咱就说家人们,今天真的是大乌鱼集美们,出差在外地,网吧遇到一个下头男,对着电脑自言自语说网吧麦的效果竟然比家里还好,嘴里一边嘟囔一边嘿嘿贱笑。
结果发现竟然是屏幕中的我自己。。。
现在的网吧都叫网咖了?早二十年前满大街都是网吧,现在人们都用手机就能轻松遨游因特网了,网吧确实挺难找的,但是我晚上睡不着,想到还有视频没水,就地图搜了一个网吧出来码字。。。
范式化数据(normalize data)
咱们这个6.3小节学习的内容听上去挺唬人的,我在文档里找到两处讲这个主题的章节,
一个原文是“Normalizing State Shape”,翻译成“State 归一化”,还有一个是咱们今天学的内容,原文是“Normalizing Data”,翻译成“范式化”,因为存在翻译引起的歧义,我认为我们不应该再咬文嚼字、通过字面含义去理解这个行为,我把这个normalize行为总结成下面一段话:
把相对来说组织比较混乱的数据按照一种固定的形式,整理成有规律、组织清晰的的数据的行为----“数据标准化行为”,标准化后的数据,查找效率更高,且可以极大减少UI组件不必要的重渲染。
我上网查了好多,发现这个概念主要是用在关系型数据库的数据存储设计中,这个概念有几种原则,这几种原则会让查找数据更方便、且效率更高。
我想我们最好不要展开讲,更不要联想到数据库上,咱们仅仅就redux文档上介绍的内容简单说,请看看下面的表格。

假设Post表就是为了存储一个小品,每一行,都会存储一个小品的作者、内容和摘抄出来的金句,其中内容一栏的具体细节我们给他省略掉。
看上去,这种数据存储形式没有太大问题是吧,但是我提一杯:
- 全国有很多人都叫范伟,你怎么确定表格里的范伟就是演小品的范伟?
- 我年龄很大了,所以我现在还知道“谢谢啊”是范伟的台词,假设有另外一个小品,台词是“鸡你太美”,你怎么确定是谁的台词?
又或者,“观众朋友们,我想死你们啦”这句话在很多部作品里都出现了,你能确定具体是谁说的吗?(比如其他演员揶揄冯巩的时候就说过这话。。。)
所以,我们需要有手段把每个数据都“唯一化”,就好比Post表的id项目,起码在id项目里,id为post1的小品是和赵本山、高秀敏、范围的“卖拐”唯一对应,假设表里存储另一个某小学文艺汇演中翻拍的卖拐,我们很容易就知道,两个卖拐不一样,因为他们id不同捏!
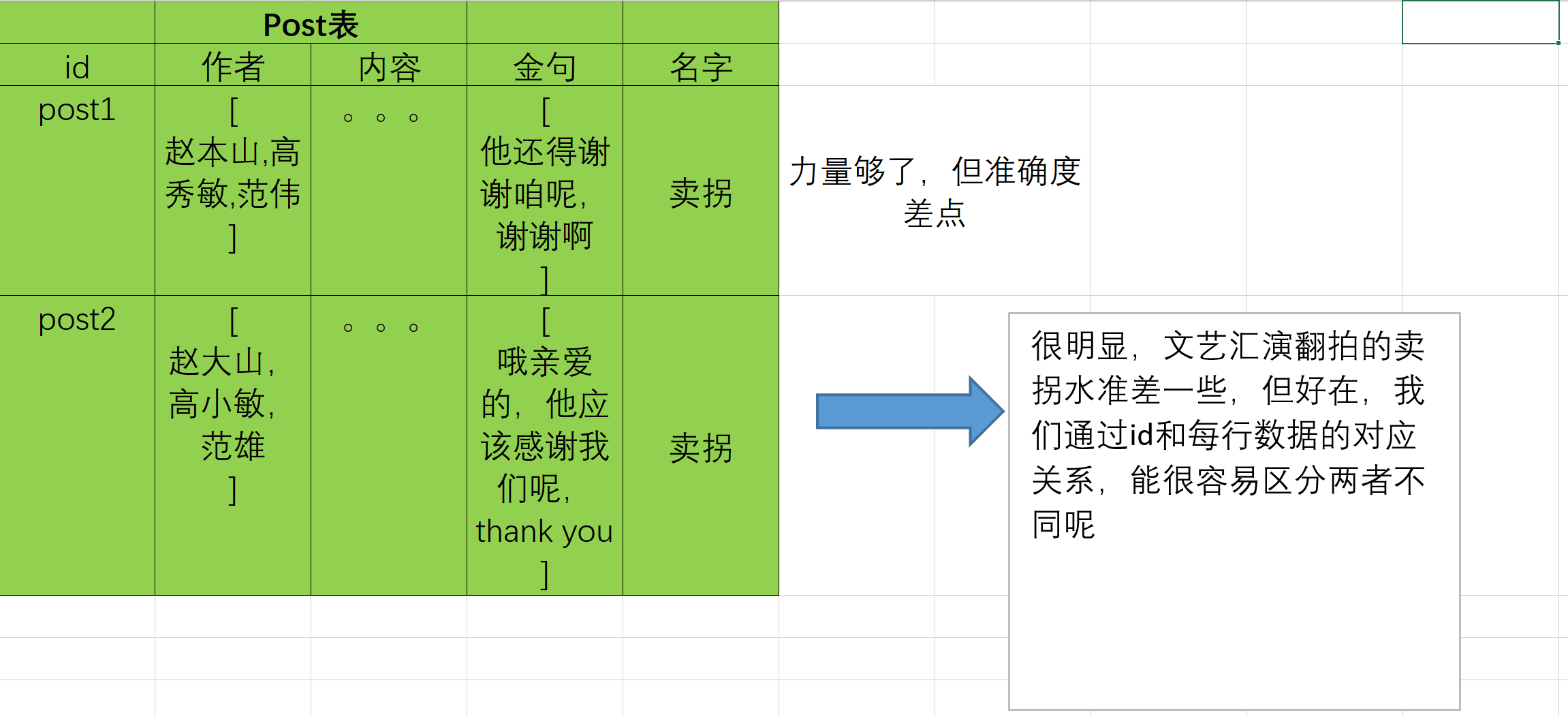
那么下面我们只要着手形成数据的“唯一性”,请看下表:

上面的新表格里,作者一栏变成了一个数组,里边每条数据都有“唯一性”,可以确定本山大叔不是本赵本水模仿的,也能确定某一句“缘分啊”是范伟的台词,而不是朱军或者周涛在过场时候跟观众逗闷子的闲篇儿,类似的金句一栏也变成了数组,但是,但是啊!
另外一个问题也很明显:
数据存在“冗余”,而多处重复的数据会对数据的更新造成很大的阻碍,咱们看我特意标记为蓝色的“范围”,
很明显,这里就是我写错了,应该是范伟,但是假设我们要修复 范伟 的名字错误的这个问题, 就要在多处更改数据,这种多处存在同一个数据的情况,我们就称为冗余,这种冗余也必须要避免。若是你想强行地兼顾多个位置,很大可能是,你会不知不觉犯下更多错误。
那么怎么解决这个问题呢???
很简单辣!你想想,你在工作中遇到交织在一起的问题怎么解决?不也是把具体问题分类对待,这里也是一样的!
只要把数据分类,让任何类型的数据在 state 中都有自己的 “表”,请看下面的表呢:
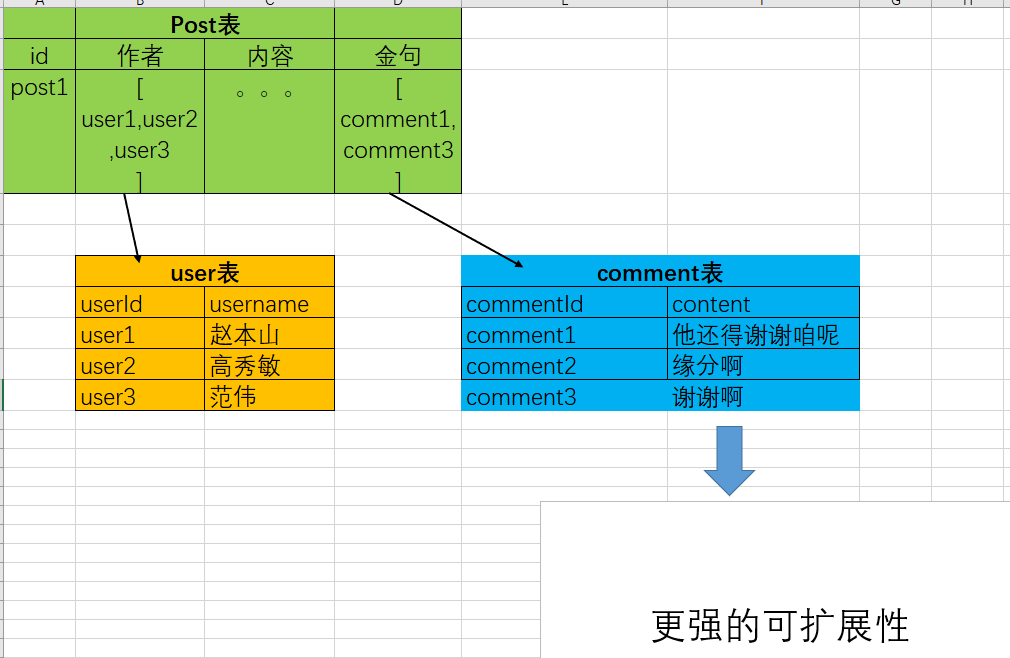
相对来说,这是一种用空间换时间、用空间降低复杂性的做法,数据原本存在Post表一个表中,现在分别存储在Post、User、Comment三个表中,而且Post和另外两个表 通过“唯一标识”来建立了联系,这确实就是关系型数据库的基本概念,这也是为什么在一开始讲data normalization与关系型数据库有关系。不过我们还是不深究。
规范化的redux State数据的几个原则
另外,这样的东东还不能直接应用到redux的数据规范化中,请看下面的关于 redux 数据规范化的四个原则:
- 任何类型的数据在 state 中都有自己的 “表”。
- 任何 “数据表” 应将各个项目存储在对象中,其中每个项目的 ID 作为 key,项目本身作为 value。
- 任何对单个项目的引用都应该根据存储项目的 ID 来完成。
- 为每一张表的数据创建一个ID数组,尽可能使用ID数组来渲染本表内容,如果本表的数据需要排序,ID 数组应该用于排序。
上面的第1条,我们已经通过excel介绍过了,只要把数据按照类型进行拆分就可以,
第2-4条,请看下面的代码:
未规范化的:
[
{ id: "user1", firstName: "f1", lastName: "l1" },
{ id: "user2", firstName: "f2", lastName: "l2" },
{ id: "user3", firstName: "f3", lastName: "l3" },
];
规范化的:
{
users: {
ids: ["user1", "user2", "user3"],
entities: {
"user1": {id: "user1", firstName, lastName},
"user2": {id: "user2", firstName, lastName},
"user3": {id: "user3", firstName, lastName},
}
}
}
可以看到,规范化的数据有两个固定的成员,一个是存储id的数组,另外一个是按照具体数据的唯一标识符“id”为key,具体数据为值的形式存储的对象 组成的对象合集。
之前我们在6.3节中,已经介绍过渲染PostList的具体细节,我们通过接受posts数据,并在内部遍历posts数组,渲染页面,这导致了PostList组件的不必要重渲染。
后来我们通过改写PostList,为其传入postIdList,而在子组件Excerpt中使用id获取对应的数据渲染页面,这就避免了父组件和其余数据不变的子组件不必要重渲染。
要注意,postIdList之前是通过遍历posts数组查询获得的,而现在规范化的数据中已经存在id数组了,很明显我们可以更简单的通过这个id数组来获取数据和避免不必要的更新。