如何debug
写在前面
-
本节课介绍的内容是基于我个人的经验和网上搜集的资料,可供各位参考,希望大家有所收获;
-
讲授的内容是方法论,提高debug能力的最快方式就是多写多练;
-
debug不是我们的目的,重要的是要吸取教训,不要在同一个地方跌倒两次;
-
最好的debug方式就是少写bug。这需要:
-
足够的代码量的练习;
-
留心学习别人的写法,摸索出适合自己的最佳写法;
-
debug的步骤
第一步 通读代码
先解决编译错误
编译错误, 就是指不能通过编译的问题。 这种错误是最容易排除的。 通常由于变量未定义、忘记分号、括号不匹配等问题,只要遵循编译时的错误提示,对相应的语句进行修改即可。
首先要修复编译错误。
注意:IDE中编译器的报错不总是定位在正确的行。造成这个现象的一个可能原因是,要读到下一行才能知道代码的上一行是否是错误的。比如下图中,第20行末尾漏写了分号,但是编译器要读到20行的右括号后的第一个字符发现不是分号,才确认错误。
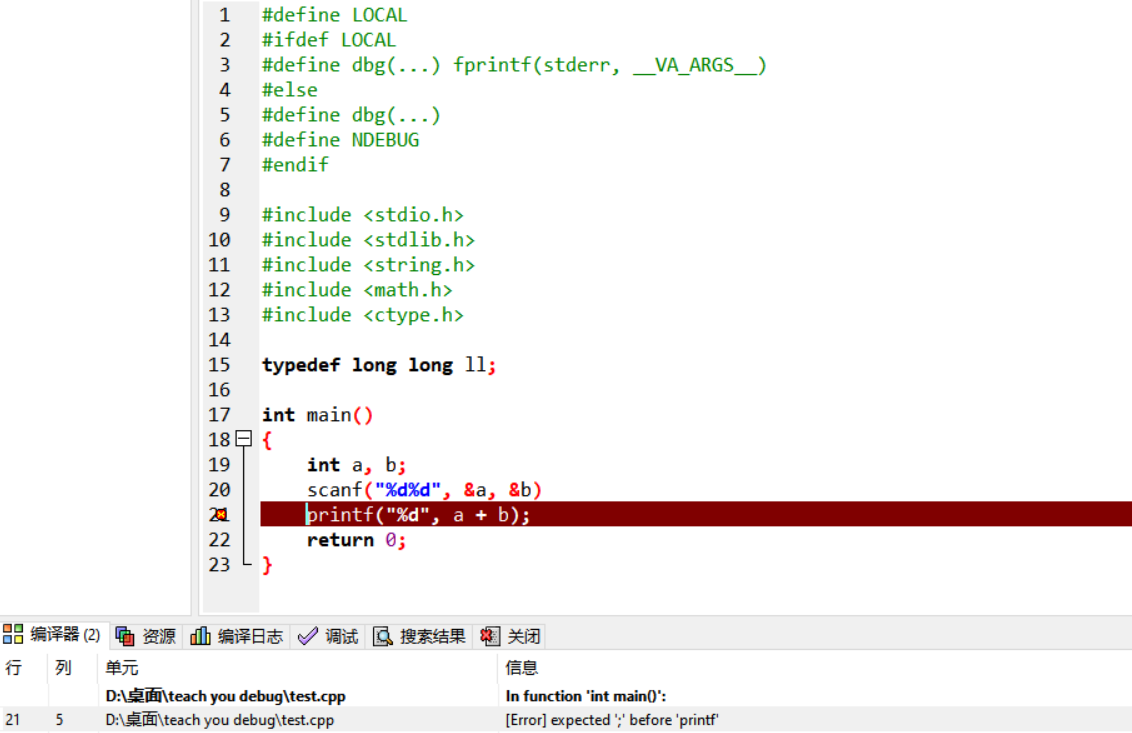
下图的编译错误定位在了第24行,验证了这一点
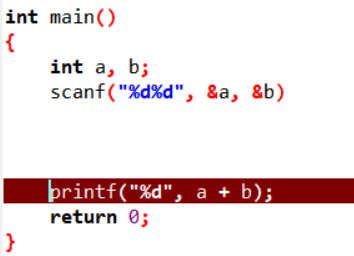
而下图的代码没有报错,再次验证。
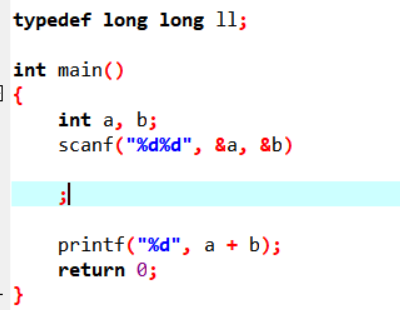
这种问题也和选择什么编辑器有关。比如vscode的提示更加的具体,方便了修复。

但更重要的是预防错误,平时编写程序时应该养成习惯,先定义变量再使用变量,不要
出现错误后再去补。 做题不是打字竞赛,不要忙着向下写程序,写每一行时都要注括
号匹配、句末分号等“语法” 问题。应该采用合理的缩进,保持逻辑结构清晰,还可以使用编译器的高亮匹配功能,避免错误。
静态查错
一些同学编写完程序后测试样例,一看输出结果与正确答案相去万里,就忙于了解程序运行的内部原因,或编写输出语句,或利用编译器的断点功能,往往苦思冥想不得其果,浪费了大量时间,还严重影响心情。事实上,问题往往在于很小的一处失误,通过通读代码(静态查错)就能找出来。
当我们编译成功,输入样例后,发现输出的结果与预期结果不符、没有输出、程序卡住了等等,debug才真正开始。
出错情况分析
- 算法错误
- 算法的时间复杂度太高,超时了(Time Limit Exceeded,TLE)
- 算法的空间复杂度太高,内存超限了(Memory Limit Exceeded,MLE)
- 考虑情况不全
- 做法根本性错误
- 算法正确,代码实现错误
- 程序在运行的时候异常退出(Runtime Error,RE)
- 段错误(Segmentation fault)
- 格式错误,结果与正确结果就差一点(Presentation Error,PE)
- 其他各种错误导致程序运行结果与正确结果不一样(Wrong Answer,WA)
如何通读
- 对照着自己的算法。逐行扫描代码,看代码是否如实实现了我们的做法。
- 是不是没有初始化;
- 是不是应该先做这步,再做另一步;
- 是不是在需要重置变量时没有重置;
- 是不是条件判断分支写错了;
- 是不是遗漏了某些操作;
- 是不是做某个操作的时机错了;
- 是不是在该结束时没有结束(死循环),该
return的时候没有return; - 是不是数组开小了;
- 是不是把0当成除数了(除0);
- ……
- 不漏过每一个字符。逐个字符去看。
- 是不是哪个变量名打错了或者写串了;
- 是不是for循环里内外循环变量是一样的,或者这个循环变量名已经用来定义别的变量了;
- 是不是什么地方漏打了几个字符;
- 是不是
+写成了-,-写成了+; - 是不是对于运算符的优先级不熟悉还不加括号;
- 是不是括号写串了;
- ……
- 通读代码的过程也是复盘我们的算法的过程。可能读着读着就发现做法错了,太理想化,忽略了某些情况。
第二步 输出检验、调试功能
当通读代码实在找不出问题,程序执行过程难以全程在脑子里或纸上模拟时,我们就应该灵活使用输出语句或者打断点调试,一边追踪程序的运行过程和变量的值的变化,一边自己手动或脑内跟着模拟,看是不是一致的。
输出什么?
这个是具体问题具体分析的,可能会输出:
-
有没有成功读到输入;
-
中间变量的值;
-
循环到了第几轮了,这一轮某些开始时某些变量的值和这一轮结束时某些变量的值;
-
进入到某个函数、函数执行过程中和函数执行完成后某些变量的值;
-
某几行程序到底有没有执行,执行了多少次;
-
程序是不是执行到了它不该执行的地方,输出一个标志表示程序经过了某一行;
-
是不是执行完某一行程序就挂了,在这行之后输出检查一下;
-
……
输出的格式
- 输出时不要吝啬,要尽可能具体、易读。
- 当有多个地方输出时,对输出的语句要加以区分。如果不加区分,甚至只输出一个值,很可能会造成混乱,还要去辨认是哪一行输出的,舍本逐末。
- 输出的格式可以是
行号,变量名=值。 - 可以适当输出换行符或者
-----等分隔符号增加让错误信息更易于查找。
例子——冒泡排序
// 错误代码
#include <stdio.h>
#define N 100010
int a[N];
int main()
{
int n;
scanf("%d", &n);
for (int i = 0; i < n; i ++ ) scanf("%d", &a[i]);
for (int i = 0; i < n - 1; i ++ )
{
for (int j = 0; j < n - i - 1; j ++ )
{
if (a[i] > a[i + 1]) // 内外颠倒
{
int t = a[i];
a[i] = a[i + 1];
a[i + 1] = t;
}
}
}
for (int i = 0; i < n; i ++ ) printf("%d ", a[i]);
return 0;
}
// 输出检验的代码
#include <stdio.h>
#define N 100010
int a[N];
int main()
{
int n;
scanf("%d", &n);
for (int i = 0; i < n; i ++ ) scanf("%d", &a[i]);
for (int i = 0; i < n - 1; i ++ )
{
for (int j = 0; j < n - i - 1; j ++ )
{
if (a[i] > a[i + 1]) // 内外颠倒
{
int t = a[i];
a[i] = a[i + 1];
a[i + 1] = t;
}
}
// 把每一轮排序的结果输出,看最大的是不是到最后面了
printf("round: %d\n", i);
for (int j = 0; j < n; j ++ )
printf("%d ", a[j]);
printf("\n\n");
}
for (int i = 0; i < n; i ++ ) printf("%d ", a[i]);
return 0;
}
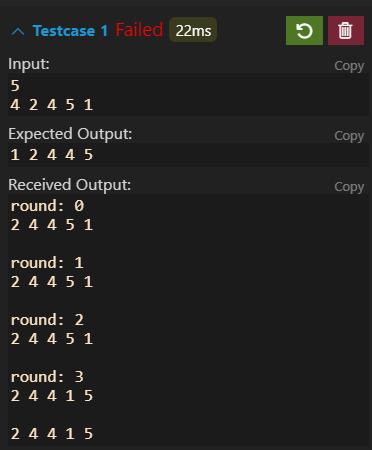
发现第一轮就错了,5根本没有被移到最后面。那就想,5能移到后面跟什么有关,就可以定位到交换部分的代码了。然后再仔细阅读代码,回想算法,找到bug。
// 正确代码
#include <stdio.h>
#define N 100010
int a[N];
int main()
{
int n;
scanf("%d", &n);
for (int i = 0; i < n; i ++ ) scanf("%d", &a[i]);
for (int i = 0; i < n - 1; i ++ )
{
for (int j = 0; j < n - i - 1; j ++ )
{
if (a[j] > a[j + 1])
{
int t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
}
}
}
for (int i = 0; i < n; i ++ ) printf("%d ", a[i]);
return 0;
}
第三步 造数据
当我们通过了样例,但提交上去后是部分正确或者完全错误时,我们可以考虑造数据来寻找程序的漏洞。
小数据
什么是小数据?
个人认为小数据就是能够完整跟踪程序运行过程,查看中间变量,手算或脑内模拟的数据。
小数据的优点
-
易于调试。
-
易于设计。
由于数据量小,我们往往可以手工设计质量更高的数据,同时对于数据本身也有直观的了解。与此同时,很多的题都会有所谓的“变态数据”,这和极限数据有着一些不同,它虽然数据量不大,但是剑走偏锋,比如某矩阵题给你一个全都是 1 的矩阵之类的。这种狡猾的数据在评测的时候往往并不罕见,由于这样那样的原因,我们就栽了跟头。为了使得自己的程序更加强壮,我们需要预先测试自己的程序是否能够通过这样的数据。这种变态数据只能够由我们手工设计,因此一般都是小数据。
-
覆盖面广
对于很多题目而言,测试数据理论上存在无穷多组; 但是如果有 n<5 并且所有数都小于 10 的限制,那么数据的个数就变得有限了,不妨设是 1000 组。我们可以通过写一个程序,直接把这 1000 组小数据全部都制作出来,然后逐个儿测试。 虽然这些数据的数据量小,但是由于它们把小数据的所有可能的情况都包括在其中了,因此你的程序的大部分问题都能够在这 1000 组数据中有所体现。同时,因为是小数据,程序可以在很短的时间内运行出解,例如是 0.05 秒,这样, 1000 组数据,也不过只要 50 秒,完全可以接受。但是要注意,生成所有数据的同时,我们还要写一个效率差,确保正确的程序来验证结果的正确性。因此这种想法至少需要 2 个程序。
极限数据
什么是极限数据?
在说明极限数据之前,我们要先了解一下什么是题目的时间限制和空间限制。
以洛谷的这道查找题为例。【模板】查找
输入 \(n\) 个不超过 \(10^9\) 的单调不减的(就是后面的数字不小于前面的数字)非负整数 \(a_1,a_2,\dots,a_{n}\),然后进行 \(m\) 次询问。对于每次询问,给出一个整数 \(q\),要求输出这个数字在序列中第一次出现的编号,如果没有找到的话输出 \(-1\) 。
11 3
1 3 3 3 5 7 9 11 13 15 15
1 3 6
1 2 -1
时空限制:
数据保证,\(1 \leq n \leq 10^6\),\(0 \leq a_i,q \leq 10^9\),\(1 \leq m \leq 10^5\)
解释:
-
时间限制:c/c++的代码,评测机1s能算1e8次。可以理解为,我们的程序基本操作重复执行的次数不能超过1e8这个数量级。注意,这里的解释不是很严谨,是为了方便本次讲解,实际上程序的运算次数是由一个名为时间复杂度的指标衡量的,是算法的时间复杂度在题目的数据范围内不能超过1e8这个量级。
假如我们用遍历数组来做这道题,代码如下:
#include <stdio.h> #define N 1000010 int a[N]; int main() { int n, m; scanf("%d%d", &n, &m); for (int i = 1; i <= n; i ++ ) scanf("%d", &a[i]); int q; for (int i = 0; i < m; i ++ ) { scanf("%d", &q); int found = 0; for (int j = 1; j <= n; j ++ ) { if (a[j] == q) { printf("%d ", j); found = 1; break; } } if (found == 0) printf("-1 "); } return 0; }评测结果如下(开了O2优化)。可以看到,这份代码在四个测试点上超过了时间的限制,也就是运行的时间超过了1s。
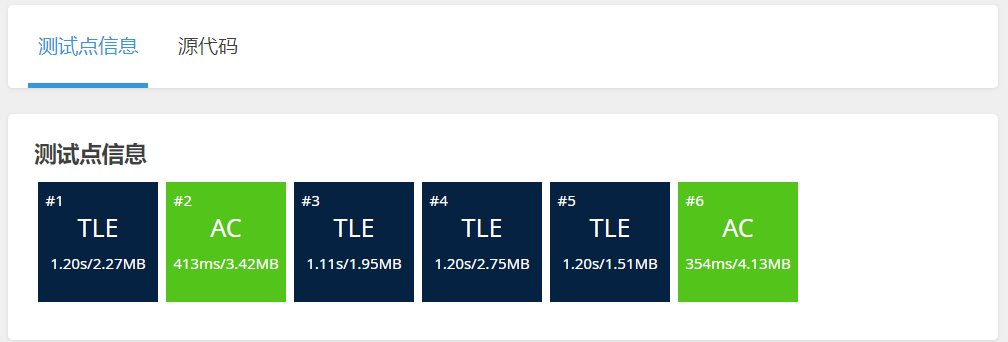
为什么超时了呢?我们可以这样看:
对于每个询问,我们都遍历了一次数组,数组长度是n,则遍历一次for循环内的语句就执行了n次。一共有m个询问,则for循环内的语句最多会执行
n*m次。题目给的数据范围中,n最大是1e6,m最大是1e5,n*m显然超过了1e8的数量级。也就是说,这份代码超出了题目的时间限制,不能通过所有的测试点。 -
空间限制:一个程序的运行会占用内存,内存的消耗一方面是我们定义变量开辟的空间,另一方面是程序运行需要的栈空间。栈空间主要是函数递归会消耗,这里先不做说明,来看变量占用的空间。在这道题里,我们定义了一个长度为1e6的int类型的数组。我们来算一下这个数组占用了多少内存。一个int是4字节,1e6个int就消耗了4e6个字节。题目的空间限制是125MB,大概是
125*10^6=1.25e7个字节。所以我们这里没有超过空间限制。但是,加入题目中的数据范围到1e7,那开的数组所消耗的空间就会超过题目的内存限制了。
Tips:有的时候其实空间没有超限,但程序还是MLE了,或者在本地跑不起来,一种解决办法是把需要空间较大的变量,比如数组,定义为全局变量。
了解了题目的时间限制和空间限制后,我们就可以给出极限数据的定义了:
极限数据就是会达到题目的时间限制或空间限制或同时达到两个限制的数据。
极限数据的作用
- 程序是否会超时
- 程序是否会越界
- 内存超限
- 溢出
构造的方法和例子
构造小数据
我们大部分构造的数据都是小数据,因为它方便调试。
-
造数据是选择不同类型的,不是改小或者改大,改的是模型或者模式。
比如查找这道题,样例给的是测试数据如下:
11 3 1 3 3 3 5 7 9 11 13 15 15 1 3 61 2 -1分析这三个数的模式:
1是找得到且只有一个3是找得到且有多个6是找不到
那如果我们改成1,3,8,等于没改,模式是一样的。
我们可以改成4,6,8,这是三个都找不到的测试数据,也可以改成3个都找得到,2个找得到且有多个,等等。
-
多考虑边界情况和特殊数据。
如果我们只是对着样例去想做法,那很容易忽略边界情况。比如这道题里,可能给的n个数都相等、或者没有重复出现的数,或者只有一个数等等,这些都是特殊的数据。对于我们的算法,这些数据当然统统都能通过,就是可能会超时,但对于其他的一些做法,可能它们就挂在这些特殊数据上。
构造极限数据
其实算法是否会超出时间和空间限制,我们是可以分析出来的。但当你拿不准时,你可以造一些极限数据去测试。
比如这道题,如果我输入一个长度为1e5的序列,询问1e6次,就会发现程序在本地很久才能给出结果,就说明我们的做法不够优秀,需要优化了。
认识oj错误类型
WA
答案错误(Wrong Answer,WA)
TLE
超时(Time Limit Exceeded,TLE)
MLE
内存超限(Memory Limit Exceeded,MLE)
RE
运行时错误(Runtime Error,RE)
段错误
段错误(Segmentation fault)
PE
格式错误(Presentation Error,PE)
CE
编译错误(Compile Error,CE)
debug的技巧
技巧1:assert
技巧2:宏定义
技巧3:vs code的调试功能
技巧4:二分、注释代码
技巧5:输入输出重定向、文件对比
技巧5进阶:对拍
技巧6:小黄鸭调试法
debug案例
案例1:scanf
案例2:for循环
案例3:两个变量互相更新
案例4:除法
案例5:中间值溢出
案例6:类型转换
案例7:初始化和重置
结语
debug值得花时间吗?有什么意义?
不要用手上的勤奋替代大脑的思考
请人帮忙debug前最好格式化代码
附录
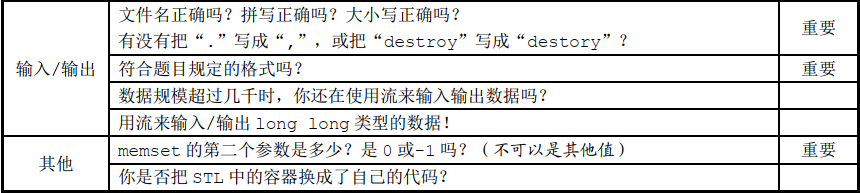
代码审查表


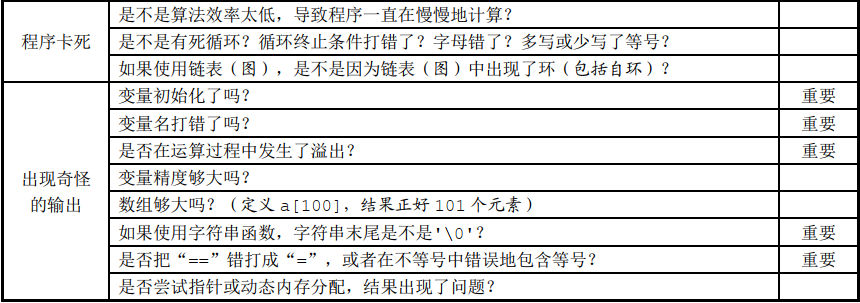
故障检查表

例题(二分查找)
题目描述
输入 \(n\) 个不超过 \(10^9\) 的单调不减的(就是后面的数字不小于前面的数字)非负整数 \(a_1,a_2,\dots,a_{n}\),然后进行 \(m\) 次询问。对于每次询问,给出一个整数 \(q\),要求输出这个数字在序列中第一次出现的编号,如果没有找到的话输出 \(-1\) 。
输入格式
第一行 \(2\) 个整数 \(n\) 和 \(m\),表示数字个数和询问次数。
第二行 \(n\) 个整数,表示这些待查询的数字。
第三行 \(m\) 个整数,表示询问这些数字的编号,从 \(1\) 开始编号。
输出格式
输出一行,\(m\) 个整数,以空格隔开,表示答案。
样例 #1
样例输入 #1
11 3
1 3 3 3 5 7 9 11 13 15 15
1 3 6
样例输出 #1
1 2 -1
提示
数据保证,\(1 \leq n \leq 10^6\),\(0 \leq a_i,q \leq 10^9\),\(1 \leq m \leq 10^5\)
本题输入输出量较大,请使用较快的 IO 方式。