Yolo系列较为热门且新的网络就是以下三种
YOLOv5
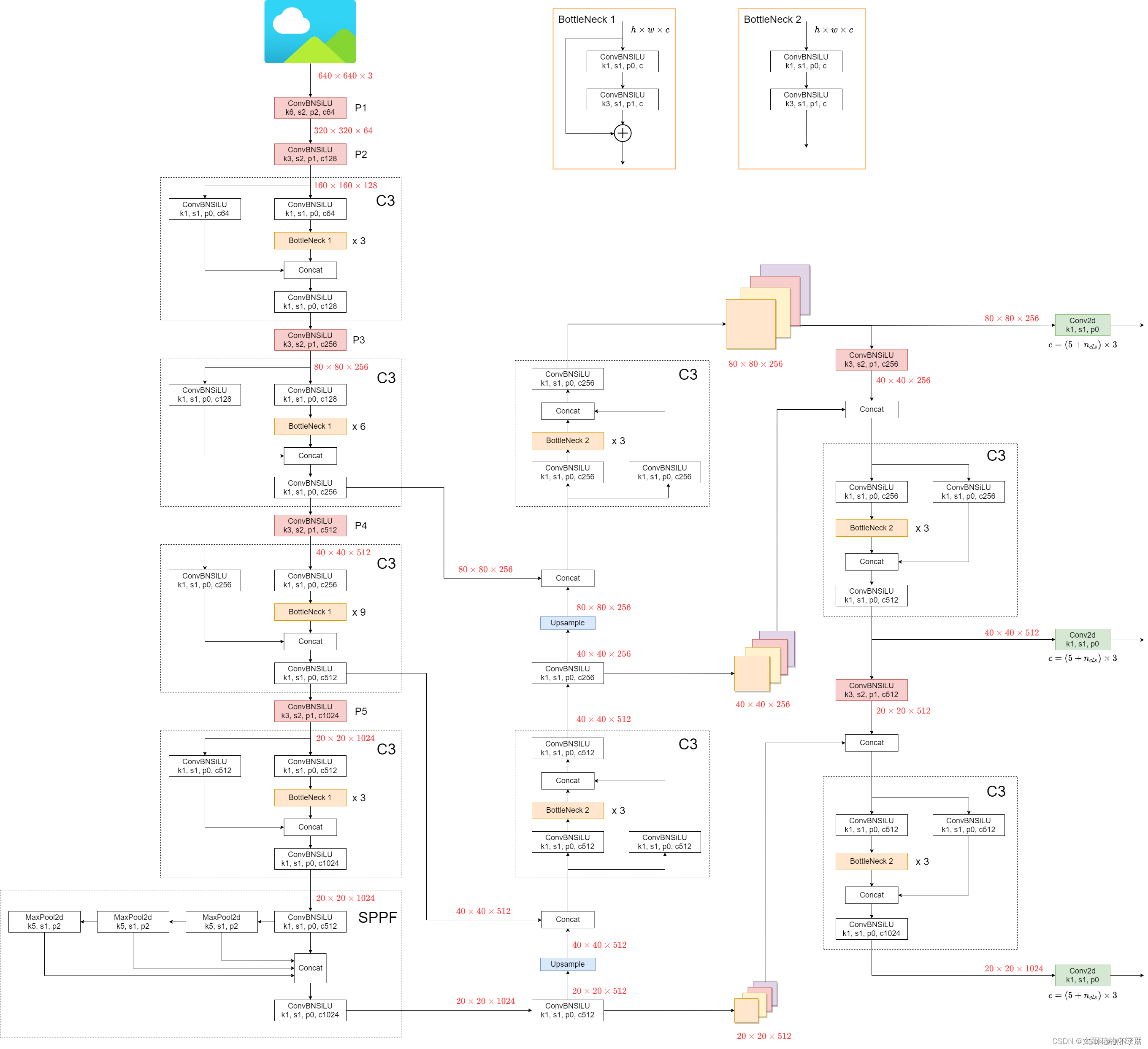
YOLOv7
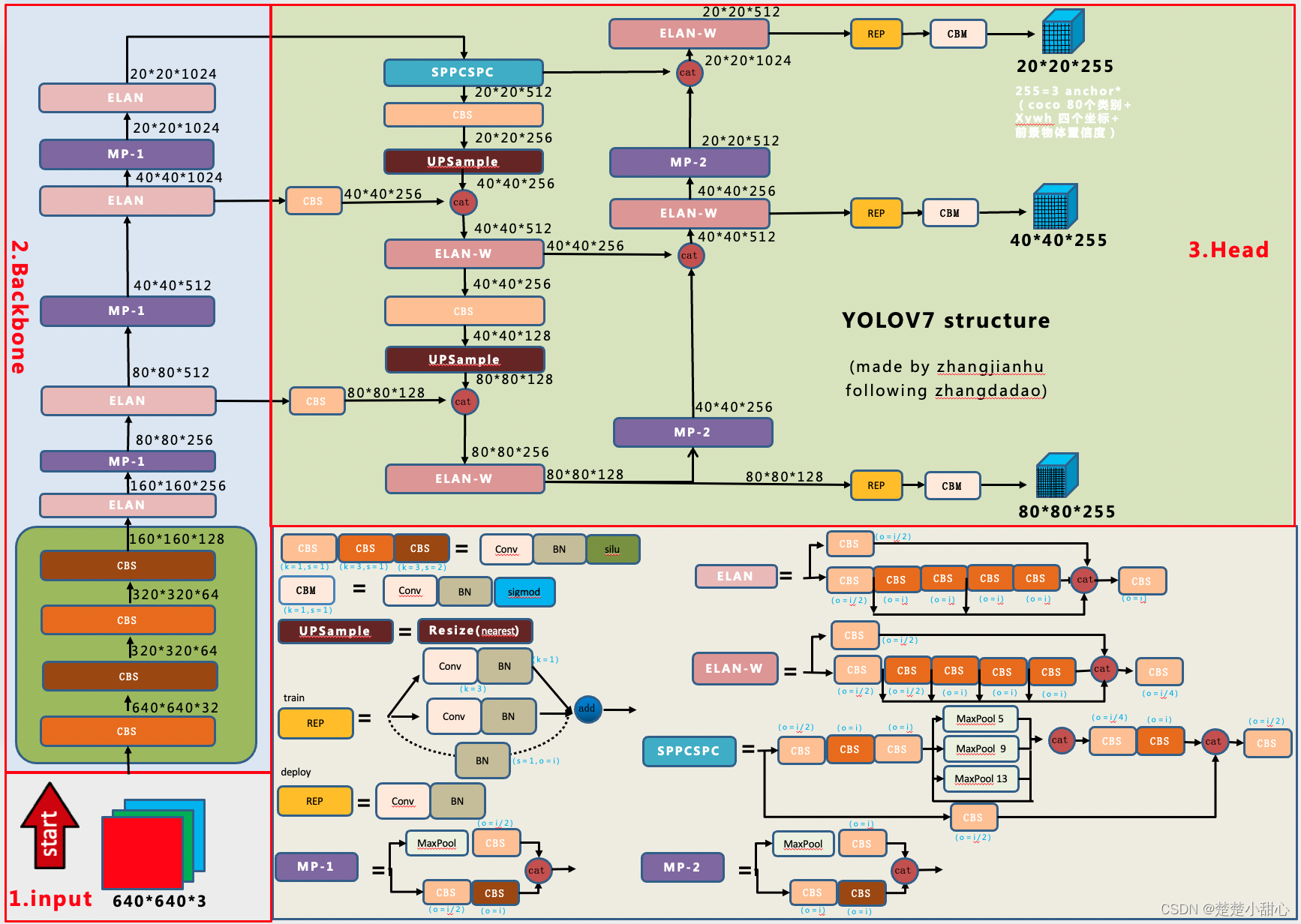
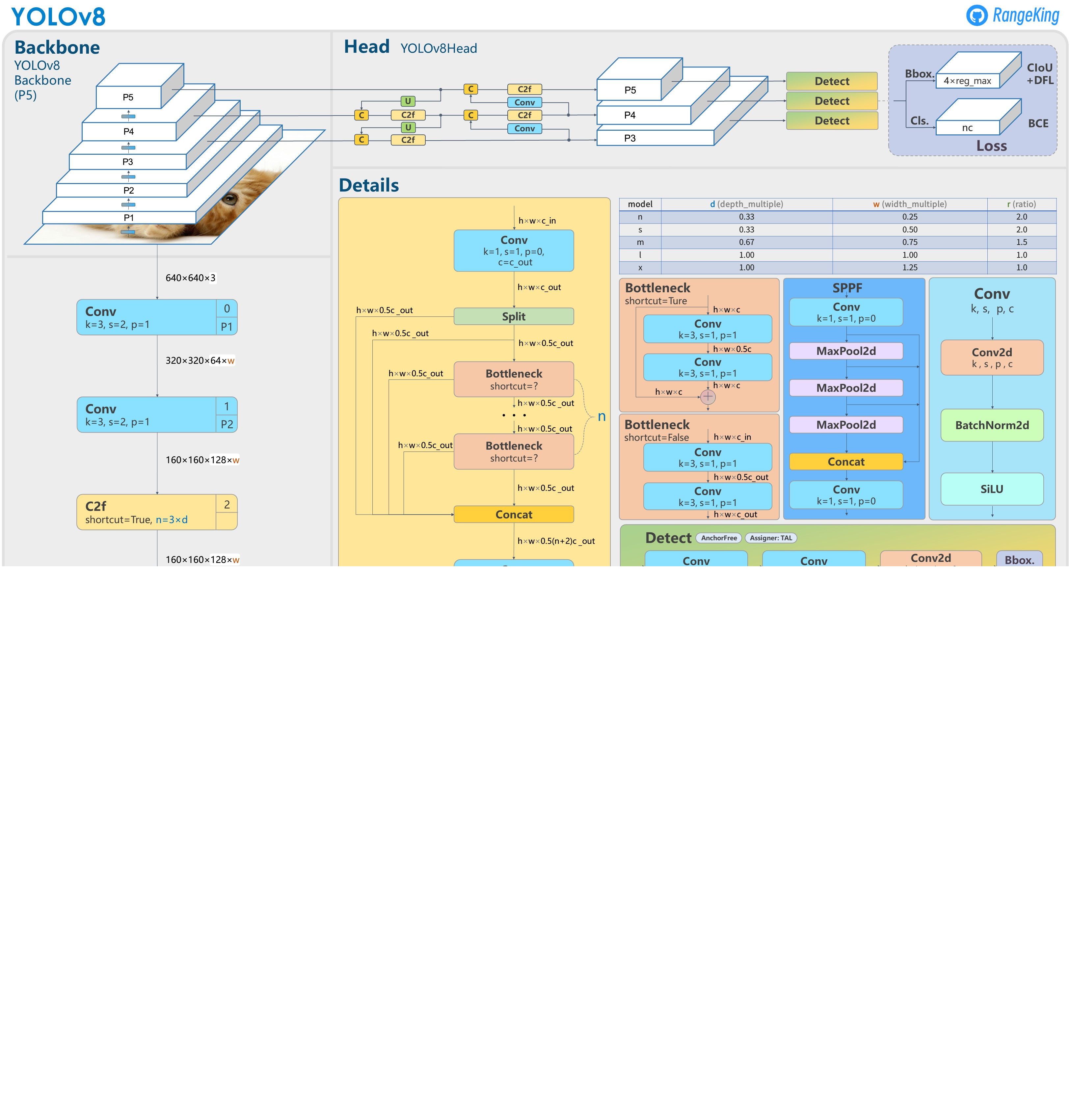
YOLOv8
每个Yolo系列的经典网络相信网上都有很多大牛都会进行解析以及讲解,这篇博客主要是作为知识备忘录以及知识点补充介绍这些网络模型下面的下模块。
C3模块
针对C3模块,其主要是借助CSPNet提取分流的思想,同时结合残差结构的思想,设计了所谓的C3 Block,这里的CSP主分支梯度模块为BottleNeck模块,也就是所谓的残差模块。同时堆叠的个数由参数n来进行控制,也就是说不同规模的模型,n的值是有变化的。

作用:
1 在新版yolov5中,作者将BottleneckCSP(瓶颈层)模块转变为了C3模块,其结构作用基本相同均为CSP架构,只是在修正单元的选择上有所不同,其包含了3个标准卷积层以及多个Bottleneck模块(数量由配置文件.yaml的n和depth_multiple参数乘积决定)
2 C3相对于BottleneckCSP模块不同的是,经历过残差输出后的Conv模块被去掉了,concat后的标准卷积模块中的激活函数也由LeakyRelu变为了SiLU(同上)。
3 该模块是对残差特征进行学习的主要模块,其结构分为两支,一支使用了上述指定多个Bottleneck堆叠和3个标准卷积层,另一支仅经过一个基本卷积模块,最后将两支进行concat操作。
class C3(nn.Module):
"""CSP Bottleneck with 3 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
"""Initialize the CSP Bottleneck with given channels, number, shortcut, groups, and expansion values."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x):
"""Forward pass through the CSP bottleneck with 2 convolutions."""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
C2f
YOLOv7通过并行更多的梯度流分支,放ELAN模块可以获得更丰富的梯度信息,进而或者更高的精度和更合理的延迟。
C2f模块的结构图如下:
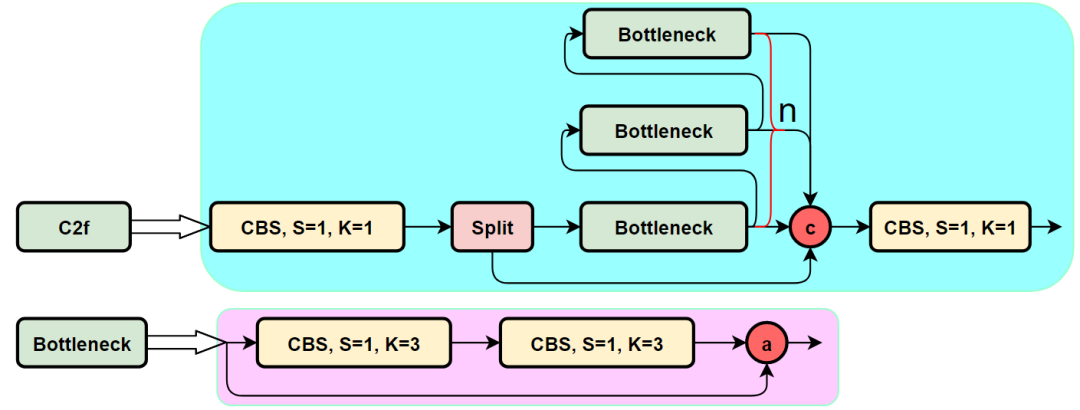
我们可以很容易的看出,C2f模块就是参考了C3模块以及ELAN的思想进行的设计,让YOLOv8可以在保证轻量化的同时获得更加丰富的梯度流信息。
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
Bottleneck模块
1 先将channel 数减小再扩大(默认减小到一半),具体做法是先进行1×1卷积将channel减小一半,再通过3×3卷积将通道数加倍,并获取特征(共使用两个标准卷积模块),其输入与输出的通道数是不发生改变的。
2 shortcut参数控制是否进行残差连接(使用ResNet)。
3 在yolov5的backbone中的Bottleneck都默认使shortcut为True,在head中的Bottleneck都不使用shortcut。
4 与ResNet对应的,使用add而非concat进行特征融合,使得融合后的特征数不变。
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
SPP模块
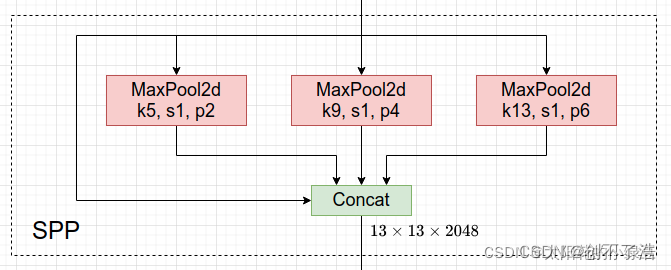
1 SPP是空间金字塔池化的简称,其先通过一个标准卷积模块将输入通道减半,然后分别做kernel-size为5,9,13的maxpooling(对于不同的核大小,padding是自适应的)。
2 对三次最大池化的结果与未进行池化操作的数据进行concat,最终合并后channel数是原来的2倍。
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
SPPF
V5的6.0版本后Neck部分将SPP换成成了SPPF(Glenn Jocher自己设计的),两者的作用是一样的,但后者效率更高。SPP结构如下图所示,是将输入并行通过多个不同大小的MaxPool,然后做进一步融合,能在一定程度上解决目标多尺度问题。
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1, c2, k=5):
"""
Initializes the SPPF layer with given input/output channels and kernel size.
This module is equivalent to SPP(k=(5, 9, 13)).
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""Forward pass through Ghost Convolution block."""
x = self.cv1(x)
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
参考:
https://blog.csdn.net/qq_41398619/article/details/127665092