数据清洗是数据预处理的一部分,是数据分析和建模前必须进行的重要步骤。数据清洗可以帮助我们解决数据中包含的噪声、异常值、缺失值、重复数据等问题,从而提高数据的质量和可靠性。如果不进行数据清洗,可能会影响后续的数据分析和建模结果,甚至产生误导性的结论。因此,在进行任何数据分析和建模之前,必须对数据进行清洗和预处理。
简单的基本操作步骤
一、使用Jupyter Notebook对数据集进行清洗和标注的具体步骤如下:
-
打开Jupyter Notebook,创建一个新的notebook文件。
-
在notebook中导入pandas库,可以使用以下代码:
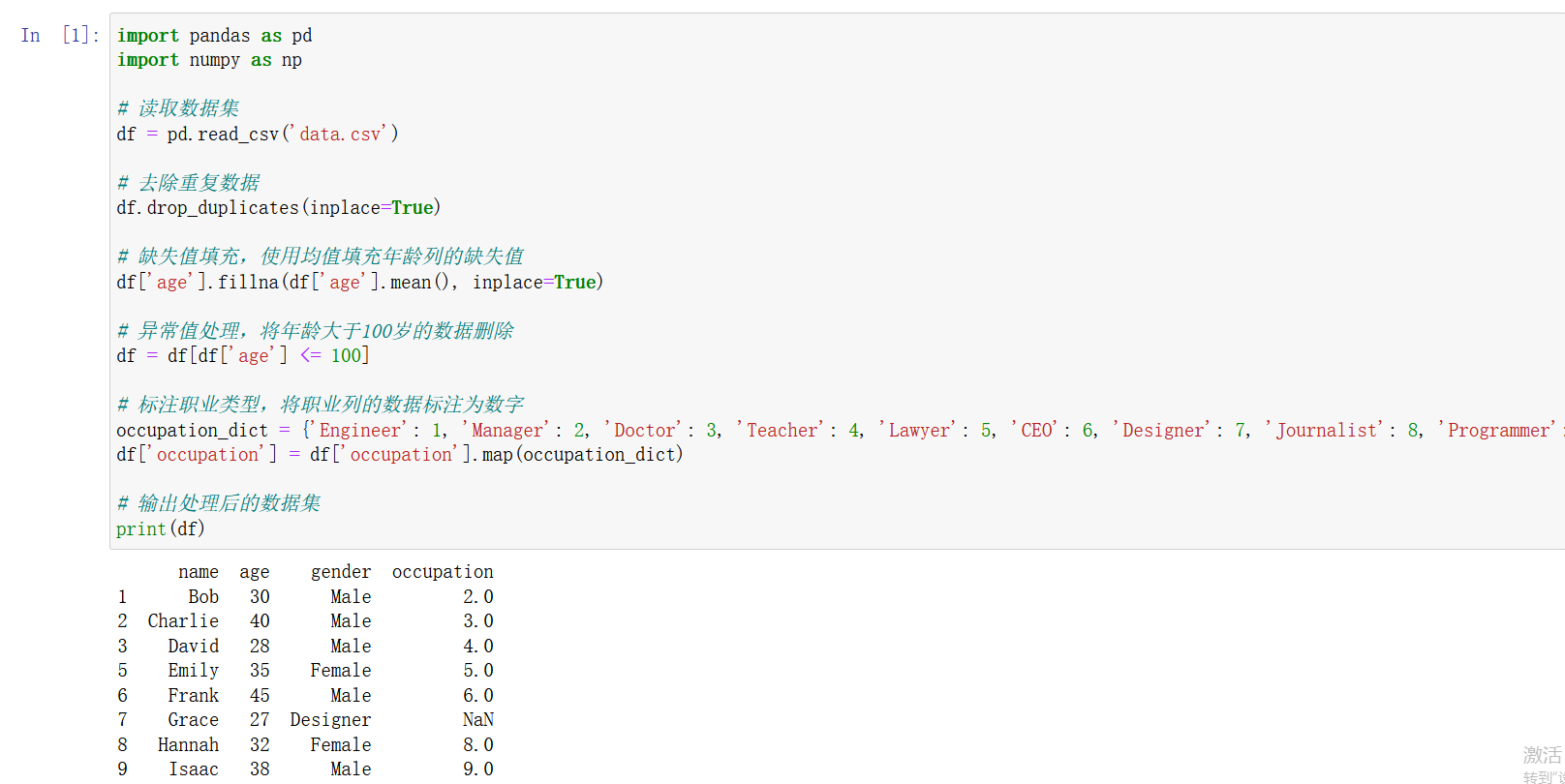
import pandas as pd
-
读取数据集文件,可以使用pandas库中的read_csv()函数,例如:
df = pd.read_csv('data.csv')
其中'data.csv'为数据集文件的路径和文件名,可以根据实际情况进行修改。
-
对数据集进行清洗和标注,可以使用pandas库中的各种函数和方法进行处理,例如:
-
去除重复数据:使用drop_duplicates()函数,例如:
df.drop_duplicates(inplace=True) -
缺失值填充:使用fillna()函数,例如:
df['age'].fillna(df['age'].mean(), inplace=True) -
异常值处理:使用df[]语句删除异常值,例如:
df = df[df['age'] <= 100] -
数据标注:使用map()函数将文本数据标注为数字,例如:
occupation_dict = {'Engineer': 1, 'Manager': 2, 'Doctor': 3, 'Teacher': 4, 'Lawyer': 5, 'CEO': 6, 'Designer': 7, 'Journalist': 8, 'Programmer': 9} df['occupation'] = df['occupation'].map(occupation_dict)
-
-
处理完成后,可以使用to_csv()函数将清洗和标注后的数据保存成新文件,例如:
df.to_csv('cleaned_data.csv', index=False)
其中'cleaned_data.csv'为保存的文件名和路径,index=False表示不保存索引列。
效果
原始数据如下:
name,age,gender,occupation
Alice,250,Female,Engineer
Bob,30,Male,Manager
Charlie,40,Male,Doctor
David,28,Male,Teacher
David,28,Male,Teacher
Emily,35,Female,Lawyer
Frank,45,Male,CEO
Grace,27,Designer
Hannah,32,Female,Journalist
Isaac,38,Male,Programmer
清洗后的数据:
二、也可以用URL导入数据集文件:在Jupyter Notebook中使用pandas库中的read_csv()函数可以直接从URL导入数据集文件,例如:
url = 'https://raw.githubusercontent.com/xxx/data.csv'
df = pd.read_csv(url)
其中url为数据集文件的URL地址,可以将其替换为实际的URL地址。
举例:
可以使用UCI Machine Learning Repository网站提供的Iris数据集作为示例。该数据集包含150个样本,每个样本有4个特征(萼片长度、萼片宽度、花瓣长度和花瓣宽度),共分为3类(山鸢尾、变色鸢尾和维吉尼亚鸢尾)。
为了创建一个包含缺失数据、重复数据和错误数据的数据集,可以使用以下代码对Iris数据集进行修改:
import pandas as pd
import numpy as np
# 读取Iris数据集
iris = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
iris.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'class']
# 添加缺失数据
iris.iloc[1, 1] = np.nan
iris.iloc[3, 2] = np.nan
iris.iloc[6, 0] = np.nan
iris.iloc[8, 3] = np.nan
# 添加重复数据
iris = pd.concat([iris, iris.iloc[0:10]], axis=0).reset_index(drop=True)
# 添加错误数据
iris.iloc[10, 2] = 'error'
iris.iloc[20, 1] = -1
# 保存数据集
iris.to_csv('iris_with_errors.csv', index=False)
这个示例代码中,首先从UCI Machine Learning Repository网站读取Iris数据集,然后对数据集进行以下修改:
- 添加缺失数据:在第2行、第4行、第7行和第9行分别添加缺失数据。
- 添加重复数据:将前10行数据复制一遍,然后添加到原数据集的末尾。
- 添加错误数据:在第11行中,将第3列数据设置为'error';在第21行中,将第2列数据设置为-1。