在当今快节奏的工作环境中,对员工工时的有效管理和分析变得至关重要。
我开发了一个Python脚本,专门用于从Excel文件中导入工时数据,并将这些数据以直观的图表形式进行可视化展示。这一工具的目的是为了帮助企业和组织更好地理解和优化员工的工时分配,进而提升整体的工作效率和决策质量。
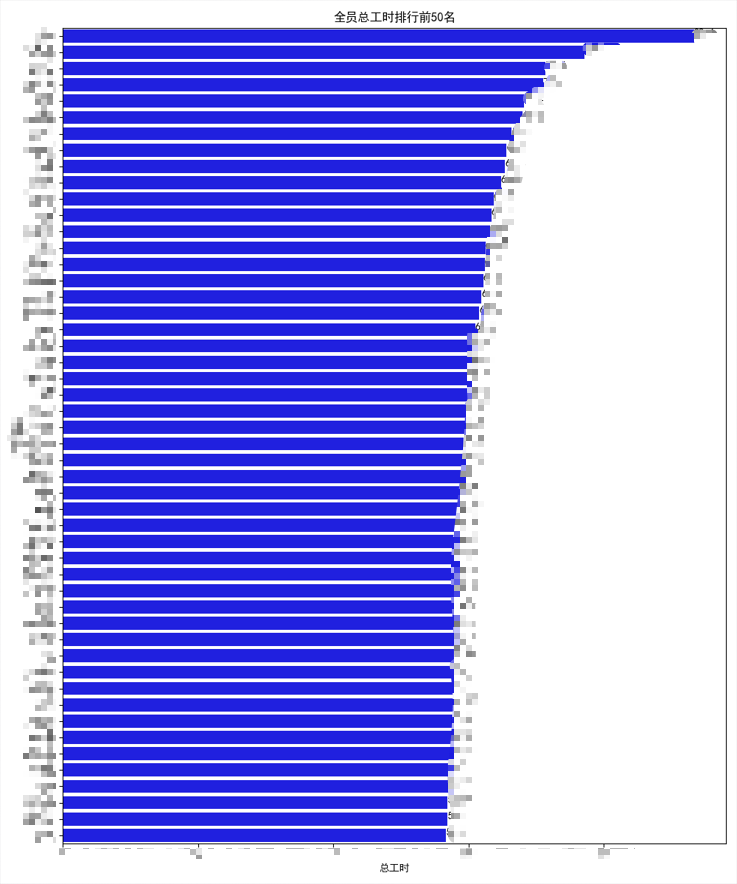
该Excel包含所属部门、员工姓名、工作时长等列,程序将输出全员工时排行前50名和各部门内部全员工时排行柱状图和每人工时占比饼图。
设计思路与方法
我的脚本设计围绕几个核心目标展开:易于使用、数据准确性、可视化清晰以及高度可扩展性。以下是我在设计和实现这个脚本时遵循的主要思路:
-
数据导入与清洗:
首先,使用pandas库来导入Excel中的数据。我使用了fillna方法来填补任何缺失的工时数据,确保分析的完整性。 -
数据分析:
接着,我通过groupby和sum方法对数据进行了分组和汇总,计算每个员工和每个部门的总工时。 -
数据合并与计算:
使用merge方法将员工的个人总工时与部门总工时合并,并计算出每个员工在其部门总工时中的占比,分析个人的工作量如何对部门整体产生影响。 -
可视化展示:
利用matplotlib和seaborn库来创建图表。为了使数据呈现更加直观,我为每个部门设计了两种图表:一种是展示员工工时排行的条形图,另一种是展示工时占比的饼图。这些图表不仅直观展示了数据,还易于理解和分享。 -
结果输出:
最后,所有生成的图表都被保存为图片文件,便于在报告或会议中使用。这一步是通过plt.savefig方法实现的,它提供了一种简便的方式来存储和分享结果。
相关代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
import sys
def main(file_path):
# 读取数据
data = pd.read_excel(file_path)
# 处理'工作时长'列中的NaN值
data['工作时长'].fillna(0, inplace=True)
# 按部门和员工分组,计算每个员工的总工时
dept_emp_hours = data.groupby(['所属部门', '员工姓名'])['工作时长'].sum().reset_index(name='总工时')
# 按部门分组,计算每个部门的总工时
dept_total_hours = dept_emp_hours.groupby('所属部门')['总工时'].sum().reset_index(name='部门总工时')
# 将部门总工时合并到个人工时数据中
merged_data = dept_emp_hours.merge(dept_total_hours, on='所属部门')
# 计算每个员工在部门总工时中的占比
merged_data['部门工时占比'] = (merged_data['总工时'] / merged_data['部门总工时']) * 100
# 设置中文字体为黑体
plt.rcParams['font.family'] = 'SimHei'
# 创建文件夹以保存所有图表
now_time = pd.Timestamp.now().strftime('%Y-%m-%d')
plots_folder_path = now_time + '部门工时'
os.makedirs(plots_folder_path, exist_ok=True)
# 修改后的为每个部门创建并保存图表的函数
def create_plot_for_dept(department, data):
# 筛选特定部门的数据,且工时大于0
dept_data = data[(data['所属部门'] == department) & (data['总工时'] > 0)].sort_values(by='总工时', ascending=False)
# 创建工时排行图表
plt.figure(figsize=(10, len(dept_data) * 0.5)) # 根据员工数量调整图表大小
sns.barplot(x='总工时', y='员工姓名', data=dept_data, color='b')
plt.title(f'{department} 工时排行')
plt.xlabel('总工时')
plt.ylabel('员工姓名')
# 在柱状图上显示数值
for index, value in enumerate(dept_data['总工时']):
plt.text(value, index, f'{value:.1f}')
plt.tight_layout()
# 保存图表
plot_path = os.path.join(plots_folder_path, f'{department}工时排行.png')
plt.savefig(plot_path)
plt.close() # 关闭图表以释放内存
# 创建部门工时占比的饼图
plt.figure(figsize=(8, 8))
plt.pie(dept_data['总工时'], labels=dept_data['员工姓名'], autopct='%1.1f%%', startangle=140)
plt.title(f'{department} 工时占比')
plt.tight_layout()
# 保存饼图
pie_plot_path = os.path.join(plots_folder_path, f'{department}工时占比.png')
plt.savefig(pie_plot_path)
plt.close() # 关闭图表以释放内存
return plot_path, pie_plot_path
# 为每个部门生成图表和饼图
unique_departments = merged_data['所属部门'].unique()
dept_plots = [create_plot_for_dept(dept, merged_data) for dept in unique_departments]
# 创建全员总工时排行前50名的柱状图
plt.figure(figsize=(10, 12))
top_50_overall = merged_data.sort_values(by='总工时', ascending=False).head(50)
sns.barplot(x='总工时', y='员工姓名', data=top_50_overall, color='b')
plt.title('全员总工时排行前50名')
plt.xlabel('总工时')
plt.ylabel('员工姓名')
# 在柱状图上显示数值
for index, value in enumerate(top_50_overall['总工时']):
plt.text(value, index, f'{value:.1f}')
plt.tight_layout()
# 保存全员总工时排行图表
overall_top_50_plot_path = now_time + '全员工时前50名.png'
plt.savefig(overall_top_50_plot_path)
plt.close()
if __name__ == "__main__":
if len(sys.argv) < 2:
print("请拖拽一个文件到这个程序上")
else:
file_path = sys.argv[1]
main(file_path)
使用到的各类方法
-
fillna:
- 属于:
pandas库。 - 作用:用于填充DataFrame中的NaN(即缺失)值。在这个程序中,
data['工作时长'].fillna(0, inplace=True)使用0填充工作时长列中的所有NaN值。inplace=True表示直接在原始DataFrame上修改而不是创建一个新的。
- 属于:
-
groupby:
- 属于:
pandas库。 - 作用:按照指定的列或列的组合对数据进行分组。在程序中,
data.groupby(['部门', '姓名'])意味着数据根据部门和姓名列的组合进行分组。
- 属于:
-
sum:
- 属于:
pandas库。 - 作用:计算分组数据的总和。例如,
['工作时长'].sum()计算每个分组中工作时长的总和。
- 属于:
-
reset_index:
- 属于:
pandas库。 - 作用:重置DataFrame的索引。当你在pandas中使用诸如
groupby之类的操作后,结果通常会有一个多级索引。使用reset_index可以将这个多级索引转换为标准索引,并且可以选择将原来的索引列保留为普通列。在程序中,reset_index(name='总工时')将分组后的数据转换为一个新的DataFrame,并创建一个名为总工时的列来存储每个组的总工时。
- 属于:
-
merge:
- 属于:
pandas库。 - 作用:用于合并两个DataFrame。在程序中,
merge用于将个人工时数据与部门总工时数据合并在一起,基于部门列进行匹配。
- 属于:
-
os.makedirs:
- 属于:
os模块。 - 作用:用于创建目录。如果目录已存在,
exist_ok=True参数会防止程序因目录已存在而报错。
- 属于:
-
plt.figure:
- 属于:
matplotlib.pyplot库。 - 作用:创建一个新的图表或激活一个已存在的图表。
figsize参数用于指定图表的大小。
- 属于:
-
sns.barplot:
- 属于:
seaborn库。 - 作用:绘制条形图。在程序中,用于展示员工的工时排行。
- 属于:
-
plt.pie:
- 属于:
matplotlib.pyplot库。 - 作用:绘制饼图。在程序中,用于展示部门内员工工时的占比。
- 属于:
-
plt.savefig:
- 属于:
matplotlib.pyplot库。 - 作用:将创建的图表保存为文件。
- 属于:
-
plt.close:
- 属于:
matplotlib.pyplot库。 - 作用:关闭一个图表,释放其所占用的内存资源。
- 属于:
小结
通过这个Python脚本,能够帮助管理层和员工更好地理解和分析工作时长数据。这种数据的可视化展示不仅提高了数据的可访问性和理解度,还为做出更加明智的业务决策提供了支持。更重要的是,这个脚本的设计考虑到了灵活性和扩展性,使其可以轻松适应不同的数据集和分析需求。