BeautifulSoup库解析器
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,'html.parser') | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk,'lxml') | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,'xml') | pip install lxml |
| html5lib的解析器 | BeautifulSoup(mk,'htmlslib') | pip install html5lib |
实例展示BeautifulSoup的基本用法:
>>> from bs4 import BeautifulSoup
>>> import requests
>>> r = requests.get("http://python123.io/ws/demo.html")
>>> demo = r.text
>>> demo
'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p class="title"><b>The demo python introduces several python courses.</b></p>\r\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\r\n</body></html>'
>>> soup = BeautifulSoup(demo,"html.parser")
>>> soup.title #获取标题
<title>This is a python demo page</title>
>>> soup.a #获取a标签
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
>>> soup.title.string
'This is a python demo page'
>>> soup.prettify() #输出html标准格式内容
'<html>\n <head>\n <title>\n This is a python demo page\n </title>\n </head>\n <body>\n <p class="title">\n <b>\n The demo python introduces several python courses.\n </b>\n </p>\n <p class="course">\n Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\n <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">\n Basic Python\n </a>\n and\n <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">\n Advanced Python\n </a>\n .\n </p>\n </body>\n</html>'
>>> soup.a.name #每个<tag>都有自己的名字,通过<tag>.name获取
'a'
>>> soup.p.name
'p'
>>> tag = soup.a
>>> tag.attrs
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
>>> tag.attrs['class']
['py1']
>>> tag.attrs['href']
'http://www.icourse163.org/course/BIT-268001'
>>> type(tag.attrs)
<class 'dict'>
>>> type(tag)
<class 'bs4.element.Tag'>
>>>
6.5 标签树的遍历

标签树的下行遍历

标签树的上行遍历:遍历所有先辈节点,包括soup本身

标签树的平行遍历:同一个父节点的各节点间

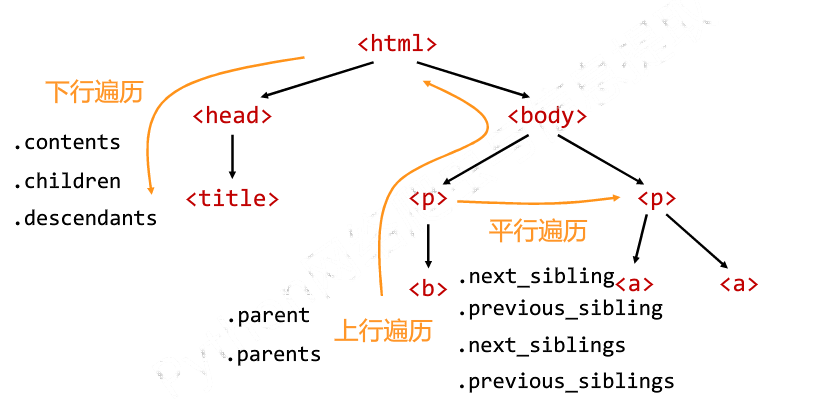
实例演示:
from bs4 import BeautifulSoup
import requests
demo = requests.get("http://python123.io/ws/demo.html").text
soup = BeautifulSoup(demo,"html.parser")
#标签树的上行遍历
print("遍历儿子节点:\n")
for child in soup.body.children:
print(child)
print("遍历子孙节点:\n")
for child1 in soup.body.descendants:
print(child1)
print(soup.title.parent)
print(soup.html.parent)
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
#标签树的平行遍历
print(soup.a.next_sibling)
print(soup.a.next_sibling.next_sibling)
print(soup.a.previous_sibling)
从网页上获得小说章节目录并找到正文网页和标题
data=[]
soup=BeautifulSoup(res.text,'html.parser')
for dd in soup.find_all("dd"):
link=dd.find("a")
if not link:
continue
data.append(("{}{}".format(url,link['href']),link.get_text()))
return data