python操作哨兵、python操作集群、缓存优化、mysql 主从
python操作哨兵
用高可用架构后---》不能直接连某一个主库了---》主库可能会挂掉,后来它就不是主库了
# 之前学的连接redis的操作,就用不了了
import redis
conn=redis.Redis(host='',port=6379)
conn.set()
conn.close()
# 新的连接哨兵的操作
# 连接哨兵服务器(主机名也可以用域名)
# 10.0.0.101:26379
import redis
from redis.sentinel import Sentinel
# 哨兵的地址和端口
sentinel = Sentinel([('10.0.0.101', 26379),
('10.0.0.101', 26378),
('10.0.0.101', 26377)
],socket_timeout=5)
print(sentinel)
# 获取主服务器地址
master = sentinel.discover_master('mymaster')
print(master)
# 获取从服务器地址
slave = sentinel.discover_slaves('mymaster')
print(slave)
##### 读写分离
获取主服务器进行写入
master = sentinel.master_for('mymaster', socket_timeout=0.5)
w_ret = master.set('foo', 'bar')
slave = sentinel.slave_for('mymaster', socket_timeout=0.5)
r_ret = slave.get('foo')
print(r_ret)
###注意:要写机器的ip地址,不要写127.0.0.1,想在公网用,就写公网ip,python要是在内网中使用,要写内网ip
python操作集群
# 一旦搭建了集群,python操作也变了
# rediscluster
# pip3 install redis-py-cluster
from rediscluster import RedisCluster
startup_nodes = [{"host":"127.0.0.1", "port": "7000"},{"host":"127.0.0.1", "port": "7001"},{"host":"127.0.0.1", "port": "7002"}]
# rc = RedisCluster(startup_nodes=startup_nodes,decode_responses=True)
rc = RedisCluster(startup_nodes=startup_nodes)
rc.set("foo", "bar")
print(rc.get("foo"))
缓存优化
1.1redis缓存更新策略
# Redis本身,内存存储,会出现内存不够用,放数据放不进去,一些策略,删除一部分数据,再放新的数据。
# LRU/LFU/FIFO 算法剔除:例如maxmemory-policy(到了最大内存,对应的应对策略)
LRU -Least Recently Used,没有被使用时间最长的
LFU -Least Frequenty Used,一定时间段内使用次数最少的
FIFO -First In First Out 先进先出
1.2 缓存击穿,缓存雪崩,缓存穿透
1.2.1缓存击穿
'''
缓存穿透是指缓存和数据库中都没有数据的,而用户不断发起请求,如发起id为‘-1’的数据或id为头部大的不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
'''
# 解决方案
1.接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截
2.从缓存中取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效期可以设置短点,如30秒(太长的话会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击。
3.通过布隆过滤器实现(可以去重)
1.2.2 缓存击穿
'''
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时用于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
'''
# 解决方案
设置热点数据永远不过期
1.2.3 缓存雪崩
'''
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。
和缓存击穿不同的是-----》缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库
'''
# 解决问题
1.缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生
2.如果缓存数据库是分布式部署,将热点数据均匀分布到不同高的缓存数据库中
3.设置热点数据永远不过期
mysql 主从
# 之前做过redis的主从,很简单
# mysql 稍微复杂一些, 搭建mysql主从的目的是?
-读写分离
-单个实例并发量低,提高并发量
-只在主库写,读数据都去从库
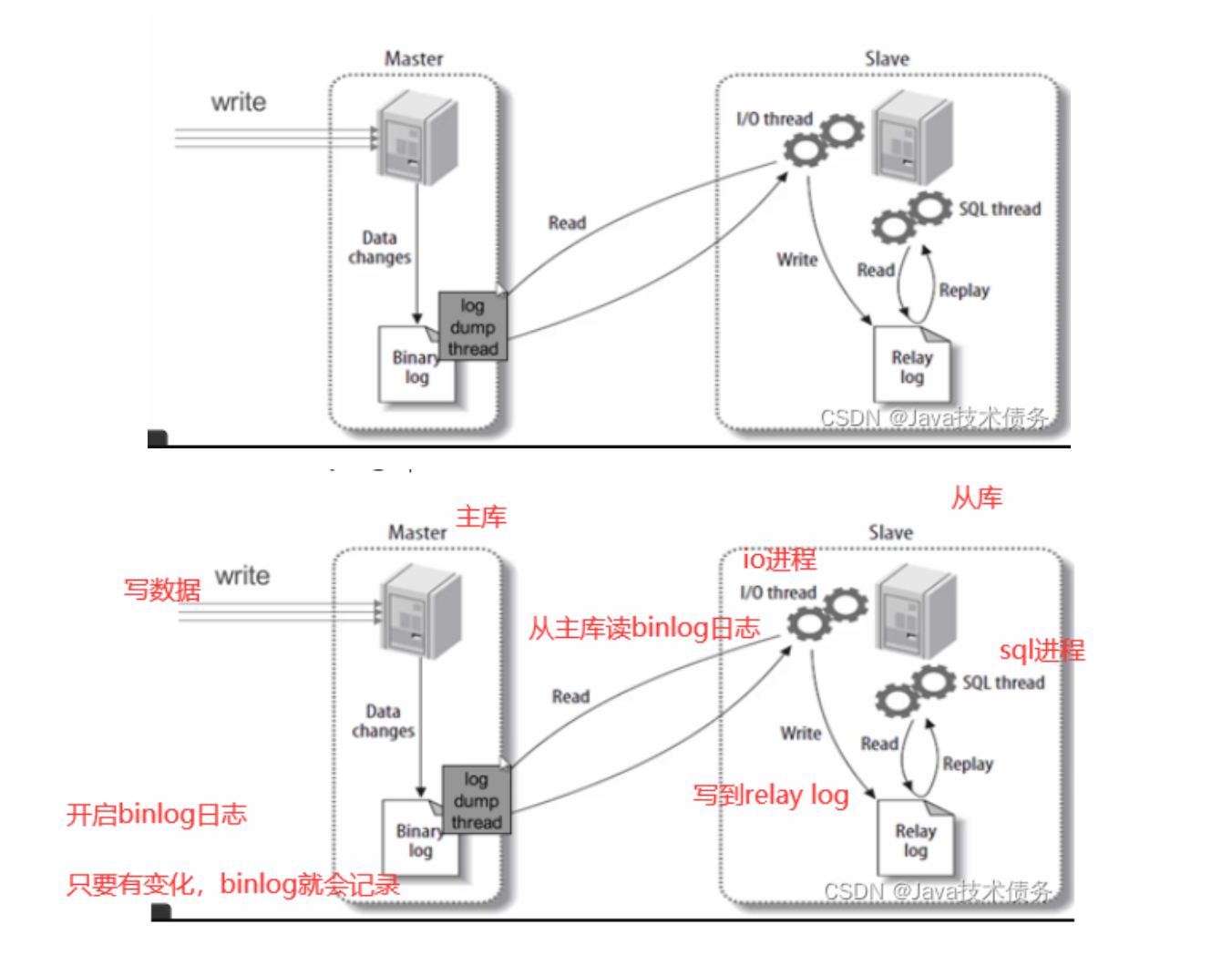
# mysql 主从原理
步骤一:主库db的更新事件(update、insert、delete)被写到binlog
步骤二:从库发起连接,连接到主库
步骤三:此时主库创建一个binlog dump thread线程,把binlog的内容发送到从库
步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log.
步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db.
# 搭建步骤 :准备两台机器 (mysql的docker镜像模拟两台机器)
-主库:10.0.0.102 33307
-从库:10.0.0.102 33306
# 第一步:拉取mysql5.7的镜像
# 第二步:创建文件夹,文件(目录映射)
mkdir /home/mysql
mkdir /home/mysql/conf.d
mkdir /home/mysql/data/
touch /home/mysql/my.cnf
mkdir /home/mysql1
mkdir /home/mysql1/conf.d
mkdir /home/mysql1/data/
touch /home/mysql1/my.cnf
# 第三步(重要):编写mysql配置文件(主,从)
#### 主的配置####
[mysqld]
user=mysql
character-set-server=utf8
default_authentication_plugin=mysql_native_password
secure_file_priv=/var/lib/mysql
expire_logs_days=7
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
max_connections=1000
server-id=100
log-bin=mysql-bin
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
#### 从库的配置#####
[mysqld]
user=mysql
character-set-server=utf8
default_authentication_plugin=mysql_native_password
secure_file_priv=/var/lib/mysql
expire_logs_days=7
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
max_connections=1000
server-id=101
log-bin=mysql-slave-bin
relay_log=edu-mysql-relay-bin
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
#第三步:启动mysql容器,并做端口和目录映射
docker run -di -v /home/mysql/data/:/var/lib/mysql -v /home/mysql/conf.d:/etc/mysql/conf.d -v /home/mysql/my.cnf:/etc/mysql/my.cnf -p 33307:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
docker run -di -v /home/mysql1/data/:/var/lib/mysql -v /home/mysql1/conf.d:/etc/mysql/conf.d -v /home/mysql1/my.cnf:/etc/mysql/my.cnf -p 33306:3306 --name mysql-slave -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
#第四步:连接主库
mysql -uroot -P33307 -h 10.0.0.102 -p
#在主库创建用户并授权
##创建test用户
create user 'test'@'%' identified by '123';
##授权用户
grant all privileges on *.* to 'test'@'%' ;
###刷新权限
flush privileges;
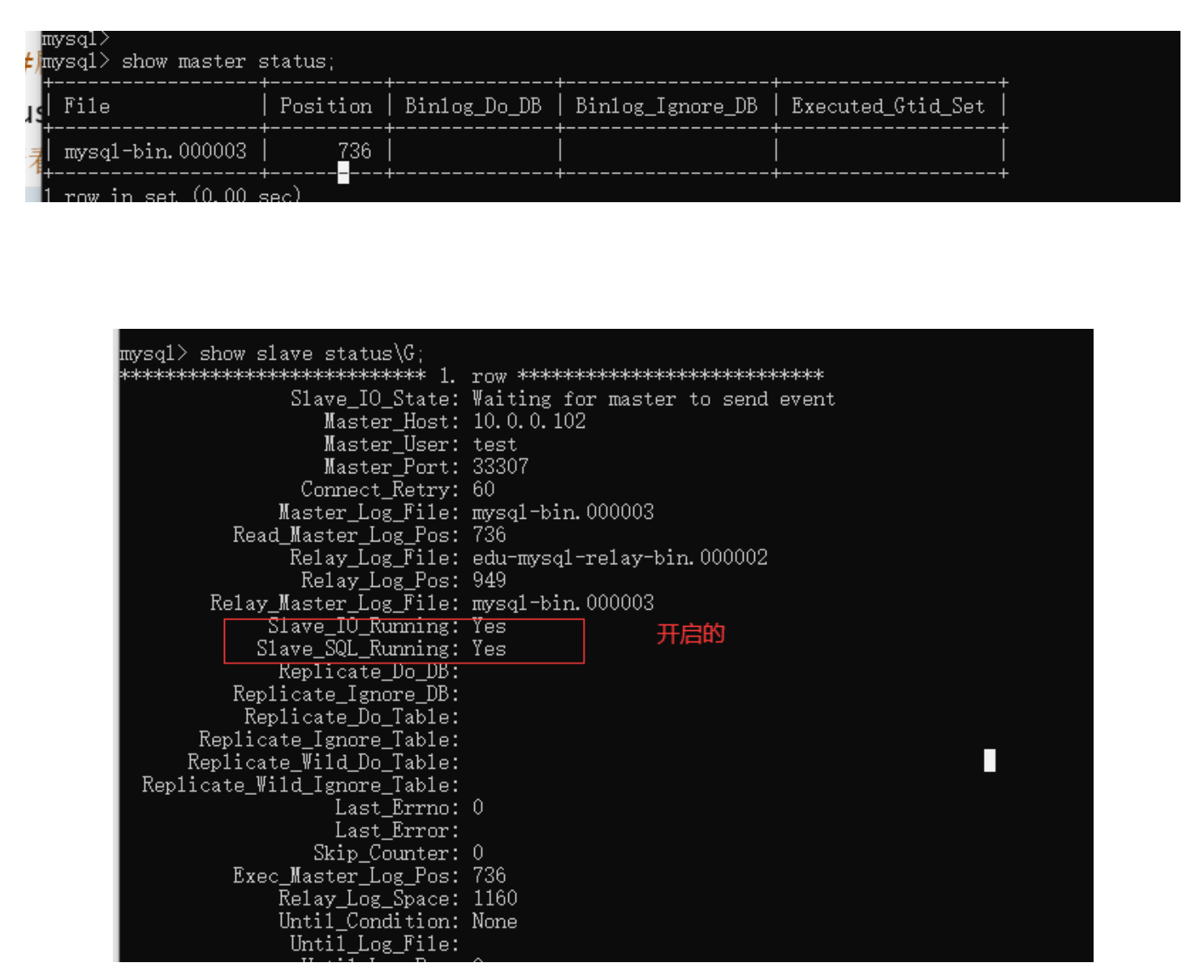
#查看主服务器状态(显示如下图)
show master status;
# 第五步:连接从库
mysql -uroot -P33306 -h 10.0.0.102 -p
#配置详解
'''
change master to
master_host='MySQL主服务器IP地址',
master_user='之前在MySQL主服务器上面创建的用户名',
master_password='之前创建的密码',
master_log_file='MySQL主服务器状态中的二进制文件名',
master_log_pos='MySQL主服务器状态中的position值';
'''
change master to master_host='10.0.0.102',master_port=33307,master_user='test',master_password='123',master_log_file='mysql-bin.000003',master_log_pos=0;
#启用从库
start slave;
#查看从库状态(如下图)
show slave status\G;
# 第六版:在主库创建库,创建表,插入数据,看从库
django使用多数据库做读写分离
# 第一步:配置文件配置多数据库
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
},
'db1': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db1.sqlite3',
}
}
# 第二步:手动读写分离
Book.objects.using('db1').create(name='西游记')
# 第三步,自动读写分离
写一个py文件,db_router.py,写一个类:
class DBRouter(object):
def db_for_read(self, model, **hints):
# 多个从库 ['db1','db2','db3']
return 'db1'
def db_for_write(self, model, **hints):
return 'default'
# 第三步:配置文件配置
DATABASE_ROUTERS = ['mysql_master_demo.db_router.DBRouter', ]
# 以后自动读写分离