作业①
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。
使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
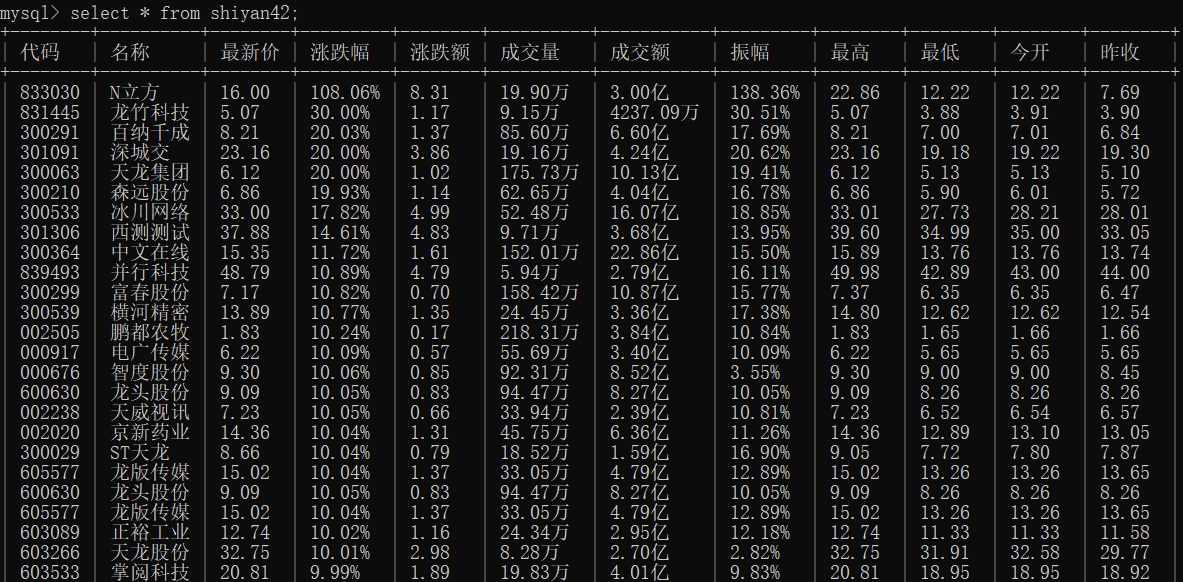
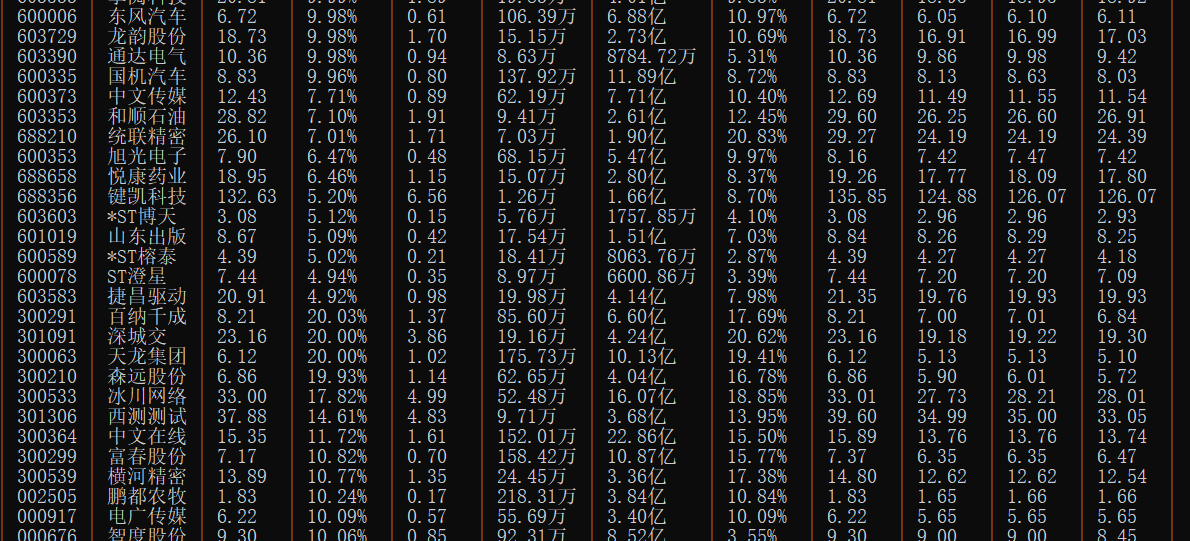
输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
Gitee文件夹链接:点这里
代码展示
代码
from selenium import webdriver
from lxml import etree
from selenium.webdriver.common.by import By
import time
import mysql.connector
def get_data(url):
html = driver.page_source
bs = etree.HTML(html)
lis = bs.xpath('//*[@id="table_wrapper-table"]/tbody/tr')
for link in lis:
a = link.xpath('./td[2]/a/text()')[0]
b = link.xpath('./td[3]/a/text()')[0]
c = link.xpath('./td[5]/span/text()')[0]
d = link.xpath('./td[6]/span/text()')[0]
e = link.xpath('./td[7]/span/text()')[0]
f = link.xpath('./td[8]/text()')[0]
g = link.xpath('./td[9]/text()')[0]
h = link.xpath('./td[10]/text()')[0]
i = link.xpath('./td[11]/span/text()')[0]
j = link.xpath('./td[12]/span/text()')[0]
k = link.xpath('./td[13]/span/text()')[0]
l = link.xpath('./td[14]/text()')[0]
mydb = mysql.connector.connect(
host="localhost",
user="root",
password="wjy514520",
database="mydb"
)
mycursor = mydb.cursor()
sql = "INSERT INTO shiyan42 (代码, 名称, 最新价, 涨跌幅, 涨跌额, 成交量, 成交额, 振幅, 最高, 最低, 今开, 昨收) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
val = (a, b, c, d, e, f, g, h, i, j, k, l)
mycursor.execute(sql, val)
mydb.commit()
print(a,b,c,d,e,f,g,h,i,j,k,l)
next_button = driver.find_element(By.XPATH, url)
next_button.click()
time.sleep(2)
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=chrome_options)
driver.get("https://quote.eastmoney.com/center/gridlist.html#hs_a_board")
get_data('//*[@id="nav_sh_a_board"]/a')
get_data('//*[@id="nav_sz_a_board"]/a')
get_data('//*[@id="nav_bj_a_board"]/a')
运行结果

心得体会
这次实验的作业①对我来说并不难,之前写过多次类似的代码,主要的难点在于对动态页面的爬取和Xpath的运用,总体并没有花费多少时间。
作业②
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
等待 HTML 元素等内容。
使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国 mooc 网:https://www.icourse163.org
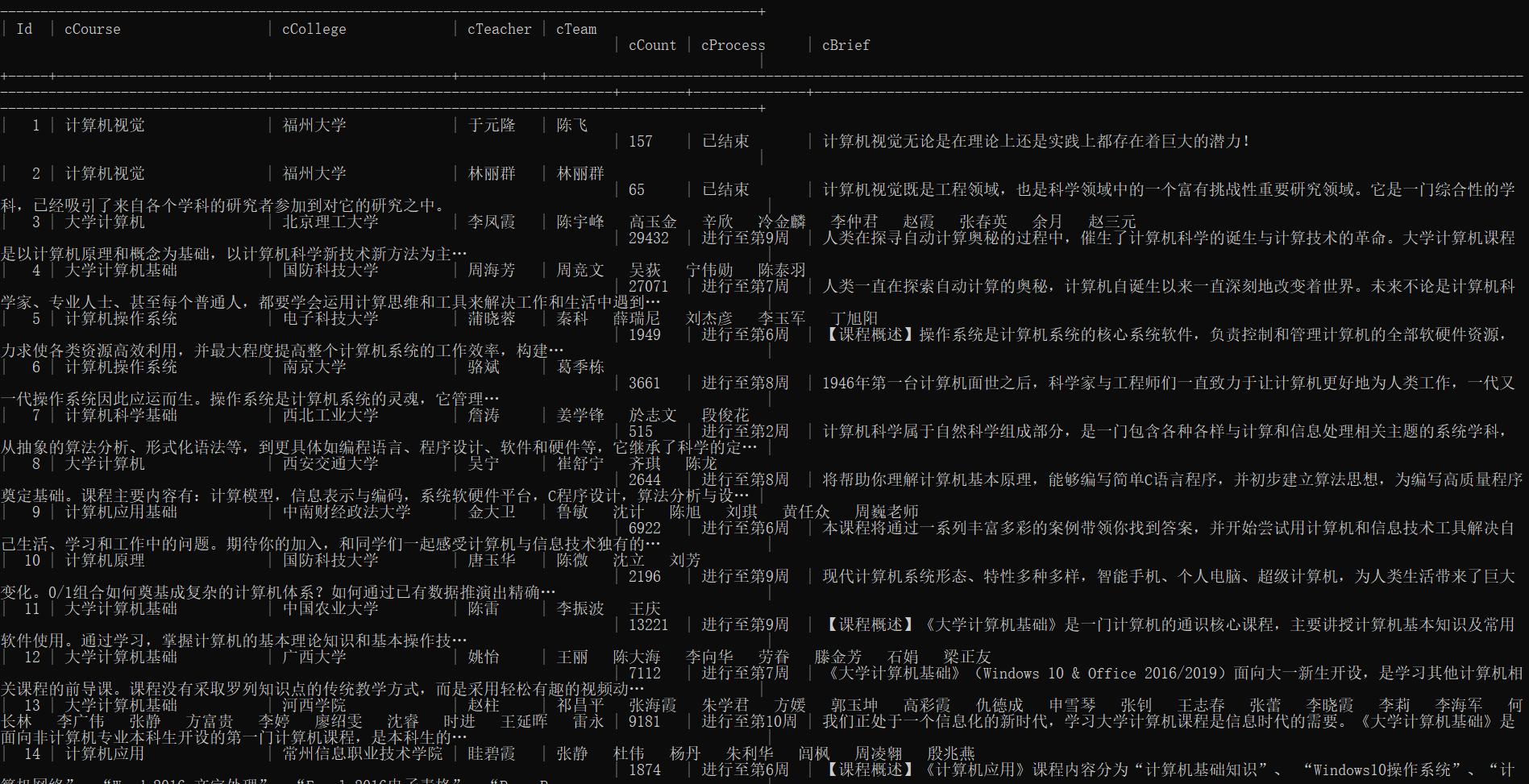
输出信息:MYSQL 数据库存储和输出格式
Gitee文件夹:点这里
代码展示
代码
from selenium import webdriver
from lxml import etree
from selenium.webdriver.common.by import By
import time
import mysql.connector
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=chrome_options)
#登录
driver.get('https://www.icourse163.org/')
time.sleep(2)
driver.maximize_window()
next_button = driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
next_button.click()
time.sleep(2)
frame = driver.find_element(By.XPATH,'/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(frame)
# 输入账号
account = driver.find_element(By.ID, 'phoneipt').send_keys('17268180769')
# 输入密码
password = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]').send_keys("qwertyuiop123!")
# 获取登录按钮
logbutton = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a')
# 点击按钮
logbutton.click()
time.sleep(2)
driver.get('https://www.icourse163.org/search.htm?search=%E5%A4%A7%E5%AD%A6#/')
time.sleep(2)
next_button = driver.find_element(By.XPATH, '/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[1]/div[1]/label/div')
next_button.click()
time.sleep(2)
js = '''
timer = setInterval(function(){
var scrollTop=document.documentElement.scrollTop||document.body.scrollTop;
var ispeed=Math.floor(document.body.scrollHeight / 100);
if(scrollTop > document.body.scrollHeight * 90 / 100){
clearInterval(timer);
}
console.log('scrollTop:'+scrollTop)
console.log('scrollHeight:'+document.body.scrollHeight)
window.scrollTo(0, scrollTop+ispeed)
}, 20)
'''
for i in range(1,5):
driver.execute_script(js)
time.sleep(4)
html = driver.page_source
bs = etree.HTML(html)
lis = bs.xpath('/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[2]/div[1]/div/div/div')
for link in lis:
a = link.xpath('./div[2]/div/div/div[1]/a[2]/span/text()')
if len(a) != 0:
if a[0] == '国家精品':
b = link.xpath('./div[2]/div/div/div[1]/a[1]/span/text()')[0]
c = link.xpath('./div[2]/div/div/div[2]/a[1]/text()')[0]
d = link.xpath('./div[2]/div/div/div[2]/a[2]/text()')[0]
e = link.xpath('./div[2]/div/div/a/span/text()')[0]
f = link.xpath('./div[2]/div/div/div[3]/div/span[2]/text()')[0]
g = link.xpath('./div[2]/div/div/div[2]/span/span/span/span/span/span/a/text()')[0]
h = link.xpath('./div[2]/div/div/div[3]/span[2]/text()')[0]
mydb = mysql.connector.connect(
host="localhost",
user="root",
password="wjy514520",
database="mydb"
)
mycursor = mydb.cursor()
sql = "INSERT INTO shiyan42 (cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief) VALUES (%s, %s, %s, %s, %s, %s, %s)"
val = (b, c, d, e, f, g, h)
mycursor.execute(sql, val)
mydb.commit()
next_button = driver.find_element(By.XPATH, '//*[@id="j-courseCardListBox"]/div[2]/ul/li[10]')
next_button.click()
time.sleep(2)
运行结果
心得体会
这次实验的作业二给我带来了很大困难,首先是模拟浏览器登录,虽然有ppt的帮助,还是花费了很多时间调试代码,自动翻页的实现也比较困难,最后通过查询资料解决,Xpath的定位也花费了不少时间,完成这个实验让我学到了很多。
作业③
实验环境搭建

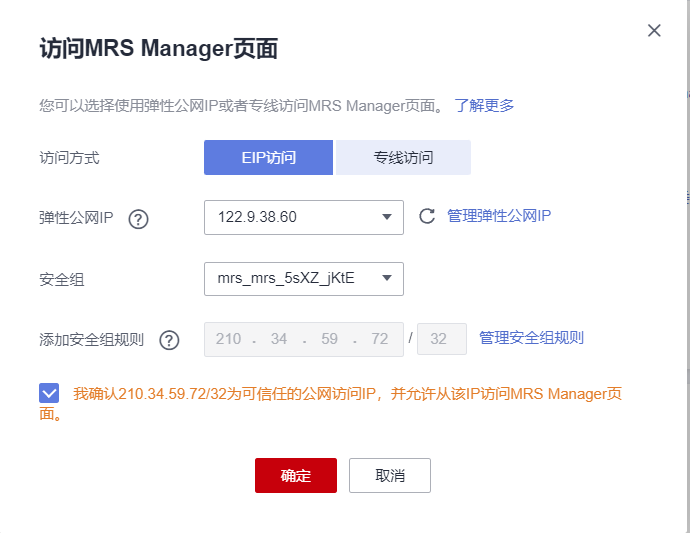
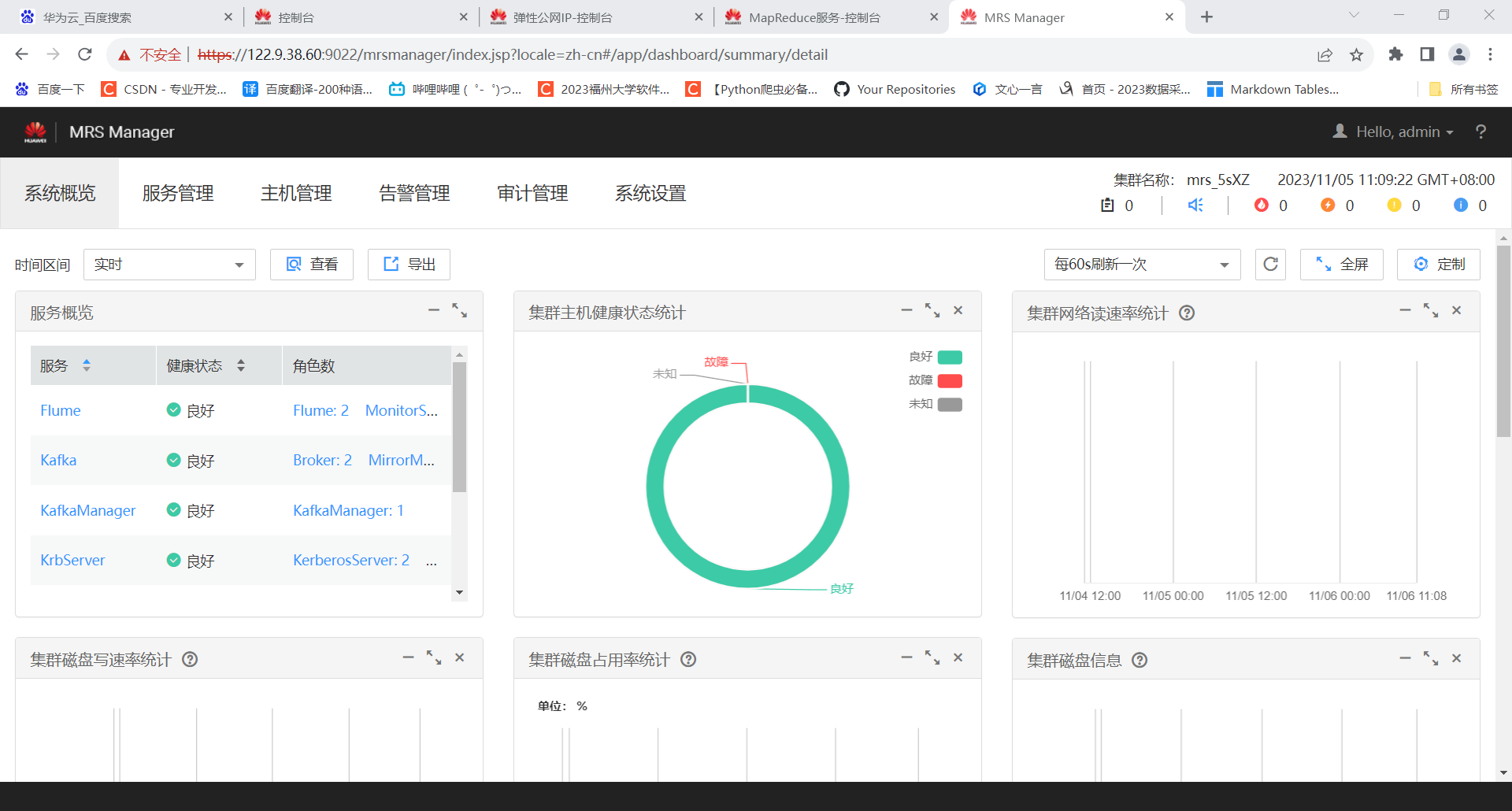
任务一
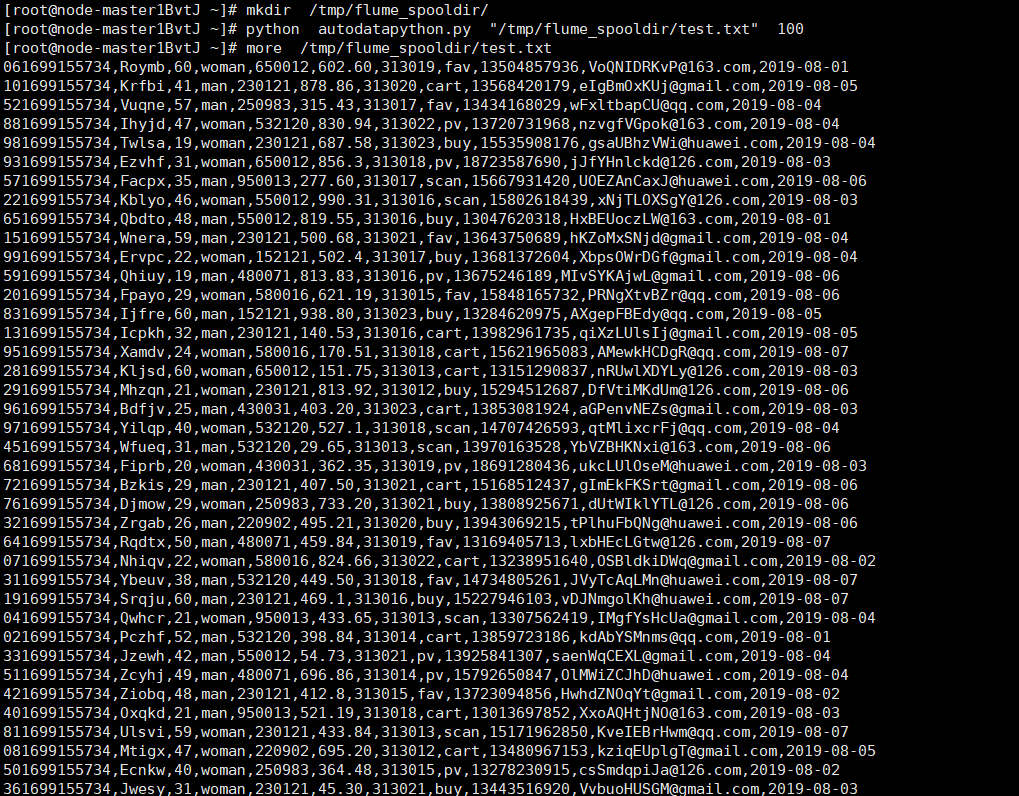
任务二

任务三
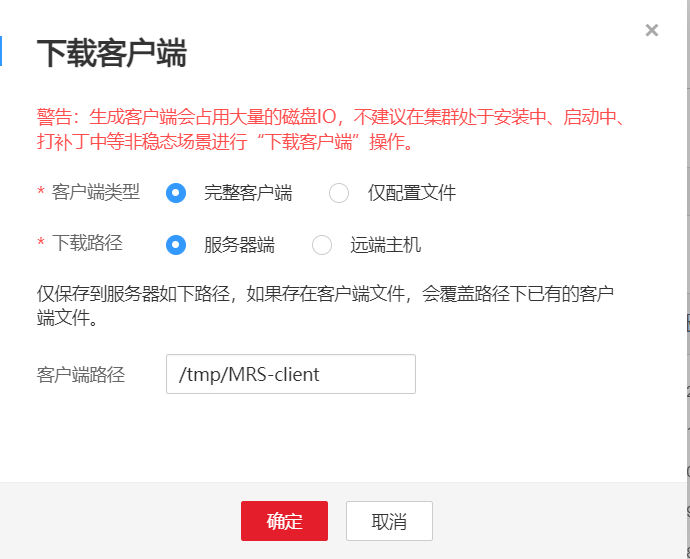


任务四