集群的好处
- 高可用性:故障检测及迁移,多节点备份。
- 可伸缩性:新增数据库节点便利,方便扩容。
- 负载均衡:切换某服务访问某节点,分摊单个节点的数据库压力。
集群要考虑的风险
- 网络分裂:群集还可能由于网络故障而拆分为多个部分,每部分内的节点相互连接,但各部分之间的节点失去连接。
- 脑裂:导致数据库节点彼此独立运行的集群故障称为“脑裂”。这种情况可能导致数据不一致,并且无法修复,例如当两个数据库节点独立更新同一表上的同一行时。
@
一,mysql原厂出品
1,MySQL Replication
mysql复制(MySQL Replication),是mysql自带的功能。
原理简介:
主从复制是通过重放binlog实现主库数据的异步复制。即当主库执行了一条sql命令,那么在从库同样的执行一遍,从而达到主从复制的效果。在这个过程中,master对数据的写操作记入二进制日志文件中(binlog),生成一个 log dump 线程,用来给从库的 i/o线程传binlog。而从库的i/o线程去请求主库的binlog,并将得到的binlog日志写到中继日志(relaylog)中,从库的sql线程,会读取relaylog文件中的日志,并解析成具体操作,通过主从的操作一致,而达到最终数据一致。
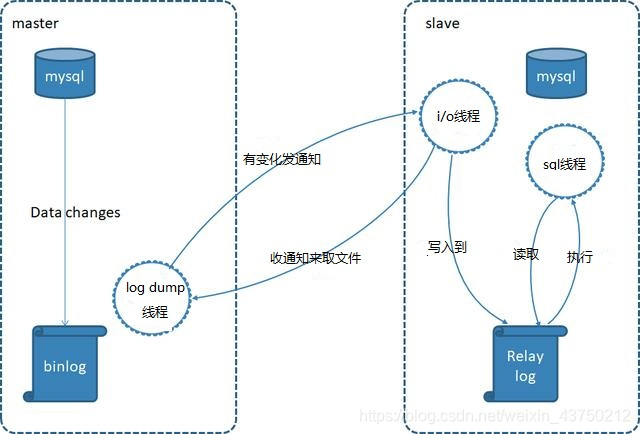
MySQL Replication一主多从的结构,主要目的是实现数据的多点备份(没有故障自动转移和负载均衡)。相比于单个的mysql,一主多从下的优势如下:
- 如果让后台读操作连接从数据库,让写操作连接主数据库,能起到读写分离的作用,这个时候多个从数据库可以做负载均衡。
- 可以在某个从数据库中暂时中断复制进程,来备份数据,从而不影响主数据的对外服务(如果在master上执行backup,需要让master处于readonly状态,这也意味这所有的write请求需要阻塞)。
就各个集群方案来说,其优势为:
- 主从复制是mysql自带的,无需借助第三方。
- 数据被删除,可以从binlog日志中恢复。
- 配置较为简单方便。
其劣势为:
- 从库要从binlog获取数据并重放,这肯定与主库写入数据存在时间延迟,因此从库的数据总是要滞后主库。
- 对主库与从库之间的网络延迟要求较高,若网络延迟太高,将加重上述的滞后,造成最终数据的不一致。
- 单一的主节点挂了,将不能对外提供写服务。
2,MySQL Fabirc
mysql织物(MySQL Fabirc),是mysql官方提供的。
这是在MySQL Replication的基础上,增加了故障检测与转移,自动数据分片功能。不过依旧是一主多从的结构,MySQL Fabirc只有一个主节点,区别是当该主节点挂了以后,会从从节点中选择一个来当主节点。
就各个集群方案来说,其优势为:
- mysql官方提供的工具,无需第三方插件。
- 数据被删除,可以从binlog日志中恢复。
- 主节点挂了以后,能够自动从从节点中选择一个来当主节点,不影响持续对外提供写服务。
其劣势为:
- 从库要从binlog获取数据并重放,这肯定与主库写入数据存在时间延迟,因此从库的数据总是要滞后主库。
- 对主库与从库之间的网络延迟要求较高,若网络延迟太高,将加重上述的滞后,造成最终数据的不一致。
- 2014年5月推出的产品,数据库资历较浅,应用案例不多,网上各种资料相对较少。
- 事务及查询只支持在同一个分片内,事务中更新的数据不能跨分片,查询语句返回的数据也不能跨分片。
- 节点故障恢复30秒或更长(采用InnoDB存储引擎的都这样)。
3,MySQL Cluster
mysql集群(MySQL Cluster)也是mysql官方提供的。
MySQL Cluster是多主多从结构的
就各个集群方案来说,其优势为:
- mysql官方提供的工具,无需第三方插件。
- 高可用性优秀,99.999%的可用性,可以自动切分数据,能跨节点冗余数据(其数据集并不是存储某个特定的MySQL实例上,而是被分布在多个Data Nodes中,即一个table的数据可能被分散在多个物理节点上,任何数据都会在多个Data Nodes上冗余备份。任何一个数据变更操作,都将在一组Data Nodes上同步,以保证数据的一致性)。
- 可伸缩性优秀,能自动切分数据,方便数据库的水平拓展。
- 负载均衡优秀,可同时用于读操作、写操作都都密集的应用,也可以使用SQL和NOSQL接口访问数据。
- 多个主节点,没有单点故障的问题,节点故障恢复通常小于1秒。
其劣势为:
- 架构模式和原理很复杂。
- 只能使用存储引擎 NDB ,与平常使用的InnoDB 有很多明显的差距。比如在事务(其事务隔离级别只支持Read Committed,即一个事务在提交前,查询不到在事务内所做的修改),外键(虽然最新的NDB 存储引擎已经支持外键,但性能有问题,因为外键所关联的记录可能在别的分片节点),表限制上的不同,可能会导致日常开发出现意外。点击查看具体差距比较
- 作为分布式的数据库系统,各个节点之间存在大量的数据通讯,比如所有访问都是需要经过超过一个节点(至少有一个 SQL Node和一个 NDB Node)才能完成,因此对节点之间的内部互联网络带宽要求高。
- Data Node数据会被尽量放在内存中,对内存要求大,而且重启的时候,数据节点将数据load到内存需要很长时间。
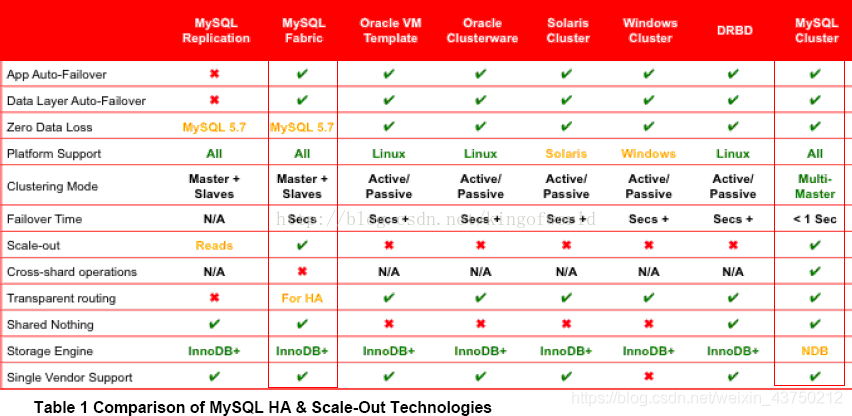
官方的三兄弟的区别对比如下图所示;
二,mysql第三方优化
4,MMM
MMM是在MySQL Replication的基础上,对其进行优化。
MMM(Master Replication Manager for MySQL)是双主多从结构,这是Google的开源项目,使用Perl语言来对MySQL Replication做扩展,提供一套支持双主故障切换和双主日常管理的脚本程序,主要用来监控mysql主主复制并做失败转移。
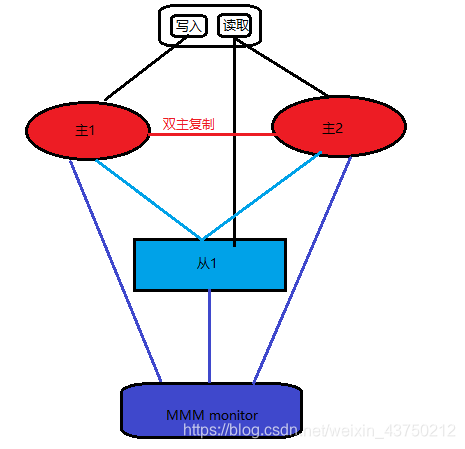
注意:这里的双主节点,虽然叫做双主复制,但是业务上同一时刻只允许对一个主进行写入,另一台备选主上提供部分读服务,以加速在主主切换时刻备选主的预热。
就各个集群方案来说,其优势为:
- 自动的主主Failover切换,一般3s以内切换备机。
- 多个从节点读的负载均衡。
其劣势为:
- 无法完全保证数据的一致性。如主1挂了,MMM monitor已经切换到主2上来了,而若此时双主复制中,主2数据落后于主1(即还未完全复制完毕),那么此时的主2已经成为主节点,对外提供写服务,从而导致数据不一。
- 由于是使用虚拟IP浮动技术,类似Keepalived,故RIP(真实IP)要和VIP(虚拟IP)在同一网段。如果是在不同网段也可以,需要用到虚拟路由技术。但是绝对要在同一个IDC机房,不可跨IDC机房组建集群。
5,MHA
MHA是在MySQL Replication的基础上,对其进行优化。
MHA(Master High Availability)是多主多从结构,这是日本DeNA公司的youshimaton开发,主要提供更多的主节点,但是缺少VIP(虚拟IP),需要配合keepalived等一起使用。
要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库。
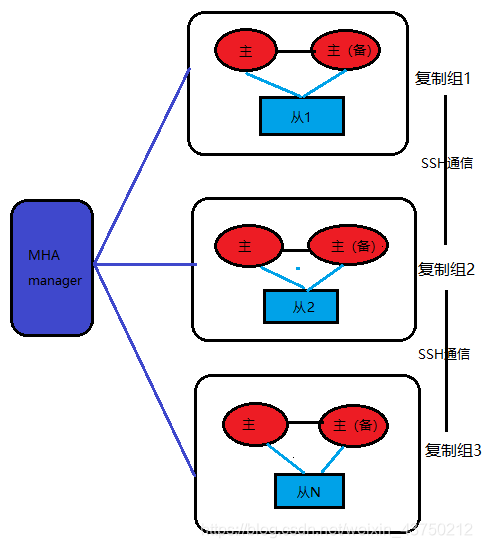
就各个集群方案来说,其优势为:
- 可以进行故障的自动检测和转移
- 具备自动数据补偿能力,在主库异常崩溃时能够最大程度的保证数据的一致性。
其劣势为:
-
MHA架构实现读写分离,最佳实践是在应用开发设计时提前规划读写分离事宜,在使用时设置两个连接池,即读连接池与写连接池,也可以选择折中方案即引入SQL Proxy。但无论如何都需要改动代码;
-
关于读负载均衡可以使用F5、LVS、HAPROXY或者SQL Proxy等工具,只要能实现负载均衡、故障检查及备升级为主后的读写剥离功能即可,建议使用LVS
6,Galera Cluster
Galera Cluster是由Codership开发的MySQL多主结构集群,这些主节点互为其它节点的从节点。不同于MySQL原生的主从异步复制,Galera采用的是多主同步复制,并针对同步复制过程中,会大概率出现的事务冲突和死锁进行优化,就是复制不基于官方binlog而是Galera复制插件,重写了wsrep api。
异步复制中,主库将数据更新传播给从库后立即提交事务,而不论从库是否成功读取或重放数据变化。这种情况下,在主库事务提交后的短时间内,主从库数据并不一致。
同步复制时,主库的单个更新事务需要在所有从库上同步 更新。换句话说,当主库提交事务时,集群中所有节点的数据保持一致。
对于读操作,从每个节点读取到的数据都是相同的。对于写操作,当数据写入某一节点后,集群会将其同步到其它节点。

就各个集群方案来说,其优势为:
- 多主多活下,可对任一节点进行读写操作,就算某个节点挂了,也不影响其它的节点的读写,都不需要做故障切换操作,也不会中断整个集群对外提供的服务。
- 拓展性优秀,新增节点会自动拉取在线节点的数据(当有新节点加入时,集群会选择出一个Donor Node为新节点提供数据),最终集群所有节点数据一致,而不需要手动备份恢复。
其劣势为:
- 能做到数据的强一致性,毫无疑问,也是以牺牲性能为代价。
三,依托硬件配合
不同主机的数据同步不再依赖于MySQL的原生复制功能,而是通过同步磁盘数据,来保证数据的一致性。
然后处理故障的方式是借助Heartbeat,它监控和管理各个节点间连接的网络,并监控集群服务,当节点出现故障或者服务不可用时,自动在其他节点启动集群服务。
7,heartbeat+SAN
SAN:共享存储,主库从库用的一个存储。SAN的概念是允许存储设施和解决器(服务器)之间建立直接的高速连接,通过这种连接实现数据的集中式存储。
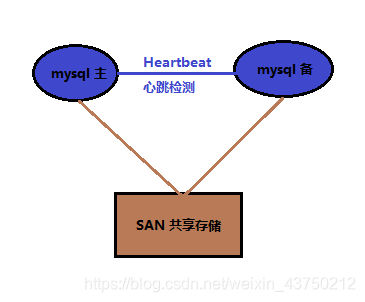
就各个集群方案来说,其优势为:
-
保证数据的强一致性;
-
与mysql解耦,不会由于mysql的逻辑错误发生数据不一致的情况;
其劣势为:
- SAN价格昂贵;
8,heartbeat+DRDB
DRDB:这是linux内核板块实现的快级别的同步复制技术。通过各主机之间的网络,复制对方磁盘的内容。当客户将数据写入本地磁盘时,还会将数据发送到网络中另一台主机的磁盘上,这样的本地主机(主节点)与远程主机(备节点)的数据即可以保证明时同步。
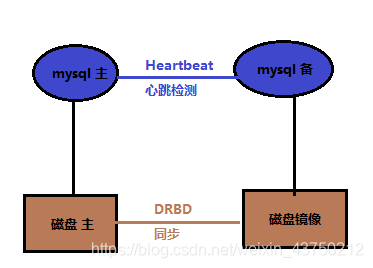
就各个集群方案来说,其优势为:
-
相比于SAN储存网络,价格低廉;
-
保证数据的强一致性;
-
与mysql解耦,不会由于mysql的逻辑错误发生数据不一致的情况;
其劣势为:
-
对io性能影响较大;
-
从库不提供读操作;
四,其它
9,Zookeeper + proxy
Zookeeper使用分布式算法保证集群数据的一致性,使用zookeeper可以有效的保证proxy的高可用性,可以较好的避免网络分区现象的产生。
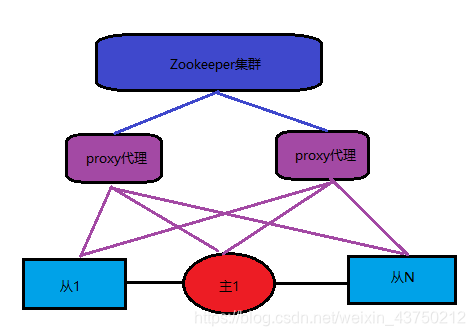
就各个集群方案来说,其优势为:
- 扩展性较好,可以扩展为大规模集群。
缺其劣势为:
- 搭建Zookeeper 集群,在配置一套代理,整个系统的逻辑变得更加复杂。
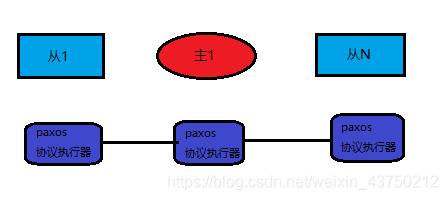
10,Paxos
分布式一致性算法,Paxos 算法处理的问题是一个分布式系统如何就某个值(决议)达成一致。这个算法被认为是同类算法中最有效的。Paxos与MySQL相结合可以实现在分布式的MySQL数据的强一致性。
三、 Galera Cluster介绍
它是一个集成了galera插件的mysql集群(采用了多主集群架构)。更是是一种新型的,数据不共享的,高度冗余的高可用方案(数据一致性,完整性,性能无法与单台单台机器相比)。目前galera cluster有两个版本。一个是Percona Xtradb Cluster以及Mariadb Cluster。
Galera Cluster优缺点:
优点:
多主结构:数据在任何时候读写都是最新的(比如:数据的更新操作,当一个节点收到请求后都需要与其他节点进行校验,校验之后在更新本地数据,最后在同步)
故障切换:在数据库出现故障时,因为支持多点写入,切换容易
热插拔:在服务期间,如果数据库挂了,只需要停止该节点的数据库服务,不影整个集群(其他节点)。而且如果该节点修复后,只需启动数据库服务即可自动加入集群环境(原集群配置环境还存在)
同步复制:在集群种的不同节点之间数据同步,没有延迟,而且单个节点数据库挂了之后,数据不会丢失
并发复制:支持并行执行,提升性能
自动节点克隆:在新增节点时,增量数据(即在基础数据上发送变化的数据)或基础数据无需手动备份提供,因为新增节点上mysql服务一旦开启,它将自动拉取在线节点数据。
缺点:
新节点加入需要全量拷贝数据,有时会导致数据同步的提供者无法提供读写,只有等待整个拷贝完成。
只支持innodb存储引擎
而且集群的性能取决于集群中性能最差的节点的性能(全局校验过程)
Galera Cluster工作流程(不一定准确,自己的理解):

Galera Cluster包括两个组件
1. Galera replication library (galera-3)
2.WSREP:MySQL extended with the Write Set Replication
提示:PXC(Percona XtraDB Cluster)是Percona对Galera的实现。
MariaDB Galera Cluster是mariadb对Galera的实现。
两者都需要至少三个节点(至多8个节点),且不能安装mysql-server或mairadb-server
RPM包
PXC:
https://mirrors.tuna.tsinghua.edu.cn/percona/release/$releasever/RPMS/$basearch
MariaDB Galera Cluster:
https://mirrors.tuna.tsinghua.edu.cn/mariadb/mariadb-5.5.X/yum/centos7-amd64/
先介绍PXC(Percona XtraDB Cluster)
1.使用到的端口:(4个)
3306:数据库对外服务的端口
444:请求SST(State Snapshot Transfer,全量数据传送)的端口号
4567:组成员之间进行沟通的端口号
4568:用于传输IST(Incremental State Transfer,增量数据传送)的端口号
2.节点状态的变化阶段

OPEN:节点启动成功,尝试连接到集群时的状态
PRIMARY:节点已处于集群中,在新节点加入并选取donor进行数据同步时的状态
JOINER:节点处于等待接收同步文件时的状态
JOINERD:节点完成数据同步工作,尝试保持和集群进度一致时的状态
SYNCED:节点正常提供服务时的状态,表示已经同步完成并和集群进度保持一致
DONOR(数据的提供者):节点处于为新加入的节点提供全量数据时的状态
3.GCache模块:
在PXC中一个特别重要的模块,它的核心功能就是为每个节点缓存当前最新的写集。
如果有新节点加入进来,就可以把新数据的增量传递给新节点,而不需要再使用SST传输方式,这
样可以让节点更快地加入集群中。建议优化的参数如下:
gcache size:缓存写集增量信息的大小,它的默认大小是128MB,通过wsrep_provider_options
参数设置,建议调整为2GB~4GB范围,足够的空间便于缓存更多的增量信息
gcache.mem_size:GCache中内存缓存的大小,适度调大可以提高整个集群的性能
gcache.page_size:如果内存不够用(GCache不足),就直接将写集写入磁盘文件中
演示percona XtraDB Cluster(pxc5.7)
环境准备:
以三台主机为例(centos7),各自的ip地址分别为:10.0.0.113,10.0.0.114,10.0.0.115
如果主机安装了mysql或mariadb必须先卸载。
关闭防火墙和selinux,时间要同步:
关闭防火墙方法:
查看状态:systemctl status firewalld
临时关闭:systemctl stop firewalld
永久关闭:systemctl disable firewalld
禁用selinux方法:
查看状态:getenforce
临时禁用:setenforce 0
永久关闭:将/etc/sysconfig/selinux中SELINUX改为disabled,必须重启才能有效。
为了演示方便区分主机(节点),这里将其主机名分别改为pxe1,pxe2,pxe3
方法如下:
临时修改:hostname pxe1
永久关闭:hostnamectl set-hostname pxe1
此处使用清华大学的yum源为例,安装pxc5.7。
[root@pxe1 ~]# vi /etc/yum.repos.d/pxe.repo
[percona]
name=percona_repo
baseurl=https://mirrors.tuna.tsinghua.edu.cn/percona/release/$releasever/RPMS/$basearch
enabled=1
gpgcheck=0
然后将其传送到10.0.0.114,10.0.0.115主机上,并且安装Percona-XtraDB-Cluster-57(这里可以用任何方式【如:scp命令,ansible工具等】)
[root@pxe1 ~]#scp /etc/yum.repos.d/pxe.repo 10.0.0.114:/etc/yum.repos.d/pxe.repo
[root@pxe1 ~]#scp /etc/yum.repos.d/pxe.repo 10.0.0.115:/etc/yum.repos.d/pxe.repo
[root@pxc1 ~]#yum install Percona-XtraDB-Cluster-57 -y
[root@pxc2 ~]#yum install Percona-XtraDB-Cluster-57 -y
[root@pxc3 ~]#yum install Percona-XtraDB-Cluster-57 -y
#此命令可以查看安装后生成的所有文件
[root@pxc1 ~]#rpm -ql rpm -ql Percona-XtraDB-Cluster-server-57
在各个节点上分别配置mysql及集群配置文件:
/etc/my.cnf:主配置文件
也包括其他三个配置文件:mysqld.cnf,mysqld_safe.cnf,wsrep.cnf
修改的文件:
1. mysqld.cnf(可选),为例保证其server_id与各个节点不同,以及log_bin二进制日志功能
2./etc/percona-xtradb-cluster.conf.d/wsrep.cnf。必需改
[root@pxe1 ~]# grep -Ev "^#|^$" /etc/percona-xtradb-cluster.conf.d/wsrep.cnf
[mysqld]
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so #指定Galera库的路径
wsrep_cluster_address=gcomm://10.0.0.113,10.0.0.114,10.0.0.115 #Galera集群中各节点地址。gcomm:// [地址使用组通信协议]
binlog_format=ROW #二进制日志的格式。目前只支持row格式
default_storage_engine=InnoDB #指定默认引擎,但目前只支持innoDB
wsrep_slave_threads= 8
wsrep_log_conflicts
innodb_autoinc_lock_mode=2 #只能设置为2,设置为0或1时无法正确处理思索问题
wsrep_cluster_name=pxc-cluster #集群名称,可自定义,但各个节点需与之保持一致
wsrep_node_address=10.0.0.113 #本节点在Galera集群中的通信地址,也是本机ip地址
wsrep_node_name=pxc-cluster-node-1 #本节点在Galera集群中的通信名称,可自定义
pxc_strict_mode=ENFORCING #是否限制PXC启用正在试用阶段的功能,ENFORCING是默认值,表示不启用
wsrep_sst_method=xtrabackup-v2 #state_snapshot_transfer(SST)使用的传输方法
wsrep_sst_auth="sstuser:s3cretPass" 在SST传输时需要用到的认证凭据,格式为:"用户:密码",可自定义,但各个节点需与之保持一致.而且此账号还不存在,需要创建并授权
[root@pxe2 ~]# grep -Ev "^#|^$" /etc/percona-xtradb-cluster.conf.d/wsrep.cnf
[mysqld]
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
wsrep_cluster_address=gcomm://10.0.0.113,10.0.0.114,10.0.0.115
binlog_format=ROW
default_storage_engine=InnoDB
wsrep_slave_threads= 8
wsrep_log_conflicts
innodb_autoinc_lock_mode=2
wsrep_node_address=10.0.0.114
wsrep_cluster_name=pxc-cluster
wsrep_node_name=pxc-cluster-node-2
pxc_strict_mode=ENFORCING
wsrep_sst_method=xtrabackup-v2
wsrep_sst_auth="sstuser:s3cretPass"
[root@pxe3 ~]# grep -Ev "^#|^$" /etc/percona-xtradb-cluster.conf.d/wsrep.cnf
[mysqld]
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
wsrep_cluster_address=gcomm://10.0.0.113,10.0.0.114,10.0.0.115
binlog_format=ROW
default_storage_engine=InnoDB
wsrep_slave_threads= 8
wsrep_log_conflicts
innodb_autoinc_lock_mode=2
wsrep_node_address=10.0.0.115
wsrep_cluster_name=pxc-cluster
wsrep_node_name=pxc-cluster-node-3
pxc_strict_mode=ENFORCING
wsrep_sst_method=xtrabackup-v2
wsrep_sst_auth="sstuser:s3cretPass"
启动第一个节点(在三个主机选任何一个主机都可以,这里选择10.0.0.113)。注意:第一个节点的启动方法与后面的节点启动方法不一样
[root@pxc1 ~]#systemctl start mysql@bootstrap.service
#查看端口是否开启3306,4567
[root@pxc1 ~]#ss -tnl
登录mysql数据库,创建/etc/percona-xtradb-cluster.conf.d/wsrep.cnf文件中的“sstuser:s3cretPass”账户和密码并授权。
注意,第一次登录的账户默认为root@'localhost',密码随机的,需要查看/var/log/mysqld.log获取。
[root@px1~]# grep '\<password\>' /var/log/mysqld.log 
#登录mysql数据库
[root@px1~]# mysql -uroot -p')+yf3W;qBe8Y'
#修改密码
mysql> ALTER USER root@'loclahost' IDENTIFIED BY '123456';
#创建sstuser用户并授权
mysql> CREATE USER ssuser@'locallhost' IDENTIFIED BY 's3cretPass';
mysql> GRANT RELOAD,LOCK TABLES,PROCESS,REPLICATION CLIENT ON *.* TO ssuser@'locallhost';
#查看相关变量,重点关注wsrep_local_state,wsrep_cluster_size(集群中节点数量),wsrep_cluster_status等
mysql> SHOW VAROABLES LIKE 'wsrep%'\G;
#查看单个变量的值
mysql> SHOW VAROABLES LIKE '变量名';
启动集群中的其他节点(10.0.0.114,10.0.0.115).而且启动之后数据会自动与10.0.0.113主机同步(故其他机器上登录数据库的账户都可以使用root@'loaclhost' 123456),启动方法如下:
[root@pxc2 ~]#systemctl start mysql
[root@pxc3 ~]#systemctl start mysql
[root@pxc2 ~]#ss -tnl #查看端口3306,4567端口
验证集群状态,即验证搭建是否成功。
在任何节点查看集群状态,如果wsrep_cluster_size变量显示为3,说明成功
[root@pxc3 ~]#mysql -uroot -p123456
mysql> SHOW VARIABLES LIKE 'wsrep_cluster_size';
验证数据是否同步:
1. 在任何主机上创建一个数据库,然后再其他主机上查询。
mysql> CREATE DATABASE DB1;
mysql> SHOW DATABASES;
2.利用xshell软件,同时再三个节点数据库创建一个数据库,查看执行结果。(只有一个执行成功,其他提示数据库已存在)
mysql> CREATE DATABASE DB2;
至此基于pxc的集群环境已搭建成功并且已验证完成。其中有些命令是手打上去的;有些东西也是按自己理解写的;如果有错,欢迎评论,谢谢!
后期如何将一个节点加到该集群中:比如pxc4 (ip:10.0.0.116),简单过程如下:
1.拷贝/etc/yum.repos.d/pxc.repo到新主机上
2.安装 Percona-XtraDB-Cluster-57 程序
3.修改/etc/percona-xtradb-cluster.conf.d/wsrep.cnf中某些字段。如下
[root@pxc3 ~]#vi /etc/percona-xtradb-cluster.conf.d/wsrep.cnf
[mysqld]
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
wsrep_cluster_address=gcomm://10.0.0.113,10.0.0.114,10.0.0.115,10.0.0.116 #修改此处
binlog_format=ROW
default_storage_engine=InnoDB
wsrep_slave_threads= 8
wsrep_log_conflicts
innodb_autoinc_lock_mode=2
wsrep_node_address=10.0.0.116 #修改此处
wsrep_cluster_name=pxc-cluster
wsrep_node_name=pxc-cluster-node-4 #修改此处
pxc_strict_mode=ENFORCING
wsrep_sst_method=xtrabackup-v2
wsrep_sst_auth="sstuser:s3cretPass"
4.启动mysql服务
5.查看及验证
演示二:MariaDB Galera Cluster
环境准备:
以三台主机为例(centos8),各自的ip地址分别为:10.0.0.115,10.0.0.116,10.0.0.117
如果主机安装了mysql或mariadb必须先卸载。
关闭防火墙和selinux,时间要同步
为了演示方便区分主机(节点),这里将其主机名分别改为mgc1,mgc2,mgc3
详细过程:
1.三台主机分别安装mariadb-server-galera.x86_64(AppStream里有,如果没有需要配置epel源)包。

这里有个小技巧,利用xshell远程三台主机,然后再xshell菜单栏选择-->工具-->发送键输入到所有会话中。
[root@mgc1 ~]# yum install mariadb-server-galera.x86_64 -y
2.修改/etc/my.cnf.d/galera.cnf文件,将三台主机ip加到wsrep_cluster_address字段中。并且该协议为gcomm://(记住一定的改)

3.将修改的文件分别传输到其他两台主机上,并且覆盖。
[root@mgc1 ~]# scp /etc/my.cnf.d/galera.cnf 10.0.0.116:/etc/my.cnf.d/galera.cnf
[root@mgc1 ~]# scp /etc/my.cnf.d/galera.cnf 10.0.0.117:/etc/my.cnf.d/galera.cnf
4.启动第一个节点,并且连接数据库(账户默认为root,密码为空)查看变量wsrep_cluster_size的值。
[root@mgc1 ~]#galera_new_cluster
[root@mgc1 ~]#mysql
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cluster_size';

5.在启动其他主机的mariadb服务,在任何一台主机上查看wsrep_cluster_size的值
[root@mgc2 ~]#systemctl start mariadb
[root@mgc3 ~]#systemctl start mariadb
6.验证(与pxc一样,1.新增一条数据,查看各节点之间数据是否同步。2.同时执行创建一个数据库操作,看各个节点之间执行结果 3. 停止某一个节点,查看wsrep_cluster_size是否有变动。4.新增一台主机加入到集群中,看数据是否自动同步...)
提示:如果在centos7上搭建MariaDB Galera Cluster(5.5)集群环境,需要配置源。
参考仓库:https://mirrors.tuna.tsinghua.edu.cn/mariadb/mariadb-5.5.X/yum/centos7-amd64/
后续操作与演示二一致,只是启动第一个节点时需要有区别:
首次启动时,需要初始化集群,在其中一个节点上执行命令:/etc/init.d/mysql start --wsrep-new-cluster
至此基于MariaDB Galera Cluster的集群环境已搭建成功并且已验证完成。其中有些命令是手打上去的;有些东西也是按自己理解写的;如果有错,欢迎评论,谢谢!