1、《Robust RGB-D Fusion for Saliency Detection》
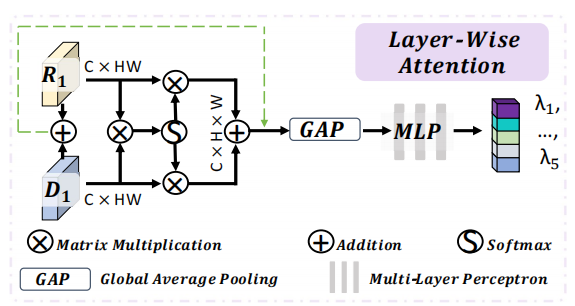
(1)引入了一种分层注意力(LWA)来自动调整不同层之间的深度图贡献,动态确定每层的具体融合策略。
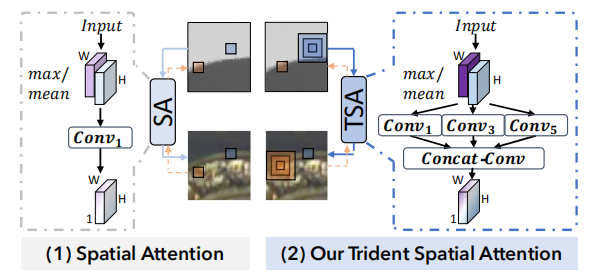
(2)设计了一个三叉戟空间注意力(TSA),通过聚合更广泛的空间上下文特征以解决深度错位问题。
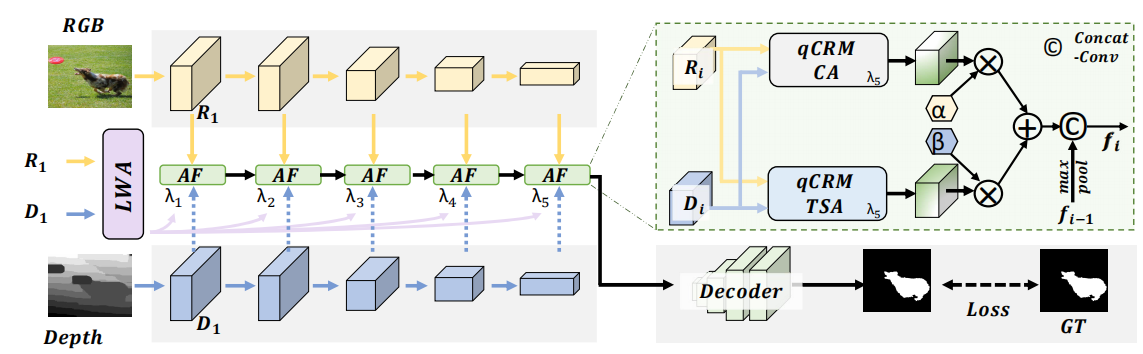
具体步骤:RFnet网络主要由分层注意LWA和自适应注意融合AF组成,先将RGB和D分别输入多层编码器,将第一层的特征输入LWA,得到针对每个层的融合参数λ,将λ输入每层的AF中进行融合,最后输入Decoder。AF主要结构是三叉注意力TSA,先对输入沿着通道做最大池化和平均池化,维度从C*H*W变为2*H*W,在使用3个膨胀率不同的卷积进行处理得到1*H*W的SA权重图。
2、《More ConvNets in the 2020s: Scaling up Kernels Beyond 51 × 51 using Sparsity》
(1)提出了稀疏大内核网络SLaK,是内核大小为51×51的新型纯CNN架构。
(2)探索了稀疏和内核分解的原则
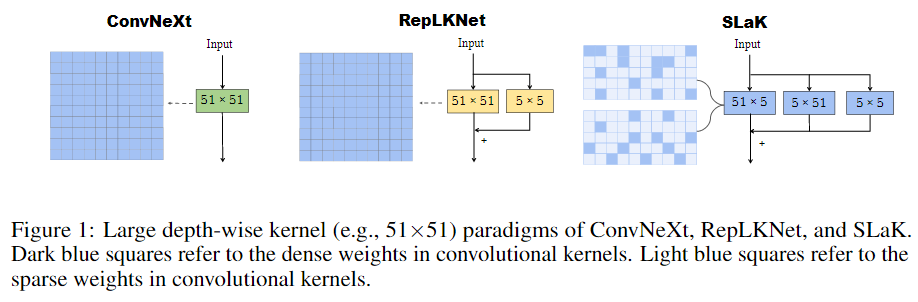
方法1:将 1 个方形大卷积核分解为2个具有动态稀疏结构的,平行的长方形卷积核,用来提高大卷积的可扩展性。具体来说,用两个平行的矩形卷积来逼近超大 M×M 的 Kernel,这两个卷积的 Kernel 大小分别是 M×N 和N×M (其中 N < M),再多一支 5×5 的分支,并且在 BN 层的输出合并这3个分支。将一个常用的 MxM 方形卷积核分解为两个平行的 MxN+NxM 长方形卷积核。不仅继承了超大 Kernel 捕捉长距离关系的能力,而且可以提取具有较短边缘的局部上下文特征。
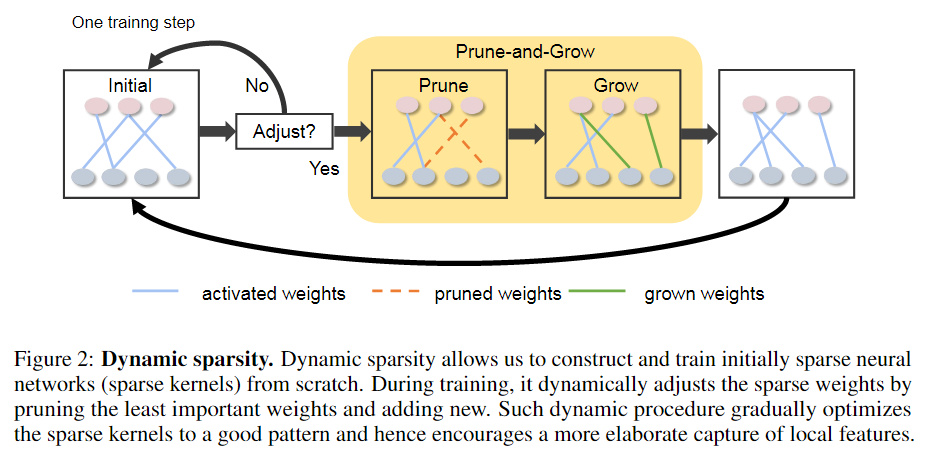
方法2:动态稀疏从头开始构建和训练最初的稀疏神经网络(稀疏核)。训练过程中通过剪枝最不重要的权值并添加新的权值来动态调整稀疏权值,更精细地捕获局部特征。
3、《Bridging Component Learning with Degradation Modelling for Blind Image Super-Resolution》
(1)从图像内在成分分析了HR图像的退化,并提出了一个组件分解和协同优化网络(CDCN),它为盲SR的组件学习和退化建模搭建了桥梁。
(2)提出了相互协作块(MCB),利用了图像结构和细节组件之间的关系,实现了协作优化。
(3)提出了一种退化驱动的学习策略来联合执行 HR 细节和结构恢复,以联合执行高分辨率图像的细节和结构恢复。
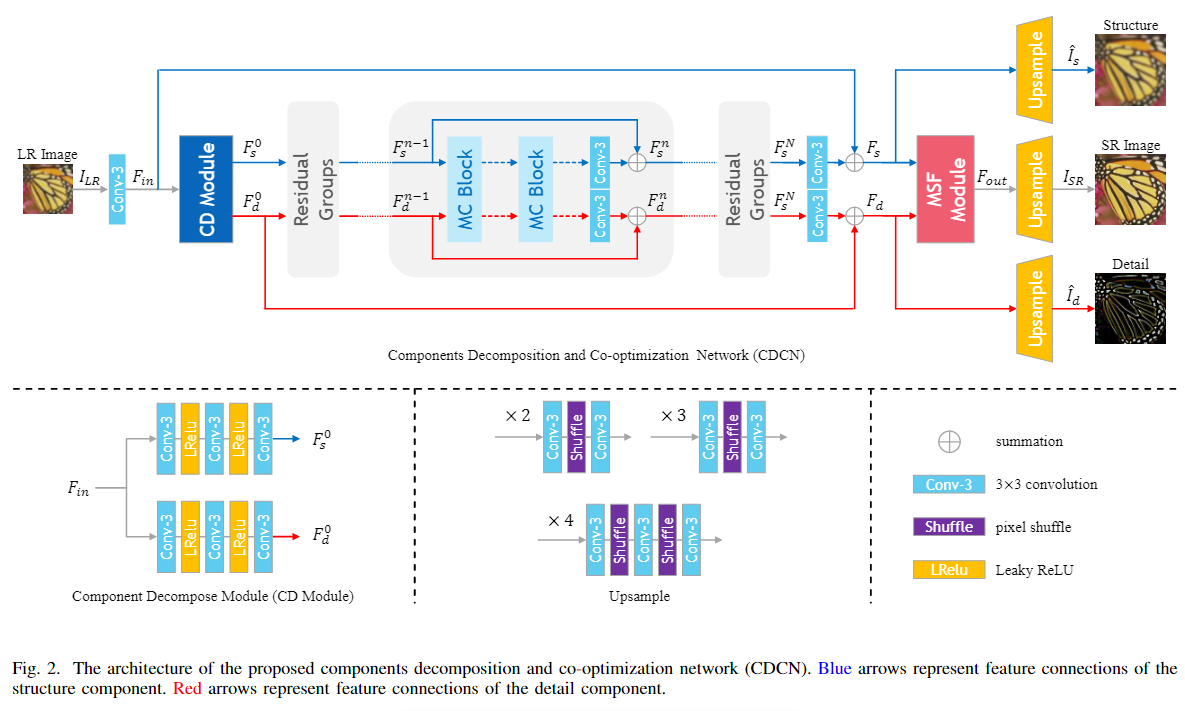
CDCN由三部分组成:组件分解模块(CDM)、由多个相互协作块(MCB)组成的级联残差组(RG)和多尺度融合模块(MSFM)。
给定尺寸为C*H*W的LR图像ILR,其中C为通道数,H和W为ILR的高度和宽度。我们首先将ILR输入到3*3卷积层中提取浅层特征,作为CDM的输入进行成分分解。在CDM中通过两个单独的特征提取块,直接从浅层特征中学习到对应的特征,从而获得初始细节和结构组件。相互协作块(MCB)利用两个组件之间的关系进行细节信息和结构信息的交互,并学习相互依存的更全面的表示。以堆叠的方式形成多个MCB,构造残差组(RG)来学习强大的特征表示。
4、《Language-Aware Domain Generalization Network for Cross-Scene Hyperspectral Image Classification》
本文提出语言感知域泛化网络(LDGnet),将文本提供的先验知识作为域不变信息,构建image-text pairs并提取嵌入特征,通过视觉-语言对齐的方式,实现领域泛化。LDGnet首次在高光谱图像中引入了语言模态,实现视觉语言多模态表征,构建遥感先验嵌入新范式。
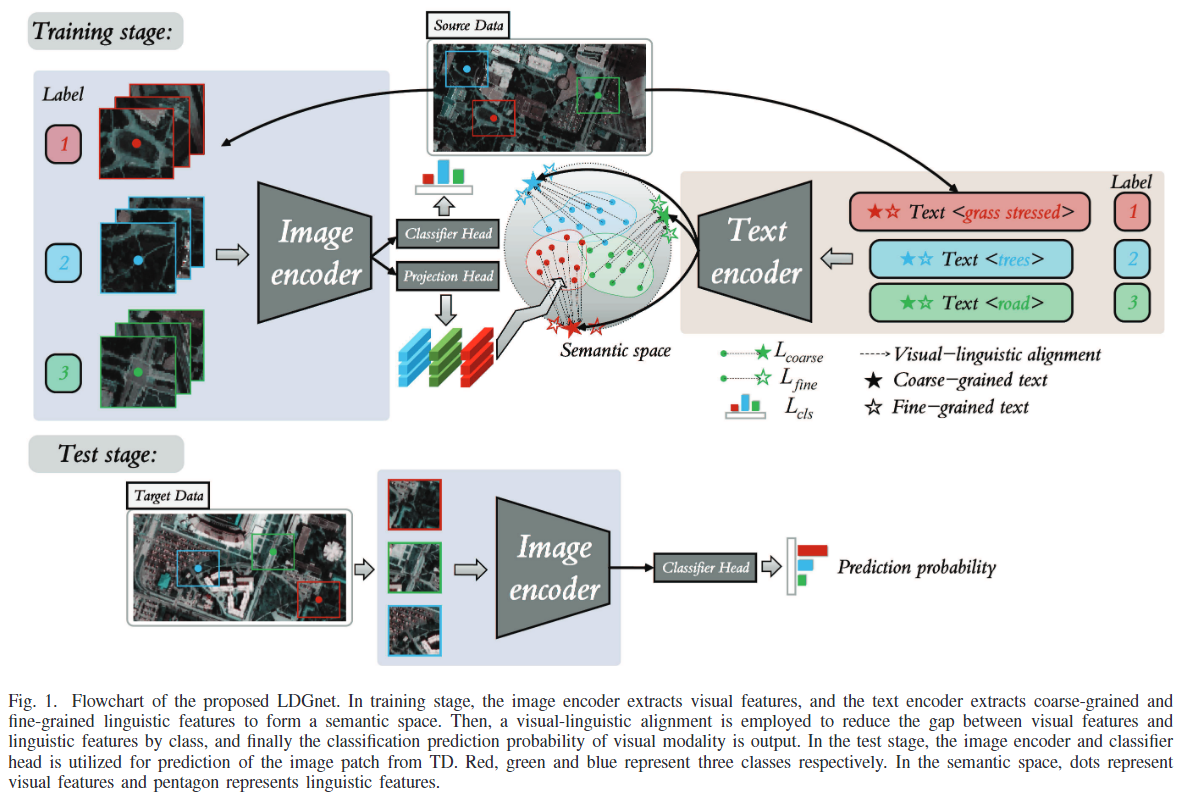
在训练阶段,Image encoder提取视觉特征,Text encoder提取粗粒度和细粒度的语言特征,形成语义空间。然后,采用视觉-语言对齐方法逐类别缩小视觉特征与语言特征之间的差异,最终输出视觉模态分类预测概率。在测试阶段,利用Image encoder和classifier head预测来自目标场景。如图所示,红、绿、蓝分别代表三个类别。在语义空间中,点代表视觉特征,五角星代表语言特征。
Image encoder 由两个3D residual Block-MaxPool3d和一个3D conv组成,送入classifier head与类别真值计算交叉熵。
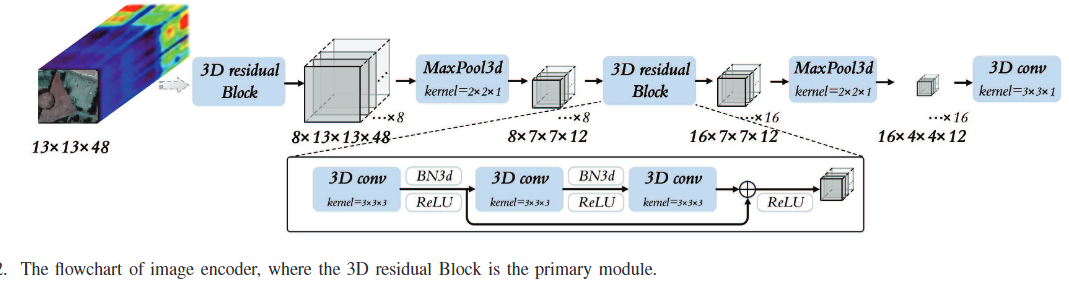
Text encoder使⽤语⾔模型transformer,通过粗粒度(coarse-grained)和细粒度(fine-grained)的⽂本描述为监督信号补充语义信息,在语⾔模态中创造语义空间。
视觉-语言对齐是将语义空间视作域间共享空间,采用有监督对比学习逐类别的对齐视觉特征和语言特征,学习由语言引导的域不变表征以便模型泛化至目标域。
5、《Rethinking Mobile Block for Efficient Neural Models》
本文提出了一种简单高效的模块——反向残差移动块(iRMB),通过堆叠不同层级的 iRMB,进而设计了一个面向移动端的轻量化网络模型——EMO,仅包含卷积模块和MHSA模块,分别用于模拟短距离依赖和远距离特征交互。
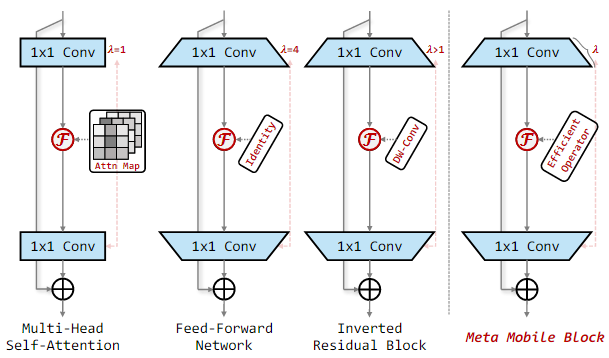
通过对 MobileNetv2 中的 Inverted Residual Block 以及 Transformer 中的核心 MHSA 和 FFN 模块进行抽象,作者提出了一种统一的 Meta Mobile (M2) Block 进行统一的表示,通过采用参数扩展率 λ 和高效算子 F 来实例化不同的模块。
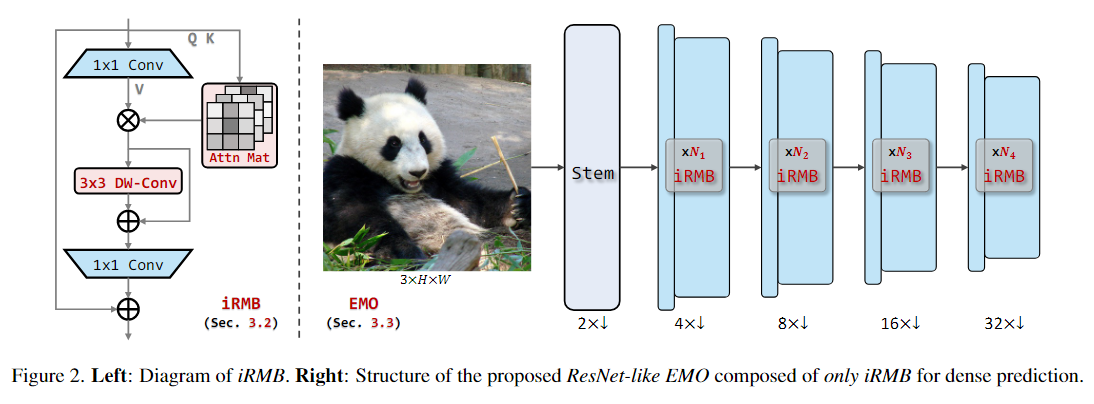
作者结合 W-MHSA 和 DW-Conv 和残差机制设计了iRMB,通过这种级联方式可以提高感受野的扩展率,同时降低计算复杂度。EMO 仅由iRMB组成,iRMB仅由标准卷积和MHSA组成,由于MHSA更适合为更深层次的语义特征建模,所以本文只在第三阶段和第四阶段使用MHSA.
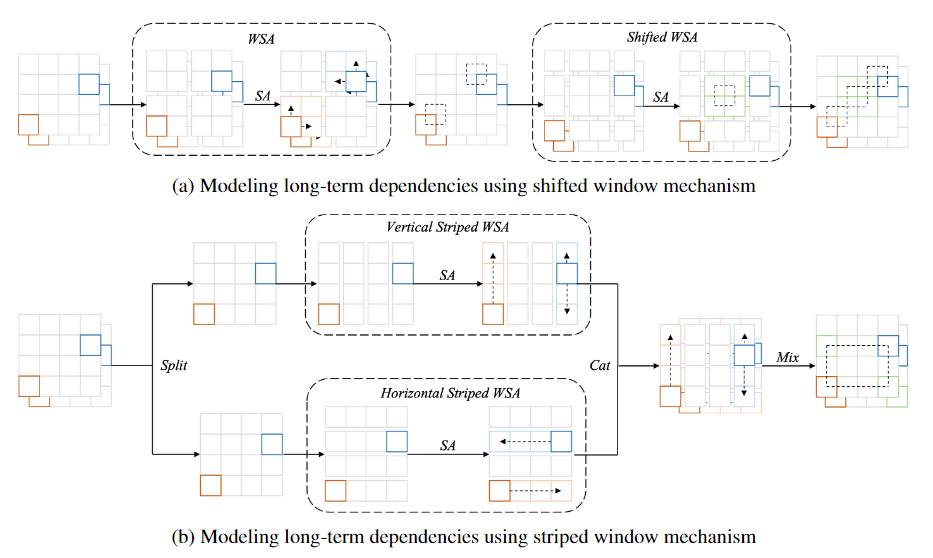
6、《Image Super-Resolution using Efficient Striped Window Transformer》
(1)设计了一个高效的转换层(ETL),为所提出的高效条形窗口Transformer(ESWT)提供了一个简洁的结构,避免了多余操作。
(2)提出了一种条纹窗口机制和灵活窗口训练策略,它可以更有效地建模长期依赖关系,计算复杂度较低。
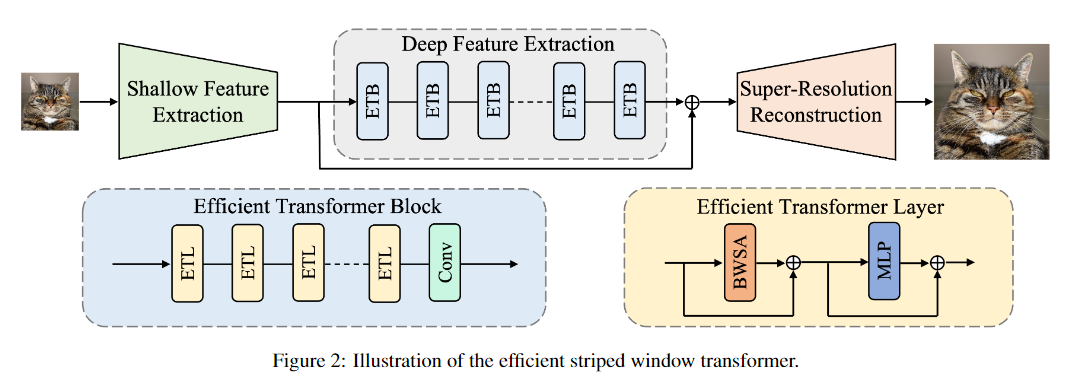
DFEM由多个ETB连接组成(本文中使用的ETB个数为3),每个ETB由多个ETL和一个卷积层连接组成(本文中使用的ETL个数为6),一个ETL由一个条纹窗口注意力BWSA和一个多层感知机MLP组成
作者还提出了长依赖建模机制(Long-term Dependency Modeling),将输入特征沿着信道维度平均分割为2个独立的特征,在这2个独立的特征上分别应用条纹局部窗口,它可以在更大的维度上建立窗口内连接,探索更多的上下文信息。除此之外,此处还将两个特征沿着信道维度进行拼接,将1*1卷积用于混合其中的窗口内连接,更有效地模拟了蓝色和橙色位置之间的长期依赖关系。