今天再刷LeetCode时,遇到了第146题LRU缓存。题目如下:
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
如果大家有阅读过LinkedHashMap源码,就会明白,这题的解法跟LinkedHashMap源码一模一样。
大家应该经常使用HashMap,而LinkedHashMap 刚好就比 HashMap 多这一个功能就是有序。并且,LinkedHashMap的有序可以按两种顺序排列,一种是按照插入的顺序,一种是按照 读取 的顺序。显然,这题便是LinkedHashMap中按照读取的顺序进行顺序排列。而其内部是靠 建立一个双向链表 来维护这个顺序的,在每次插入、删除后,都会调用一个函数来进行 双向链表的维护 。
其内部就是靠如下三个回调方法来维护这个双向链表:
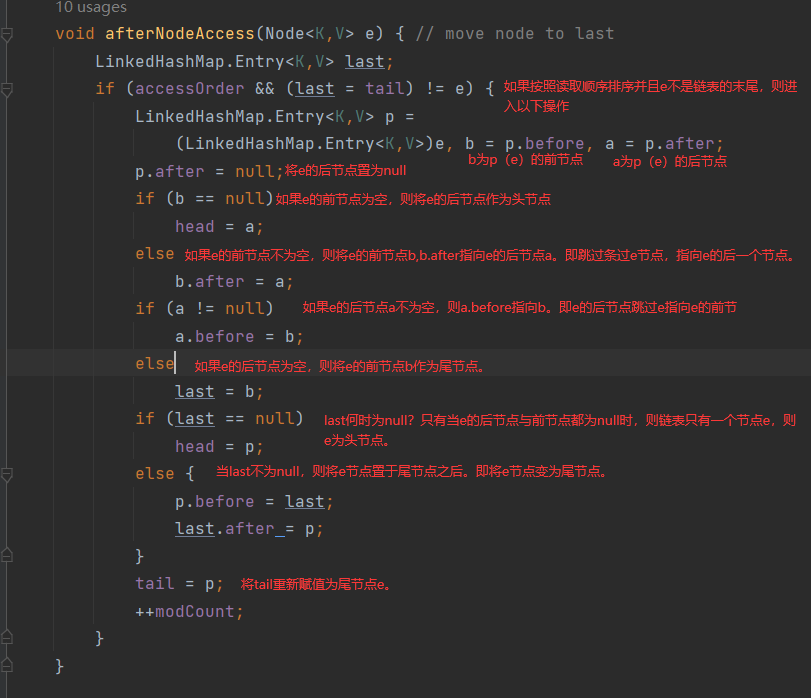
void afterNodeAccess(Node<K,V> p) { }
其作用就是在访问元素之后,将该元素放到双向链表的尾巴处(所以这个函数只有在按照读取的顺序的时候才会执行),之所以提这个,是建议大家去看看,如何优美的实现在双向链表中将指定元素放入链尾!
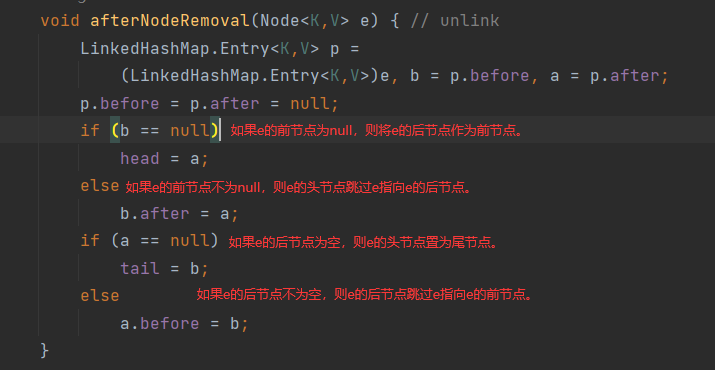
void afterNodeRemoval(Node<K,V> p) { }
其作用就是在删除元素之后,将元素从双向链表中删除,还是非常建议大家去看看这个函数的,很优美的方式在双向链表中删除节点!
void afterNodeInsertion(boolean evict) { }
这个才是我们题目中会用到的,在插入新元素之后,需要回调函数判断是否需要移除一直不用的某些元素!
以下是我对于afterNodeAccess、afterNodeRemoval、afterNodeInsertion的个人理解:
afterNodeAccess:
afterNodeRemoval:
afterNodeInsertion:
/**
* 插入新节点才会触发该方法,因为只有插入新节点才需要内存
* 根据 HashMap 的 putVal 方法, evict 一直是 true
* removeEldestEntry 方法表示移除规则, 在 LinkedHashMap 里一直返回 false
* 所以在 LinkedHashMap 里这个方法相当于什么都不做
*/
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// 根据条件判断是否移除最近最少被访问的节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
// 移除最近最少被访问条件之一,通过覆盖此方法可实现不同策略的缓存
// LinkedHashMap是默认返回false的,我们可以继承LinkedHashMap然后复写该方法即可
// 例如 LeetCode 第 146 题就是采用该种方法,直接 return size() > capacity;
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
通过上述代码,我们就已经知道了只要复写 removeEldestEntry() 即可,而条件就是 map 的大小不超过 给定的容量,超过了就得使用 LRU 了!然后根据题目给定的语句构造和调用:
其主要是两个构造方法,一个是继承 HashMap ,一个是可以选择 accessOrder 的值(默认 false,代表按照插入顺序排序)来确定是按插入顺序还是读取顺序排序。
//调用父类HashMap的构造方法。
public LinkedHashMap() {
super();
accessOrder = false;
}
// 这里的 accessOrder 默认是为false,如果要按读取顺序排序需要将其设为 true
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
最后该题解法如下:
class LRUCache extends LinkedHashMap<Integer,Integer> {
int capacity=10;
public LRUCache(int capacity) {
super(capacity,0.75F,true);
this.capacity=capacity;
}
public int get(int key) {
return this.getOrDefault(key,-1);
}
public void put(int key, int value) {
super.put(key,value);
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size()>capacity;
}
}
完美解决!
参考链接:
https://leetcode.cn/problems/lru-cache/solution/yuan-yu-linkedhashmapyuan-ma-by-jeromememory/