于基于查询的可视化,显示具有相似嵌入的术语在文档类别之间的使用差异,以及将单词袋特征的重要性分数与单变量指标进行比较的可视化。
实现思路:对数据集进行分析→进行数据清洗→根据所需内容对数据进行可视化→得到图像并分析结果
三、数据分析步骤
一、安装数据库
pip install wordcloud
二、导入数据库
1 import numpy as np # 线性代数 2 import pandas as pd # 数据处理,CSV文件I/O(例如pd.read_CSV) 3 4 # 输入数据文件在“../Input/”目录中可用。 5 6 #运行操作将列出输入目录中的文件 7 import pandas as pd 8 import matplotlib.pyplot as plt 9 import seaborn as sns 10 %matplotlib inline 11 import os 12 import pandas as pd 13 import datetime as dt 14 import numpy as np 15 from IPython.core.interactiveshell import InteractiveShell 16 InteractiveShell.ast_node_interactivity = "all" 17 import matplotlib.pyplot as plt 18 plt.rcParams['figure.figsize'] = [16, 10] 19 plt.rcParams['font.size'] = 14 20 width = 0.75 21 from wordcloud import WordCloud, STOPWORDS 22 from nltk.corpus import stopwords 23 from collections import defaultdict 24 import string 25 from sklearn.preprocessing import StandardScaler 26 import seaborn as sns 27 sns.set_palette(sns.color_palette('tab20', 20)) 28 import plotly.offline as py 29 py.init_notebook_mode(connected=True) 30 import plotly.graph_objs as go 31 from datetime import date, timedelta 32 import operator 33 import re 34 import spacy 35 from spacy import displacy 36 from spacy.util import minibatch, compounding 37 import spacy #load spacy 38 nlp = spacy.load("en", disable=['parser', 'tagger', 'ner']) 39 #stops=停止语。单词(“english”) 40 from tqdm import tqdm 41 from collections import Counter 42 import matplotlib.pyplot as plt 43 %matplotlib inline 44 import warnings 45 warnings.filterwarnings('ignore') 46 import os 47 print(os.listdir("../input")) 48 from IPython.display import IFrame 49 from IPython.core.display import display, HTML 50 #写入当前目录的任何结果都将保存为输出。
代码过于繁琐,以下奉上相关的数据分析并对结果进行解释:
以下是对于TaylorSwift在tim mcgraw歌曲中,歌词出现在第几行的分析:
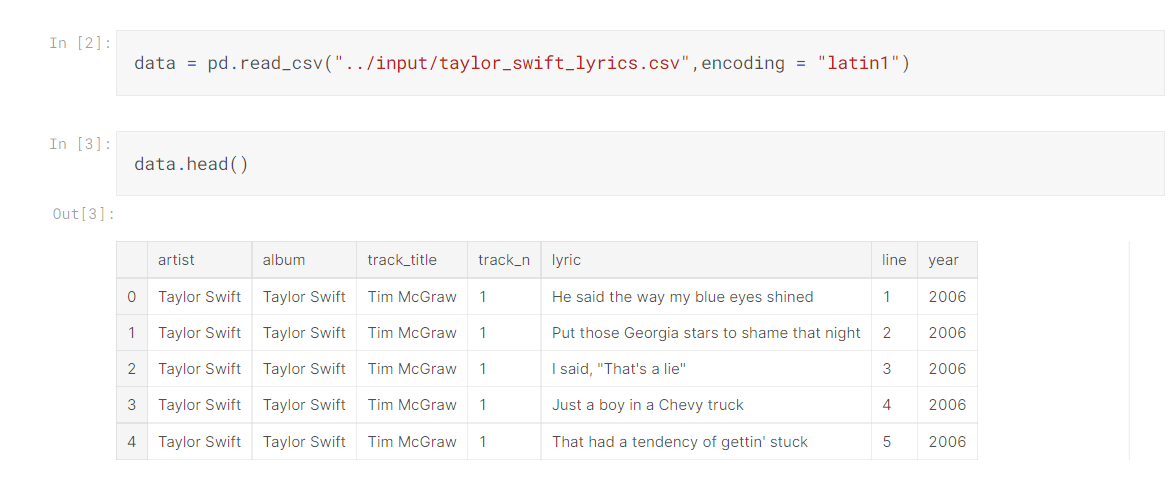
下面是对TaylorSwift年度歌词长度分布的分析,画出柱形图可以发现2010年期间歌词长度达到顶峰(没有进行预处理)
1 def get_features(df): 2 data['lyric'] = data['lyric'].apply(lambda x:str(x)) 3 data['total_length'] = data['lyric'].apply(len) 4 data['capitals'] = data['lyric'].apply(lambda comment: sum(1 for c in comment if c.isupper())) 5 data['caps_vs_length'] = data.apply(lambda row: float(row['capitals'])/float(row['total_length']), 6 axis=1) 7 data['num_words'] = data.lyric.str.count('\S+') 8 data['num_unique_words'] = data['lyric'].apply(lambda comment: len(set(w for w in comment.split()))) 9 data['words_vs_unique'] = data['num_unique_words'] / df['num_words']
1 sns.set(rc={'figure.figsize':(11.7,8.27)}) 2 y1 = data[data['year'] == 2017]['lyric'].str.len() 3 sns.distplot(y1, label='2017') 4 y2 = data[data['year'] == 2014]['lyric'].str.len() 5 sns.distplot(y2, label='2014') 6 y3 = data[data['year'] == 2012]['lyric'].str.len() 7 sns.distplot(y3, label='2012') 8 y4 = data[data['year'] == 2010]['lyric'].str.len() 9 sns.distplot(y4, label='2010') 10 y5 = data[data['year'] == 2008]['lyric'].str.len() 11 sns.distplot(y5, label='2008') 12 y6 = data[data['year'] == 2006]['lyric'].str.len() 13 sns.distplot(y6, label='2006') 14 plt.title('Year Wise - Lyrics Lenght Distribution (Without Preprocessing)') 15 plt.legend();
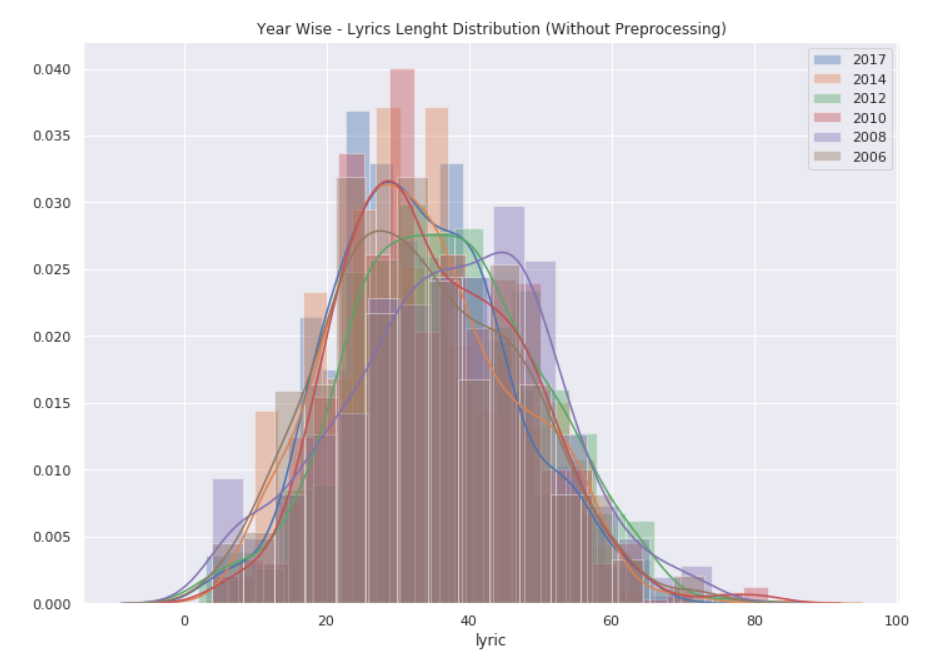
1 train = get_features(data) 2 data_pair = data.filter(['year','total_length','capitals','caps_vs_length','num_words','num_unique_words','words_vs_unique'],axis=1)
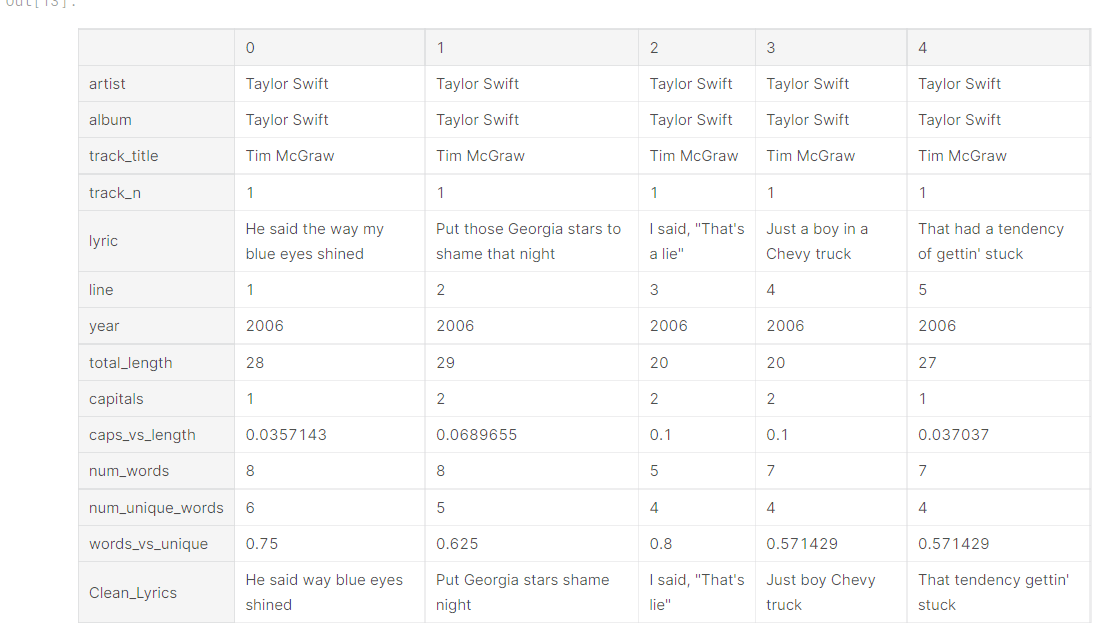
3 data.head().T
对timmcgraw这首歌进行配对,从配对图中可以发现单变量的分布和两个变量之间的关系。

对2007年五月到2017年五月发布的专辑里的歌进行统计长度操作,其中包括了单词数量,长度以及歌词中出现的首都单词进行统计:
1 sns.pairplot(data_pair,hue='year',palette="husl");

下面是对英语语言缩写进行扩展:
1 contraction_mapping_1 = {"ain't": "is not", "aren't": "are not","can't": "cannot", "'cause": "because", 2 "could've": "could have", "couldn't": "could not", "didn't": "did not", 3 "doesn't": "does not", "don't": "do not", "hadn't": "had not", "hasn't": "has not", 4 "haven't": "have not", "he'd": "he would","he'll": "he will", "he's": "he is", 5 "how'd": "how did", "how'd'y": "how do you", "how'll": "how will", "how's": "how is", 6 "I'd": "I would", "I'd've": "I would have", "I'll": "I will", "I'll've": "I will have", 7 "I'm": "I am", "I've": "I have", "i'd": "i would", "i'd've": "i would have", 8 "i'll": "i will", "i'll've": "i will have","i'm": "i am", "i've": "i have", 9 "isn't": "is not", "it'd": "it would", "it'd've": "it would have", "it'll": "it will", 10 "it'll've": "it will have","it's": "it is", "let's": "let us", "ma'am": "madam", 11 "mayn't": "may not", "might've": "might have","mightn't": "might not", 12 "mightn't've": "might not have", "must've": "must have", "mustn't": "must not", 13 "mustn't've": "must not have", "needn't": "need not", "needn't've": "need not have", 14 "o'clock": "of the clock", "oughtn't": "ought not", "oughtn't've": "ought not have", 15 "shan't": "shall not", "sha'n't": "shall not", "shan't've": "shall not have", 16 "she'd": "she would", "she'd've": "she would have", "she'll": "she will", 17 "she'll've": "she will have", "she's": "she is", "should've": "should have", 18 "shouldn't": "should not", "shouldn't've": "should not have", "so've": "so have", 19 "so's": "so as", "this's": "this is","that'd": "that would", 20 "that'd've": "that would have", "that's": "that is", "there'd": "there would", 21 "there'd've": "there would have", "there's": "there is", "here's": "here is", 22 "they'd": "they would", "they'd've": "they would have", "they'll": "they will", 23 "they'll've": "they will have", "they're": "they are", "they've": "they have", 24 "to've": "to have", "wasn't": "was not", "we'd": "we would", "we'd've": "we would have", 25 "we'll": "we will", "we'll've": "we will have", "we're": "we are", "we've": "we have", 26 "weren't": "were not", "what'll": "what will", "what'll've": "what will have", 27 "what're": "what are", "what's": "what is", "what've": "what have", "when's": "when is", 28 "when've": "when have", "where'd": "where did", "where's": "where is", "where've": "where have", 29 "who'll": "who will", "who'll've": "who will have", "who's": "who is", "who've": "who have", 30 "why's": "why is", "why've": "why have", "will've": "will have", "won't": "will not", 31 "won't've": "will not have", "would've": "would have", "wouldn't": "would not", 32 "wouldn't've": "would not have", "y'all": "you all", "y'all'd": "you all would", 33 "y'all'd've": "you all would have","y'all're": "you all are","y'all've": "you all have", 34 "you'd": "you would", "you'd've": "you would have", "you'll": "you will", 35 "you'll've": "you will have", "you're": "you are", "you've": "you have" , 36 "Isn't":"is not", "\u200b":"", "It's": "it is","I'm": "I am","don't":"do not","did't":"did not","ain't": "is not", "aren't": "are not","can't": "cannot", "'cause": "because", "could've": "could have", 37 "couldn't": "could not", "didn't": "did not", "doesn't": "does not", "don't": "do not", "hadn't": "had not", 38 "hasn't": "has not", "haven't": "have not", "he'd": "he would","he'll": "he will", "he's": "he is", "how'd": "how did", 39 "how'd'y": "how do you", "how'll": "how will", "how's": "how is", "I'd": "I would", "I'd've": "I would have", "I'll": "I will", 40 "I'll've": "I will have","I'm": "I am", "I've": "I have", "i'd": "i would", "i'd've": "i would have", "i'll": "i will", 41 "i'll've": "i will have","i'm": "i am", "i've": "i have", "isn't": "is not", "it'd": "it would", "it'd've": "it would have", 42 "it'll": "it will", "it'll've": "it will have","it's": "it is", "let's": "let us", "ma'am": "madam", "mayn't": "may not", 43 "might've": "might have","mightn't": "might not","mightn't've": "might not have", "must've": "must have", 44 "mustn't": "must not", "mustn't've": "must not have", "needn't": "need not", "needn't've": "need not have", 45 "o'clock": "of the clock", "oughtn't": "ought not", "oughtn't've": "ought not have", "shan't": "shall not", 46 "sha'n't": "shall not", "shan't've": "shall not have", "she'd": "she would", "she'd've": "she would have", 47 "she'll": "she will", "she'll've": "she will have", "she's": "she is", "should've": "should have", 48 "shouldn't": "should not", "shouldn't've": "should not have", "so've": "so have","so's": "so as", 49 "this's": "this is","that'd": "that would", "that'd've": "that would have", "that's": "that is", 50 "there'd": "there would", "there'd've": "there would have", "there's": "there is", 51 "here's": "here is","they'd": "they would", "they'd've": "they would have", "they'll": "they will", "they'll've": "they will have", 52 "they're": "they are", "they've": "they have", "to've": "to have", "wasn't": "was not", "we'd": "we would", "we'd've": "we would have", 53 "we'll": "we will", "we'll've": "we will have", "we're": "we are", "we've": "we have", "weren't": "were not", "what'll": "what will", 54 "what'll've": "what will have", "what're": "what are", "what's": "what is", "what've": "what have", "when's": "when is", "when've": "when have", 55 "where'd": "where did", "where's": "where is", "where've": "where have", "who'll": "who will", "who'll've": "who will have", "who's": "who is", 56 "who've": "who have", "why's": "why is", "why've": "why have", "will've": "will have", "won't": "will not", "won't've": "will not have", 57 "would've": "would have", "wouldn't": "would not", "wouldn't've": "would not have", "y'all": "you all", "y'all'd": "you all would","y'all'd've": "you all would have","y'all're": "you all are","y'all've": "you all have","you'd": "you would", "you'd've": "you would have", "you'll": "you will", "you'll've": "you will have", "you're": "you are", "you've": "you have" }
1 def clean_contractions(text, mapping): 2 specials = ["’", "‘", "´", "`"] 3 for s in specials: 4 text = text.replace(s, "'") 5 text = ' '.join([mapping[t] if t in mapping else t for t in text.split(" ")]) 6 return text
1 def get_features(df): 2 data['Clean_Lyrics'] = data['Clean_Lyrics'].apply(lambda x:str(x)) 3 data['total_length'] = data['Clean_Lyrics'].apply(len) 4 data['capitals'] = data['Clean_Lyrics'].apply(lambda comment: sum(1 for c in comment if c.isupper())) 5 data['caps_vs_length'] = data.apply(lambda row: float(row['capitals'])/float(row['total_length']), 6 axis=1) 7 data['num_words'] = data.lyric.str.count('\S+') 8 data['num_unique_words'] = data['Clean_Lyrics'].apply(lambda comment: len(set(w for w in comment.split()))) 9 data['words_vs_unique'] = data['num_unique_words'] / df['num_words'] 10 return df

下面是对上面还没有预处理的年度歌词长度分布进行预处理操作,以下是预处理代码及其结果:
1 sns.set(rc={'figure.figsize':(11.7,8.27)}) 2 y1 = data[data['year'] == 2017]['Clean_Lyrics'].str.len() 3 sns.distplot(y1, label='2017') 4 y2 = data[data['year'] == 2014]['Clean_Lyrics'].str.len() 5 sns.distplot(y2, label='2014') 6 y3 = data[data['year'] == 2012]['Clean_Lyrics'].str.len() 7 sns.distplot(y3, label='2012') 8 y4 = data[data['year'] == 2010]['Clean_Lyrics'].str.len() 9 sns.distplot(y4, label='2010') 10 y5 = data[data['year'] == 2008]['Clean_Lyrics'].str.len() 11 sns.distplot(y5, label='2008') 12 y6 = data[data['year'] == 2006]['Clean_Lyrics'].str.len() 13 sns.distplot(y6, label='2006') 14 plt.title('Year Wise - Lyrics Lenght Distribution (After Preprocessing)') 15 plt.legend();
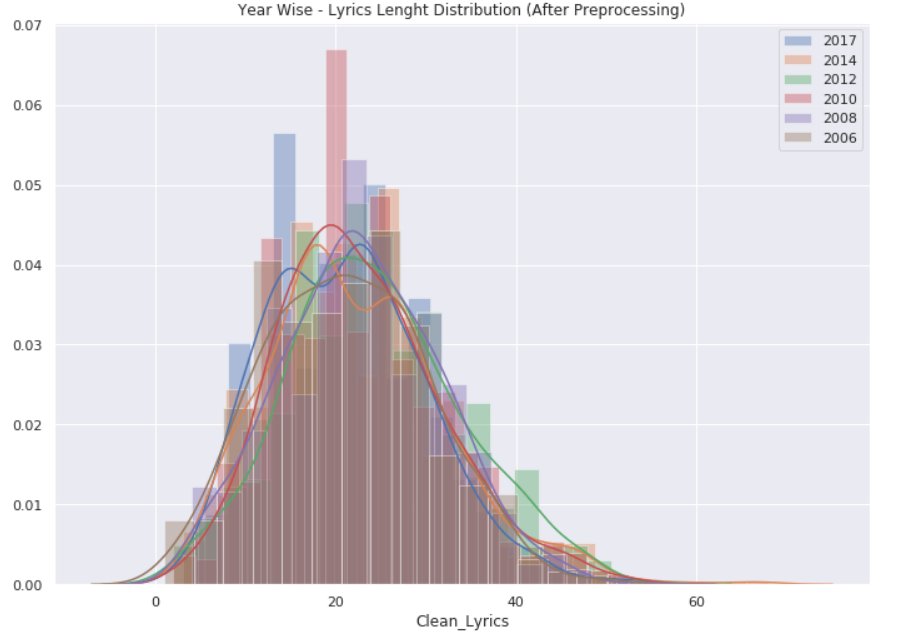
统计各年歌曲中歌词的长度。
1 def ngram_extractor(text, n_gram): 2 token = [token for token in text.lower().split(" ") if token != "" if token not in STOPWORDS] 3 ngrams = zip(*[token[i:] for i in range(n_gram)]) 4 return [" ".join(ngram) for ngram in ngrams] 5 6 # Function to generate a dataframe with n_gram and top max_row frequencies 7 def generate_ngrams(df, col, n_gram, max_row): 8 temp_dict = defaultdict(int) 9 for question in df[col]: 10 for word in ngram_extractor(question, n_gram): 11 temp_dict[word] += 1 12 temp_df = pd.DataFrame(sorted(temp_dict.items(), key=lambda x: x[1])[::-1]).head(max_row) 13 temp_df.columns = ["word", "wordcount"] 14 return temp_df 15 16 def comparison_plot(df_1,df_2,col_1,col_2, space): 17 fig, ax = plt.subplots(1, 2, figsize=(20,10)) 18 19 sns.barplot(x=col_2, y=col_1, data=df_1, ax=ax[0], color="skyblue") 20 sns.barplot(x=col_2, y=col_1, data=df_2, ax=ax[1], color="skyblue") 21 22 ax[0].set_xlabel('Word count', size=14, color="green") 23 ax[0].set_ylabel('Words', size=18, color="green") 24 ax[0].set_title('Top words in 2017 Lyrics', size=18, color="green") 25 26 ax[1].set_xlabel('Word count', size=14, color="green") 27 ax[1].set_ylabel('Words', size=18, color="green") 28 ax[1].set_title('Top words in 2008 Lyrics', size=18, color="green") 29 30 fig.subplots_adjust(wspace=space) 31 32 plt.show()
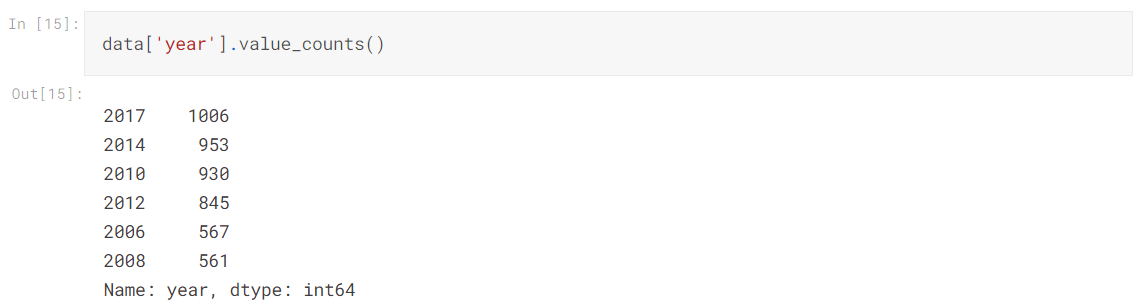
Ngram歌词分析2017 vs 2008
1 Lyrics_2017 = generate_ngrams(train[train["year"]==2017], 'Clean_Lyrics', 1, 10) 2 Lyrics_2008 = generate_ngrams(data[data["year"]==2008], 'Clean_Lyrics', 1, 10) 3 comparison_plot(Lyrics_2017,Lyrics_2008,'word','wordcount', 0.25)

Bigram歌词分析2017 vs 2008
1 Lyrics_2017 = generate_ngrams(train[train["year"]==2017], 'Clean_Lyrics', 2, 10) 2 Lyrics_2008 = generate_ngrams(data[data["year"]==2008], 'Clean_Lyrics', 2, 10) 3 comparison_plot(Lyrics_2017,Lyrics_2008,'word','wordcount', 0.25)

Trigram歌词分析2017 vs 2008
1 Lyrics_2017 = generate_ngrams(train[train["year"]==2017], 'Clean_Lyrics', 3, 10) 2 Lyrics_2008 = generate_ngrams(data[data["year"]==2008], 'Clean_Lyrics', 3, 10) 3 comparison_plot(Lyrics_2017,Lyrics_2008,'word','wordcount', 0.25)
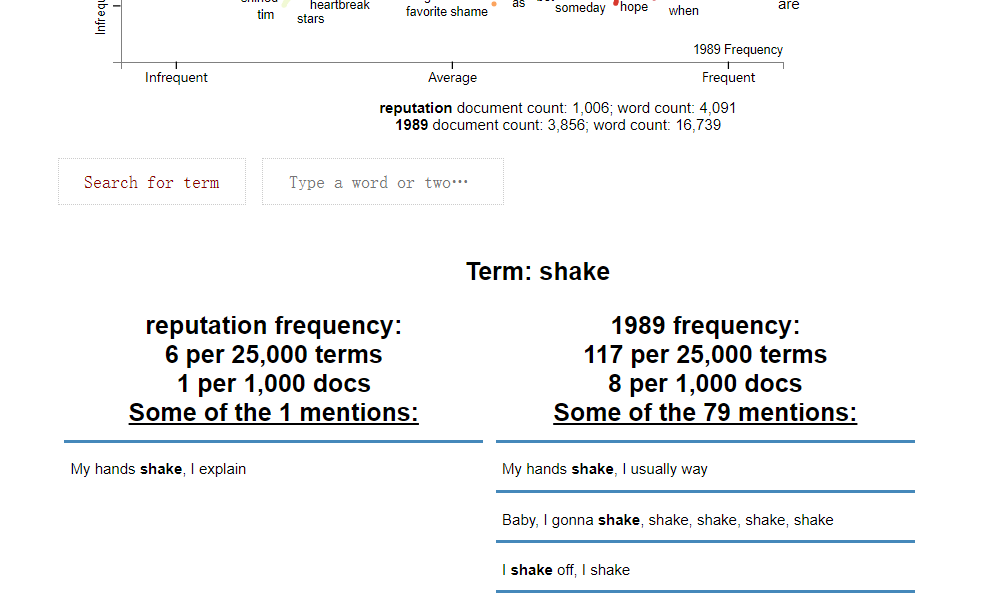
散点文本,找到空间清晰地标记数百个点。用于基于查询的可视化。
1 import scattertext as st 2 nlp = spacy.load('en',disable_pipes=["tagger","ner"]) 3 data['parsed'] = data.Clean_Lyrics.apply(nlp) 4 corpus = st.CorpusFromParsedDocuments(data, 5 category_col='album', 6 parsed_col='parsed').build() 7 html = st.produce_scattertext_explorer(corpus, 8 category='reputation', 9 category_name='reputation', 10 not_category_name='1989', 11 width_in_pixels=600, 12 minimum_term_frequency=5, 13 term_significance = st.LogOddsRatioUninformativeDirichletPrior(), 14 ) 15 filename = "reputation-vs-1989.html" 16 open(filename, 'wb').write(html.encode('utf-8')) 17 IFrame(src=filename, width = 800, height=700)

四、完整代码如下
1 import numpy as np # 线性代数 2 2 import pandas as pd # 数据处理,CSV文件I/O(例如pd.read_CSV) 3 3 4 4 # 输入数据文件在“../Input/”目录中可用。 5 5 6 6 #运行操作将列出输入目录中的文件 7 7 import pandas as pd 8 8 import matplotlib.pyplot as plt 9 9 import seaborn as sns 10 10 %matplotlib inline 11 11 import os 12 12 import pandas as pd 13 13 import datetime as dt 14 14 import numpy as np 15 15 from IPython.core.interactiveshell import InteractiveShell 16 16 InteractiveShell.ast_node_interactivity = "all" 17 17 import matplotlib.pyplot as plt 18 18 plt.rcParams['figure.figsize'] = [16, 10] 19 19 plt.rcParams['font.size'] = 14 20 20 width = 0.75 21 21 from wordcloud import WordCloud, STOPWORDS 22 22 from nltk.corpus import stopwords 23 23 from collections import defaultdict 24 24 import string 25 25 from sklearn.preprocessing import StandardScaler 26 26 import seaborn as sns 27 27 sns.set_palette(sns.color_palette('tab20', 20)) 28 28 import plotly.offline as py 29 29 py.init_notebook_mode(connected=True) 30 30 import plotly.graph_objs as go 31 31 from datetime import date, timedelta 32 32 import operator 33 33 import re 34 34 import spacy 35 35 from spacy import displacy 36 36 from spacy.util import minibatch, compounding 37 37 import spacy #load spacy 38 38 nlp = spacy.load("en", disable=['parser', 'tagger', 'ner']) 39 39 #stops=停止语。单词(“english”) 40 40 from tqdm import tqdm 41 41 from collections import Counter 42 42 import matplotlib.pyplot as plt 43 43 %matplotlib inline 44 44 import warnings 45 45 warnings.filterwarnings('ignore') 46 46 import os 47 47 print(os.listdir("../input")) 48 48 from IPython.display import IFrame 49 49 from IPython.core.display import display, HTML 50 50 #写入当前目录的任何结果都将保存为输出。 51 data = pd.read_csv("../input/taylor_swift_lyrics.csv",encoding = "latin1") 52 data.head() 53 def get_features(df): 54 data['lyric'] = data['lyric'].apply(lambda x:str(x)) 55 data['total_length'] = data['lyric'].apply(len) 56 data['capitals'] = data['lyric'].apply(lambda comment: sum(1 for c in comment if c.isupper())) 57 data['caps_vs_length'] = data.apply(lambda row: float(row['capitals'])/float(row['total_length']), 58 axis=1) 59 data['num_words'] = data.lyric.str.count('\S+') 60 data['num_unique_words'] = data['lyric'].apply(lambda comment: len(set(w for w in comment.split()))) 61 data['words_vs_unique'] = data['num_unique_words'] / df['num_words'] 62 return df 63 sns.set(rc={'figure.figsize':(11.7,8.27)}) 64 y1 = data[data['year'] == 2017]['lyric'].str.len() 65 sns.distplot(y1, label='2017') 66 y2 = data[data['year'] == 2014]['lyric'].str.len() 67 sns.distplot(y2, label='2014') 68 y3 = data[data['year'] == 2012]['lyric'].str.len() 69 sns.distplot(y3, label='2012') 70 y4 = data[data['year'] == 2010]['lyric'].str.len() 71 sns.distplot(y4, label='2010') 72 y5 = data[data['year'] == 2008]['lyric'].str.len() 73 sns.distplot(y5, label='2008') 74 y6 = data[data['year'] == 2006]['lyric'].str.len() 75 sns.distplot(y6, label='2006') 76 plt.title('Year Wise - Lyrics Lenght Distribution (Without Preprocessing)') 77 plt.legend(); 78 train = get_features(data) 79 data_pair = data.filter(['year','total_length','capitals','caps_vs_length','num_words','num_unique_words','words_vs_unique'],axis=1) 80 data.head().T 81 sns.pairplot(data_pair,hue='year',palette="husl"); 82 contraction_mapping_1 = {"ain't": "is not", "aren't": "are not","can't": "cannot", "'cause": "because", 83 "could've": "could have", "couldn't": "could not", "didn't": "did not", 84 "doesn't": "does not", "don't": "do not", "hadn't": "had not", "hasn't": "has not", 85 "haven't": "have not", "he'd": "he would","he'll": "he will", "he's": "he is", 86 "how'd": "how did", "how'd'y": "how do you", "how'll": "how will", "how's": "how is", 87 "I'd": "I would", "I'd've": "I would have", "I'll": "I will", "I'll've": "I will have", 88 "I'm": "I am", "I've": "I have", "i'd": "i would", "i'd've": "i would have", 89 "i'll": "i will", "i'll've": "i will have","i'm": "i am", "i've": "i have", 90 "isn't": "is not", "it'd": "it would", "it'd've": "it would have", "it'll": "it will", 91 "it'll've": "it will have","it's": "it is", "let's": "let us", "ma'am": "madam", 92 "mayn't": "may not", "might've": "might have","mightn't": "might not", 93 "mightn't've": "might not have", "must've": "must have", "mustn't": "must not", 94 "mustn't've": "must not have", "needn't": "need not", "needn't've": "need not have", 95 "o'clock": "of the clock", "oughtn't": "ought not", "oughtn't've": "ought not have", 96 "shan't": "shall not", "sha'n't": "shall not", "shan't've": "shall not have", 97 "she'd": "she would", "she'd've": "she would have", "she'll": "she will", 98 "she'll've": "she will have", "she's": "she is", "should've": "should have", 99 "shouldn't": "should not", "shouldn't've": "should not have", "so've": "so have", 100 "so's": "so as", "this's": "this is","that'd": "that would", 101 "that'd've": "that would have", "that's": "that is", "there'd": "there would", 102 "there'd've": "there would have", "there's": "there is", "here's": "here is", 103 "they'd": "they would", "they'd've": "they would have", "they'll": "they will", 104 "they'll've": "they will have", "they're": "they are", "they've": "they have", 105 "to've": "to have", "wasn't": "was not", "we'd": "we would", "we'd've": "we would have", 106 "we'll": "we will", "we'll've": "we will have", "we're": "we are", "we've": "we have", 107 "weren't": "were not", "what'll": "what will", "what'll've": "what will have", 108 "what're": "what are", "what's": "what is", "what've": "what have", "when's": "when is", 109 "when've": "when have", "where'd": "where did", "where's": "where is", "where've": "where have", 110 "who'll": "who will", "who'll've": "who will have", "who's": "who is", "who've": "who have", 111 "why's": "why is", "why've": "why have", "will've": "will have", "won't": "will not", 112 "won't've": "will not have", "would've": "would have", "wouldn't": "would not", 113 "wouldn't've": "would not have", "y'all": "you all", "y'all'd": "you all would", 114 "y'all'd've": "you all would have","y'all're": "you all are","y'all've": "you all have", 115 "you'd": "you would", "you'd've": "you would have", "you'll": "you will", 116 "you'll've": "you will have", "you're": "you are", "you've": "you have" , 117 "Isn't":"is not", "\u200b":"", "It's": "it is","I'm": "I am","don't":"do not","did't":"did not","ain't": "is not", "aren't": "are not","can't": "cannot", "'cause": "because", "could've": "could have", 118 "couldn't": "could not", "didn't": "did not", "doesn't": "does not", "don't": "do not", "hadn't": "had not", 119 "hasn't": "has not", "haven't": "have not", "he'd": "he would","he'll": "he will", "he's": "he is", "how'd": "how did", 120 "how'd'y": "how do you", "how'll": "how will", "how's": "how is", "I'd": "I would", "I'd've": "I would have", "I'll": "I will", 121 "I'll've": "I will have","I'm": "I am", "I've": "I have", "i'd": "i would", "i'd've": "i would have", "i'll": "i will", 122 "i'll've": "i will have","i'm": "i am", "i've": "i have", "isn't": "is not", "it'd": "it would", "it'd've": "it would have", 123 "it'll": "it will", "it'll've": "it will have","it's": "it is", "let's": "let us", "ma'am": "madam", "mayn't": "may not", 124 "might've": "might have","mightn't": "might not","mightn't've": "might not have", "must've": "must have", 125 "mustn't": "must not", "mustn't've": "must not have", "needn't": "need not", "needn't've": "need not have", 126 "o'clock": "of the clock", "oughtn't": "ought not", "oughtn't've": "ought not have", "shan't": "shall not", 127 "sha'n't": "shall not", "shan't've": "shall not have", "she'd": "she would", "she'd've": "she would have", 128 "she'll": "she will", "she'll've": "she will have", "she's": "she is", "should've": "should have", 129 "shouldn't": "should not", "shouldn't've": "should not have", "so've": "so have","so's": "so as", 130 "this's": "this is","that'd": "that would", "that'd've": "that would have", "that's": "that is", 131 "there'd": "there would", "there'd've": "there would have", "there's": "there is", 132 "here's": "here is","they'd": "they would", "they'd've": "they would have", "they'll": "they will", "they'll've": "they will have", 133 "they're": "they are", "they've": "they have", "to've": "to have", "wasn't": "was not", "we'd": "we would", "we'd've": "we would have", 134 "we'll": "we will", "we'll've": "we will have", "we're": "we are", "we've": "we have", "weren't": "were not", "what'll": "what will", 135 "what'll've": "what will have", "what're": "what are", "what's": "what is", "what've": "what have", "when's": "when is", "when've": "when have", 136 "where'd": "where did", "where's": "where is", "where've": "where have", "who'll": "who will", "who'll've": "who will have", "who's": "who is", 137 "who've": "who have", "why's": "why is", "why've": "why have", "will've": "will have", "won't": "will not", "won't've": "will not have", 138 "would've": "would have", "wouldn't": "would not", "wouldn't've": "would not have", "y'all": "you all", "y'all'd": "you all would","y'all'd've": "you all would have","y'all're": "you all are","y'all've": "you all have","you'd": "you would", "you'd've": "you would have", "you'll": "you will", "you'll've": "you will have", "you're": "you are", "you've": "you have" } 139 def clean_contractions(text, mapping): 140 specials = ["’", "‘", "´", "`"] 141 for s in specials: 142 text = text.replace(s, "'") 143 text = ' '.join([mapping[t] if t in mapping else t for t in text.split(" ")]) 144 return text 145 def get_features(df): 146 data['Clean_Lyrics'] = data['Clean_Lyrics'].apply(lambda x:str(x)) 147 data['total_length'] = data['Clean_Lyrics'].apply(len) 148 data['capitals'] = data['Clean_Lyrics'].apply(lambda comment: sum(1 for c in comment if c.isupper())) 149 data['caps_vs_length'] = data.apply(lambda row: float(row['capitals'])/float(row['total_length']), 150 axis=1) 151 data['num_words'] = data.lyric.str.count('\S+') 152 data['num_unique_words'] = data['Clean_Lyrics'].apply(lambda comment: len(set(w for w in comment.split()))) 153 data['words_vs_unique'] = data['num_unique_words'] / df['num_words'] 154 return df 155 data['Clean_Lyrics'] = data['lyric'].apply(lambda x: clean_contractions(x, contraction_mapping_1)) 156 #Stopwords 157 data['Clean_Lyrics'] = data['Clean_Lyrics'].apply(lambda x: ' '.join([word for word in x.split() if word not in (STOPWORDS)])) 158 #Re-calculate the features 159 train = get_features(data) 160 data.head().T 161 sns.set(rc={'figure.figsize':(11.7,8.27)}) 162 y1 = data[data['year'] == 2017]['Clean_Lyrics'].str.len() 163 sns.distplot(y1, label='2017') 164 y2 = data[data['year'] == 2014]['Clean_Lyrics'].str.len() 165 sns.distplot(y2, label='2014') 166 y3 = data[data['year'] == 2012]['Clean_Lyrics'].str.len() 167 sns.distplot(y3, label='2012') 168 y4 = data[data['year'] == 2010]['Clean_Lyrics'].str.len() 169 sns.distplot(y4, label='2010') 170 y5 = data[data['year'] == 2008]['Clean_Lyrics'].str.len() 171 sns.distplot(y5, label='2008') 172 y6 = data[data['year'] == 2006]['Clean_Lyrics'].str.len() 173 sns.distplot(y6, label='2006') 174 plt.title('Year Wise - Lyrics Lenght Distribution (After Preprocessing)') 175 plt.legend(); 176 def ngram_extractor(text, n_gram): 177 token = [token for token in text.lower().split(" ") if token != "" if token not in STOPWORDS] 178 ngrams = zip(*[token[i:] for i in range(n_gram)]) 179 return [" ".join(ngram) for ngram in ngrams] 180 181 # Function to generate a dataframe with n_gram and top max_row frequencies 182 def generate_ngrams(df, col, n_gram, max_row): 183 temp_dict = defaultdict(int) 184 for question in df[col]: 185 for word in ngram_extractor(question, n_gram): 186 temp_dict[word] += 1 187 temp_df = pd.DataFrame(sorted(temp_dict.items(), key=lambda x: x[1])[::-1]).head(max_row) 188 temp_df.columns = ["word", "wordcount"] 189 return temp_df 190 191 def comparison_plot(df_1,df_2,col_1,col_2, space): 192 fig, ax = plt.subplots(1, 2, figsize=(20,10)) 193 194 sns.barplot(x=col_2, y=col_1, data=df_1, ax=ax[0], color="skyblue") 195 sns.barplot(x=col_2, y=col_1, data=df_2, ax=ax[1], color="skyblue") 196 197 ax[0].set_xlabel('Word count', size=14, color="green") 198 ax[0].set_ylabel('Words', size=18, color="green") 199 ax[0].set_title('Top words in 2017 Lyrics', size=18, color="green") 200 201 ax[1].set_xlabel('Word count', size=14, color="green") 202 ax[1].set_ylabel('Words', size=18, color="green") 203 ax[1].set_title('Top words in 2008 Lyrics', size=18, color="green") 204 205 fig.subplots_adjust(wspace=space) 206 207 plt.show() 208 Lyrics_2017 = generate_ngrams(train[train["year"]==2017], 'Clean_Lyrics', 1, 10) 209 Lyrics_2008 = generate_ngrams(data[data["year"]==2008], 'Clean_Lyrics', 1, 10) 210 comparison_plot(Lyrics_2017,Lyrics_2008,'word','wordcount', 0.25) 211 Lyrics_2017 = generate_ngrams(train[train["year"]==2017], 'Clean_Lyrics', 2, 10) 212 Lyrics_2008 = generate_ngrams(data[data["year"]==2008], 'Clean_Lyrics', 2, 10) 213 comparison_plot(Lyrics_2017,Lyrics_2008,'word','wordcount', 0.25) 214 Lyrics_2017 = generate_ngrams(train[train["year"]==2017], 'Clean_Lyrics', 3, 10) 215 Lyrics_2008 = generate_ngrams(data[data["year"]==2008], 'Clean_Lyrics', 3, 10) 216 comparison_plot(Lyrics_2017,Lyrics_2008,'word','wordcount', 0.25) 217 import scattertext as st 218 nlp = spacy.load('en',disable_pipes=["tagger","ner"]) 219 data['parsed'] = data.Clean_Lyrics.apply(nlp) 220 corpus = st.CorpusFromParsedDocuments(data, 221 category_col='album', 222 parsed_col='parsed').build() 223 html = st.produce_scattertext_explorer(corpus, 224 category='reputation', 225 category_name='reputation', 226 not_category_name='1989', 227 width_in_pixels=600, 228 minimum_term_frequency=5, 229 term_significance = st.LogOddsRatioUninformativeDirichletPrior(), 230 ) 231 filename = "reputation-vs-1989.html" 232 open(filename, 'wb').write(html.encode('utf-8')) 233 IFrame(src=filename, width = 800, height=700)
五、总结
感谢授课老师对我们两个学期的教授,让我知道了:
1、数据清洗是数据分析的基础。一份基础数据呈现于我们面前时,我们应该仔细观察这份基础数据表格是否存在隐患,比如空格、强制换行、首字母是否需要大小写、文字数字格式是否正确,这对于我们后续的数据分析很关键,我们一般同Excel的查找、替换、更改数据格式进行清洗,也可以采用Power Query进行数据清洗。/2、数据整理是数据分析的深入。在基础数据清洗完成后要根据数据分析的需要对数据进行整理。
2、数据呈现是数据分析的重点。数据有多种呈现形式,我们应根据所掌握的工具以及分析需要选择适合企业的数据呈现的方式,我们不追求花哨的呈现,应追求适合自己的呈现方式。
3、数据分析是核心。我们所有的工作都是为了围绕这数据分析展开,只有将企业的数据分析准确,才能找到企业的薄弱点加以改进,
4、对于这门两个学期学习的课程以及教授对我们说过的一样,就像学习其他编程语言或者是学习一门外语 ,我们应该从Python的基础语法开始学习 ,了解什么是Python的变量 什么是循环 什么是函数,什么是模块。类等等。总之,基础是学习以后高级开发的基石。最重要的是明白学python的目的是什么,是数据挖掘还是想刷个火车票啥的,是机器学习还是搞个小脚本装下,是想成为厉害的harker还是强大的web开发者。只有明白了目的,才有学下去的动力。根据自己的目标去深耕。知识的学习都是由浅入深的,先掌握基础,再根据自己的目标去练习,才会有效果。