AI模型训练主要使用GPU的算力,GPU,显卡这些知识大家都懂的,还是简单说一下GPU吧:GPU是显卡的核心部分,GPU承担着与 CPU 不同的定位和功能,芯片设计思路也完全不同,GPU Core 小而且多,它不承担系统管理、调度的功能,完全专注于使用(大量的)小核心并行化地执行运算。
GPU的几个主要用途:
1、处理图形渲染,包括游戏、视频和动画。
2、加速通用计算,如深度学习、科学模拟等。
3、高度并行处理,适用于大规模数据处理和处理密集型任务。
这里我们把NVIDIA显示芯片的显卡称为N卡,而将采用AMD显示芯片的显卡称为A卡,这两种显卡是目前的主流
Nvidia有个很有名次的编程框架CUDA,但是记住CUDA Core是商业营销概念,不能单纯用 CUDA Core的数量比较显卡性能
Nvidia 中大名鼎鼎的就是A100了,下面看看A100的架构
128个SM(流式多处理器)
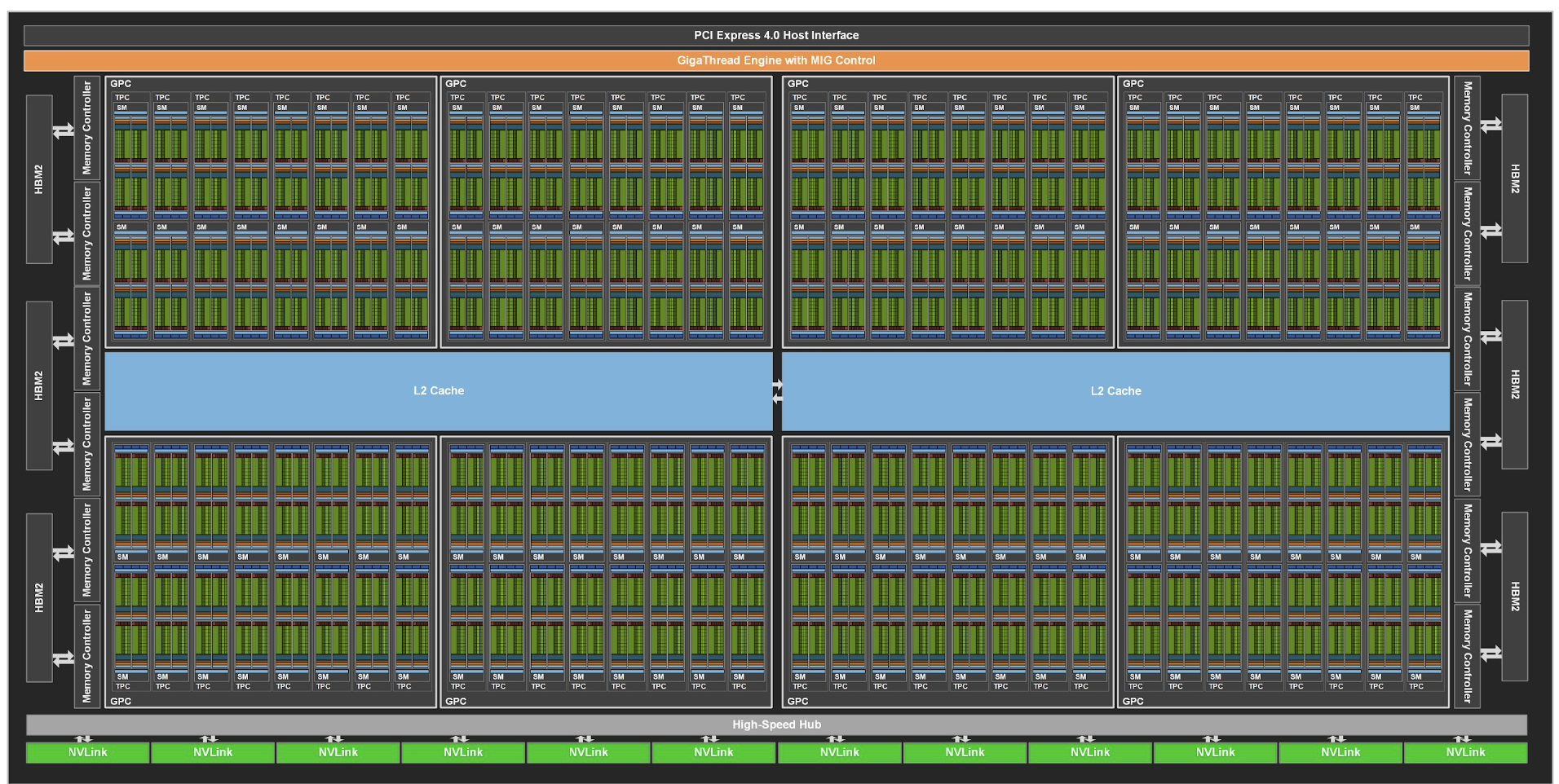
流式多处理器包含TensorCore,TensorCore专门用于AI需要的矩阵运算

再探谈国产的华为昇腾AI芯片

华为昇腾AI芯片采用自研达芬奇架构,集成了2个AI Core,是昇腾AI芯片的计算核心,主要负责执行矩阵, 向量, 标量计算密集的算子任务,华为昇腾AI芯片对TensorFlow、PyTorch这些深度学习框架都支持。
就应用场景来说,升腾910主要被用于较小规模的AI任务,如人脸识别、图像分类和目标检测,适合嵌入式设备或中小规模的数据中心。支持国产,过几天会整理国产大模型ChatGLM,在升腾910上的部署、推理和训练的文章。
英伟达A100主要被用于大规模的数据中心和企业级应用,如机器学习、人工智能和深度学习等方面的高强度计算。它可以处理大规模的数据集,提供更高的能力和对多任务并发工作负载的支持。