数据降维PCA-核心思路-换基
将数据放到新的低维基中
例:二维数据投影到一维坐标系下表示:

选择不同的基可以对同样一组数据给出不同的表示,如果基的数量少于向量本身的维数,则可以达到降维的效果
因此我们首先需要找一个新的基,使得新的数据在新基上的方差最大,协方差最小,之后对新的基进行筛选,抛弃特征值小的基,详细过程及解释如下:
方差:同一维变量间的离散程度,离散程度越大,数据在该维的损失值越小
协方差:表示数据集之间的相关性,当协方差为0时候,数据完全不相关。
如上图所示的协方差矩阵为:
| 0 | 0 |
|---|---|
| 0 | 4.5 |
假设这就是新基,则满足协方差为0,选择所有方差最大的轴作为新的降维基进行换基操作,则可得到降维后的数据。
如何初步确定新基?
通过上面我们可以知道:
新旧基可以通过方差以及协方差进行联系
相同数据通过不同的基来体现
据此求新基:
已知:原始数据为X,原始数据的协方差矩阵为C,
未知:新基Y,换基后的数据H,新基的协方差矩阵为D
根据协方差矩阵的计算公式:
结合可知:
可得:
因此,我们需要根据以上公式找到这个新基Y
从另一个角度分析目标协方差矩阵与当前协方差矩阵,他们之间只是在不同的基下去体现,新的协方差矩阵是对角阵,表示对新的基的拉伸变换,因此新的基为旧协方差矩阵的特征向量。(相似对角化)设特征向量为E,则
根据对称矩阵的性质:对称矩阵的特征向量为正交阵,且每一列的值为特征值,则:
据此,我们可以推出新基Y矩阵就是C的特征向量矩阵E
初步换基后我们需要进行降维
对每个特征向量对应的特征值除以总特征值,求出特征值的占比。
对每个特征向量的特征值从大到小进行排序,之后从大到小求和,当和达到0.9以上时我们认为可以接受,即90%的数据可以在新的基上被区分。而特征值越小,表示数据在该特征向量对应的轴上离散程度越小,越难以区分,拿上面的手画图为例,这就是一个转换后的基,要想达到降维的目的,我们需要选择特征值大的y轴作为筛选后的基。
降维后的数据为:
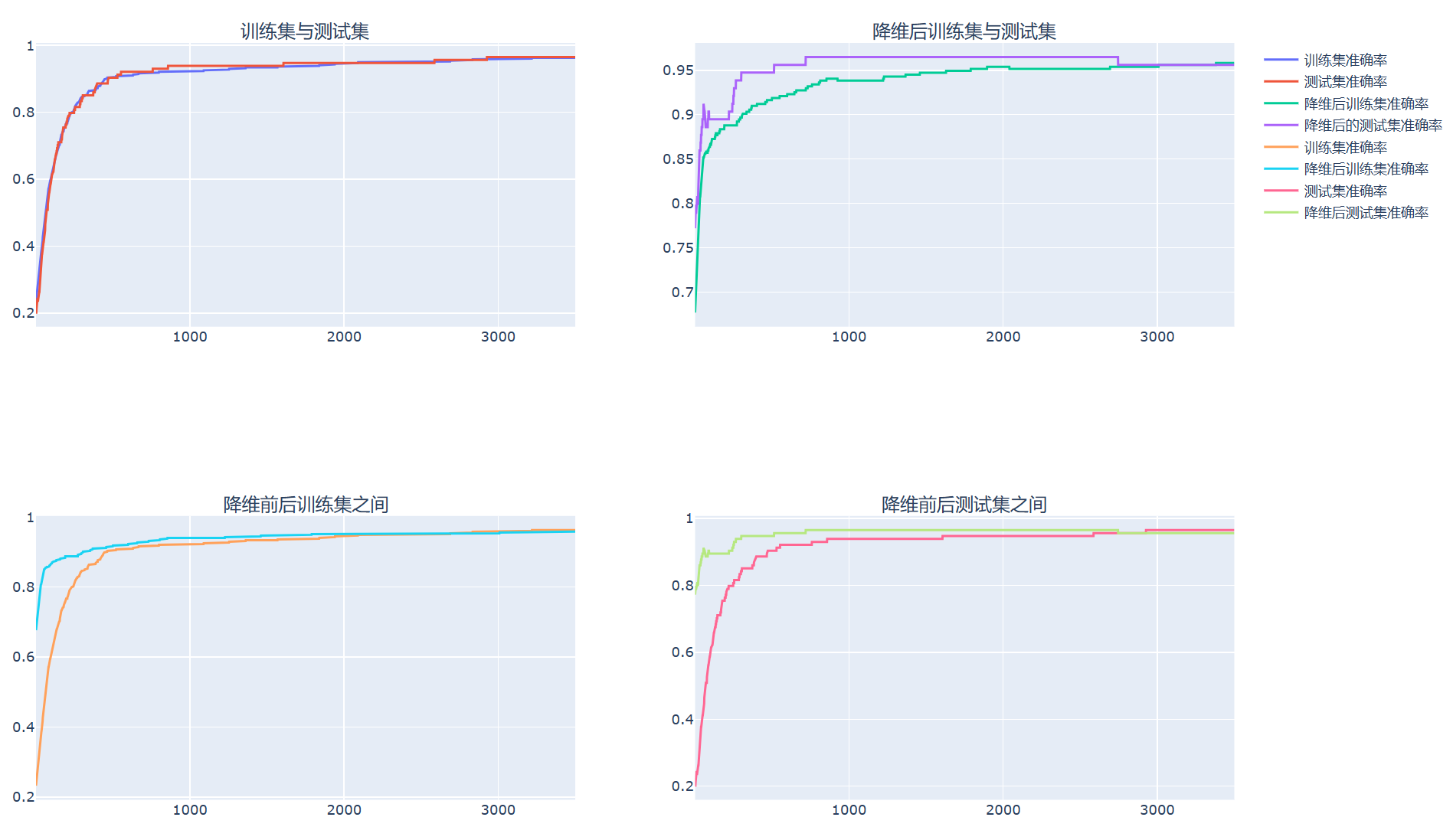
处理后进行逻辑回归分类训练,结果展示: