
"""
.-''-.
.--. _..._ .' .-. )
|__| .' '. / .' / /
.--..-,.--. . .-. . (_/ / /
| || .-. | | ' ' | / /
| || | | | _ _ | | | | / / _ _
| || | | || ' / | | | | | . ' | ' / |
| || | '-.' | .' | | | | | / / _.-').' | .' |
|__|| | / | / | | | | | .' ' _.'.-'' / | / |
| | | `'. | | | | | / /.-'_.' | `'. |
|_| ' .'| '/| | | | / _.' ' .'| '/
`-' `--' '--' '--'( _.-' `-' `--'
Created on 2023/4/10 20:49.
@Author: haifei
"""
import time, os
from pyfiglet import Figlet
from urllib import request
from lxml import etree
import socket
# https://blog.csdn.net/sfwqwfew/article/details/127880014
socket.setdefaulttimeout(10.0) # 设置全局的socket超时
# 站长素材:图片-人物-情侣,前10页
# https://sc.chinaz.com/tupian/qinglvtupian.html 第一页
# https://sc.chinaz.com/tupian/qinglvtupian_page.html 第page页
def hello_message():
print('*' * 100)
f = Figlet()
print(f.renderText('irun2u'))
print('Name: 站长素材图片下载器')
print('Verson: 1.0')
print('Index: http://www.irun2u.top')
print('*' * 100)
def legal(s):
if (s[0] != '+') and (s[0] != '-'): # 无符号位,默认为正数
return s
else: # 有符号位,对去掉符号位的num进行检验
return s[1:]
def get_page():
input_start = input('请输入起始页码:')
input_end = input('请输入结束页码:')
if not legal(input_start).isdigit() or not legal(input_end).isdigit():
print('[note: 输入页码必须为数字]')
# raise Exception('[note: 输入页码必须为数字]')
else:
page_start = int(input_start)
page_end = int(input_end)
if (page_start < 0) or (page_end < 0):
print('[note: 页码数必须大于0]')
# raise Exception('[note: 输入页码必须为数字]')
elif page_start > page_end:
print('[note: 起始页码必须小于等于结束页码]')
# raise Exception('[note: 输入页码必须为数字]')
else:
return [page_start, page_end]
def create_request(page):
if page == 1:
base_url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
base_url = 'https://sc.chinaz.com/tupian/qinglvtupian_'+ str(page) +'.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
_request = request.Request(url=base_url, headers=headers)
return _request
def get_content(myrequest):
response = request.urlopen(myrequest)
content = response.read().decode('utf-8')
return content
def download_data(page, mycontent):
# 下载图片 urllib.request.urlretrieve('图片地址','文件的名字')
tree = etree.HTML(mycontent)
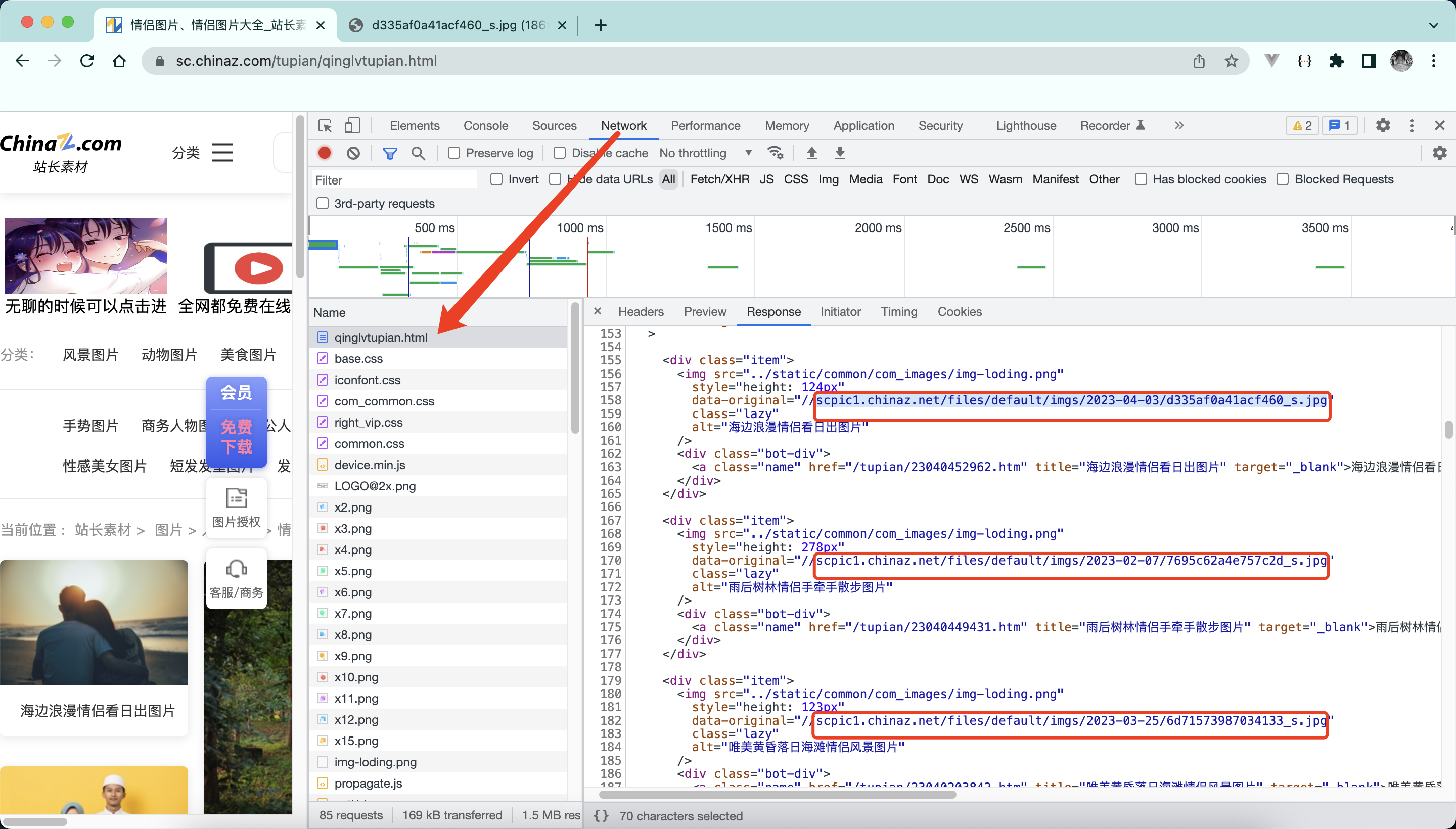
name_list = tree.xpath('//div[@class="item"]/img/@alt')
src_list = tree.xpath('//div[@class="item"]/img/@data-original')
# 一般设计图片的网站都会进行懒加载,等到真正可以看到图片时,src2属性会自动变成img标签的src属性
if len(name_list) == len(src_list):
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
# print(name, src)
myurl = 'https:' + src
mypath = './download/' + str(page) + '/'
if not os.path.exists(mypath):
os.makedirs(mypath)
myfilename = mypath + name + '.jpg'
print('正在下载第%d页第%d张图片:%s' % (page, i+1, myfilename))
request.urlretrieve(url=myurl, filename=myfilename)
if __name__ == '__main__':
start = time.time()
hello_message()
pages = get_page()
if pages is not None:
page_start = pages[0]
page_end = pages[1]
for page in range(page_start, page_end + 1):
print('开始下载第'+ str(page) +'页')
myrequest = create_request(page) # 1、请求对象定制
mycontent = get_content(myrequest) # 2、发送请求获取网页源码
download_data(page, mycontent) # 3、下载数据到本地
print('download finished')
print('It takes', time.time() - start, "seconds.")