LoRA:Low-Rank Adaptation Of Language Model
O、摘要
本文提出一种新的大模型(本文主要指 transformer)微调方法:低秩自适应。其主要特性为,冻结预训练模型的权重,并将可训练低秩矩阵,分解到模型的每一层,从而大大减少下游任务的训练参数量。与经过 Adam fine-tuning 的 GPT-3 175B 相比,LoRA 将可训练参数量,减少了1万倍,GPU 内存需求减少了 3 倍。同时在原理上,LoRA 相较于2019年提出的 Adapter tuning,不会引入额外的推理延迟。在 RoBERTa、DeBERTa、GPT-2 和 GPT-3 上, LoRA 在模型质量方面的表现与 fine-tuning 相当甚至更佳。
一、方法介绍
本文的 Motivation 是大规模的自然语言处理预训练模型的微调。曾经许多人试图通过调整部分参数、学习外部模块,来控制可训练的参数量。这些做法,除了每个任务的预训练模型外,只需要存储和加载少量特定于任务的参数。然而,已有的方法经常会引入推理延迟(加长 forward 的时间),更重要的是,这些方法往往无法匹配 fine-tuning 的 baseline,从而只能在效率和模型质量之间做出权衡。这在某种程度上也说明,这些方法并没有很好的表征微调的本质。
根据已有的论文研究,我们学习到的模型是 over-parametrized,模型学到的参数实际上存在于较低的 “内在秩”,即可以用更少的参数就足以表征整个参数空间的信息,这促使我们提出了低秩自适应的方法 LoRA。类似 fine-tuning 的更新过程:
LoRA 的基本思想是,将多步的 \(\alpha\Delta W\) 积累转化一个与 W 维度一致的矩阵,根据 “内在秩” 的理论,进一步将 W 分解为两个低秩矩阵的乘积。神经网络包含许多执行矩阵乘法的 Dense Layers,这些层中的权重矩阵通常是满秩的。根据前文所述的 “内在秩” 的启发,本文将 tuning 的更新积累 \(\Delta W\) 转化为两个低秩矩阵 A 和 B 的乘法:
本文对 A 进行随机高斯初始化,而对 B 使用全零初始化。除此之外,本文还提出一种 scale 方法,能避免超参数的调参:
We then scale \(\Delta Wx\) by \(\alpha/r\), where \(α\) is a constant in \(r\). When optimizing with Adam, tuning \(α\) is roughly the same as tuning the learning rate if we scale the initialization appropriately. As a result, we simply set \(α\) to the first \(r\) we try and do not tune it. This scaling helps to reduce the need to retune hyperparameters when we vary \(r\) .
虽然但是,这句话我不是很明白,留着慢慢琢磨
如下图,左侧的 W 部分,是预训练模型的权重,这部分是 frozen 的,在 tuning 过程,只需训练 B 和 A 的参数即可。其中 A 是降维矩阵,将输入 d 维投影到低维 r 空间里,B 则将输入 r 还原到原本的高维空间里。在实验中,这个低维维度 r 甚至可以是 2 或者 1,并能收获很好的效果。
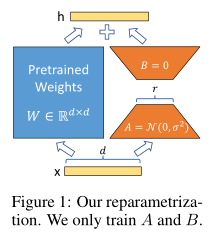
LoRA 的四个关键优势:
- 预训练模型参数共享,切换任务只需要切换小型 LoRA 模块(上面的矩阵 A B)即可,从而显著降低任务切换的开销。
- LoRA 的训练更加有效,并将硬件的门槛降低 3 倍,因为 LoRA 只需要优化小得多的低秩矩阵。
- LoRA 在部署时,只需要将训练后的矩阵与冻结权重合并,不会引入推理延迟。
- LoRA 与许多先前的方法正交(比较新颖就是说),并且可以与其中许多方法组合,譬如前缀调优。
二、tuning 的问题定义
假设有一个预训练的自回归语言模型 \(P_\Phi (y|x)\),其中 x 可以看作 prompt ,y 可以看作 answer。 它有诸多下游任务。在 full fine-tuning 过程中,模型初始化为预训练的权重 \(\Phi_0\) 并且针对下面的优化目标进行梯度更新 \(\Phi_0 + \Delta\Phi\):
即在训练集 \(Z\) 上,最大化给定 \((x,y)\) 的自回归推理过程中的对数似然。推理过程为,根据输入 \(x\) 以及 \(y\) 的前 \(t\) 维部分,通过模型预测 y 的 \(t+1\) 维的分布,找到对应的正确的 \(y_t\) 的概率,并计算对数似然和,以此作为训练目标。
本文的训练目标,是通过一个更加 parameter-efficient 方法,来获得 \(\Delta\Phi = \Delta\Phi(\Theta)\) ,其中 \(\Theta\) 表示 LoRA 中的可训练参数,即系列低秩矩阵:
在 GPT-3 模型的例子中,\(\Delta\Phi(\Theta)\) 的参数量是 \(\Phi\) 的万分之一。
三、相关工作
除了 Transformer 外,这部分还陈述了 prompt engineering 与 fine-tuning 等诸多调参方法。
这部分留着单独做一个 tuning 方法的综述趴~
四、Understanding the Low-Rank Updates
- Transformer 中,应该在哪些权重矩阵上应用 LoRA?
- LoRA 中,如何选择最优的 \(r\) ?
- \(\Delta W\) 与 \(W\) 之间有什么关系?
本文将研究重点放在 GPT-3 175B(Transformer 架构)上,并且从这三个问题出发,依据实验对 LoRA 进行了进一步解释。
Q1
在给定的有限参数预算下,我们应该采用模型中哪些权重矩阵来应用 LoRA,使得下游任务的性能最高?
本文在 GPT-3 175B 上设置了 18M 的参数预算,在此基础上,如果我们只适应一种类型的注意力矩阵(譬如所有的 \(W_q\)),则对应的 LoRA 低秩矩阵 \(r = 8\);类似的,如果适应两种,则 \(r=4\),以此类推,实验结果如下:
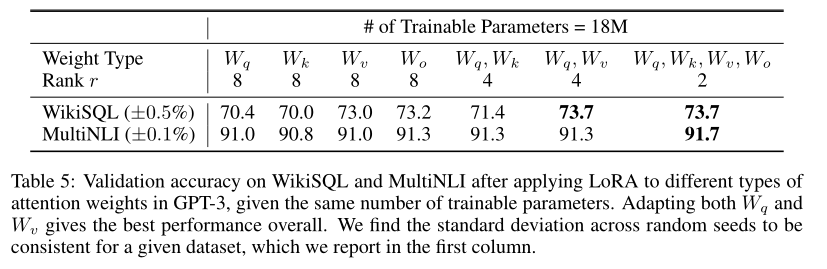
这说明,LoRA 适应更多矩阵,会比适应较大秩的单一矩阵效果更好。
Q2
LoRA 的最优 “内在秩” \(r\) 如何选择?
本文针对三种适应矩阵种类情况,分别对不同的 r 进行实验:
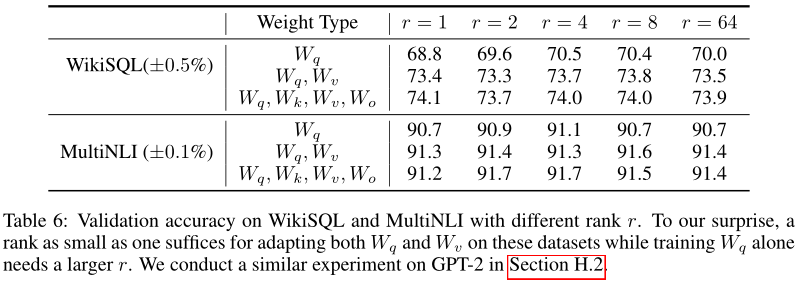
结果显示,r 在非常小的时候,就已经能得到非常高的得分,且过多增加 r 并不能显著增加模型的 tuning 效果,这也证实了理论的有效性。
本文还从不同 r 对应的子空间相似度的层面验证了实验结果,通过奇异值分解 \(r=8\) 和 \(r=64\) 所学习到的自适应矩阵,得到右奇异酉矩阵,并针对这两个矩阵中前 \(i(j)\) 个奇异向量张成的子空间计算相似度。结果表明,对应于 top singular vector(即前几个奇异向量)的方向重叠显著,而其他方向则不重叠。其中,二者的 \(\Delta W_v(\Delta W_q)\) 之间,共享维度为1的子空间,这也解释了为什么 \(r = 1\) 时GPT-3 下游任务也表现优异。其他方向不重叠的解释为,这些方向可能包含训练期间积累的大部分随机噪声,因此,自适应矩阵的确可以具有非常低的秩。
Q3
\(\Delta W\) 是否与 \(W\) 高度相关?或者从数学上来讲,\(\Delta W\) 是否包含在 \(W\) 的 top singular directions 上?
本文通过计算 \(U^TWV^T\) 将 W 投影到 \(\Delta W\) 的 \(r\) 维子空间上,其中 \(U/V\) 是 \(\Delta W\) 的左右奇异向量矩阵。本文,比较了 \(||U^TWV^T||_F\) 和 \(||W||_F\) 的 Frobenius 范数。作为参照,本文还将 \(U/V\) 替换为 \(W\) 或者一个随机矩阵的前 r 个左右奇异向量构成的矩阵。结果如下

- 与随机矩阵相比,\(\Delta W\) 和 \(W\) 的相关性更强,这表明 \(\Delta W\) 实际上是放大了 \(W\) 中已经存在的一些特征
- \(\Delta W\) 并没有重复 \(W\) 的 top singular directions(0.32 << 21.67),而是放大了 \(W\) 中没有强调的方向。
- 放大因子 \(\frac{||\Delta W_q||_F}{||U^TW_qV^T||}\) 即 \(\Delta W_q\) 与 \(W_q\) 投影的 Frobenius 范数的比值,很大。譬如 \(r=4\) 时,放大因子为 \(21.5\approx 6.91/0.32\).
五、未来工作方向
- LoRA 可以与其他有效的自适应方法相结合,有可能提供正交改进。
- 微调或 LoRA 背后的机制尚不清楚——如何将预训练期间学习到的特征转化为下游任务?我们相信 LoRA 比完全微调更容易解决这个问题
- 我们主要依靠启发式方法来选择 LoRA 应用的权重矩阵。有没有更有原则的方法?
- 最后,\(∆W\) 的 rank-deficient 特征表明 W 也可能是 rank-deficient,这也可以作为未来作品的灵感来源。
- Adaptation Language Low-Rank Model LoRAadaptation language low-rank model prompt-tuning adaptation language low-rank 论文翻译adaptation low-rank models udalm unsupervised adaptation language wind differentially model-agnostic adaptation evaluation language large model language模型large model language cascades论文model low-rank lora