说明
上班摸鱼的时候无意看到一篇文章:Solving Sudoku with Poetry's dependency resolver,利用 Python 的依赖解析器来做数独,想起当年自己用 MatLab 也写过一个做数独的程序,但是需要手动填写数独题目,而且印象里也是非常暴力的算法。
因此想要使用更合理的算法来实现解数独,同时尝试使用 OpenCV 和 OCR 实现数独题目的自动编码。
涉及的内容:Python,回溯算法,OpenCV,tesseract
回溯算法解数独
因为这块内容互联网上俯拾皆是,实现过程中也基本是 CV+Tab 编程(Copilot 大法好!),所以具体不细说了。LeetCode 上也有专门一道题目是解数独的(解数独),想了解回溯算法的可以参考。
直接贴代码了:
def is_valid(sudoku, i, j, num):
for x in range(9):
if sudoku[x][j] == num:
return False
if sudoku[i][x] == num:
return False
for x in range(3):
for y in range(3):
if sudoku[i//3*3+x][j//3*3+y] == num:
return False
return True
def backtrack(sudoku, i, j):
if sudoku[i][j] != 0:
if i == 8 and j == 8:
return True
elif j == 8:
return backtrack(sudoku, i+1, 0)
else:
return backtrack(sudoku, i, j+1)
for num in range(1, 10):
if is_valid(sudoku, i, j, num):
sudoku[i][j] = num
if i == 8 and j == 8:
return True
elif j == 8:
if backtrack(sudoku, i+1, 0):
return True
else:
if backtrack(sudoku, i, j+1):
return True
sudoku[i][j] = 0
return False
OpenCV + OCR 读取数独题目
数独截图来源于:数独在线
原始图片示例如下:
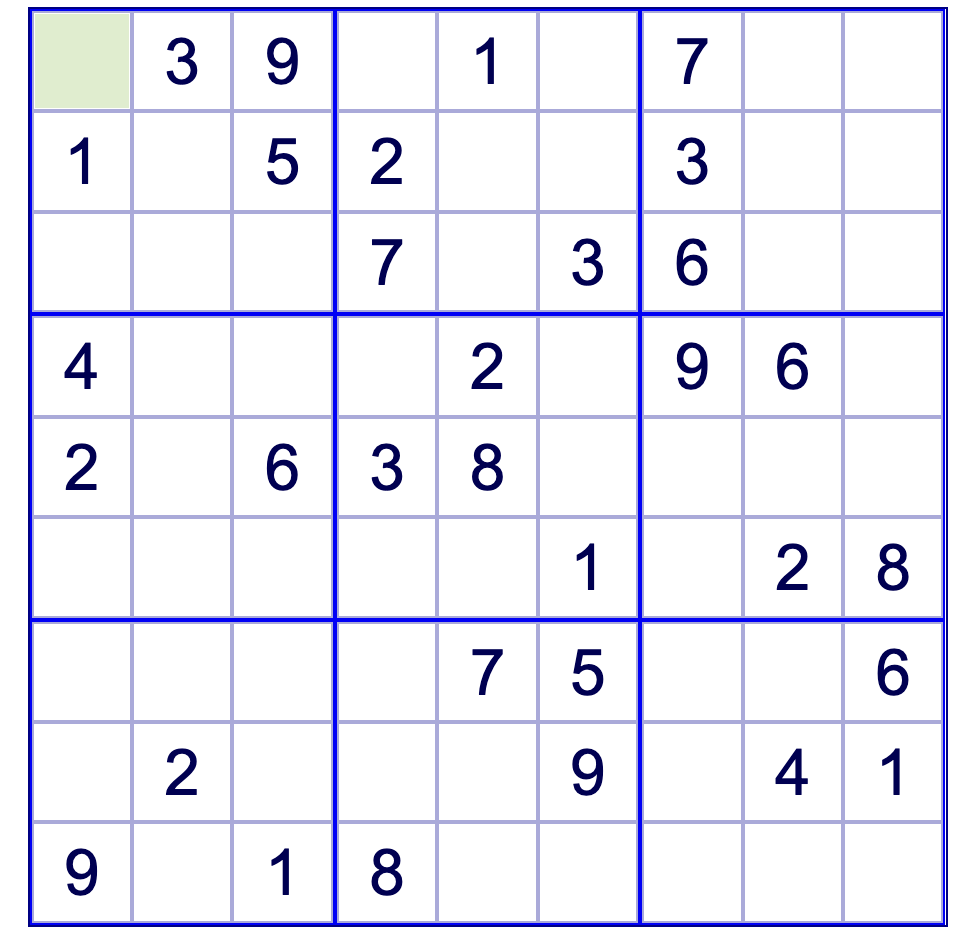
先描述下总体思路:通过图片的初步处理,检测出水平线和垂直线及其交点。随后通过交点的坐标将数独的各个单元格分割为单独的图片。使用 OCR 方式将各个单元格的内容识别出来,最终将原始的数独题(图片)转化为一个二维数组(通过 CSV 保存)。
首先读取图片:
# 读取图片
src = "/Users/cbc/Study/Python/sudoku-csv/Snipaste_2023-08-07_10-36-12.png"
raw = cv2.imread(src, cv2.IMREAD_COLOR)
图片进行初步处理:
# 转换为灰度图
gray = cv2.cvtColor(raw, cv2.COLOR_BGR2GRAY)
# 二值化
binary = cv2.adaptiveThreshold(
~gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 35, -5
)
这里转了一次灰度图,理论上可以在读取图片的时候
imread的第二个参数用IMREAD_GRAYSCALE直接以灰度读取。没直接试过。
二值化之后的结果图:

这里吐槽一下,尽量找一些边框、数字和背景反差比较大并且“亮度”比较一致的,否则二值化过程中调参会比较麻烦,但理论上大差不差。
通过将 kernel 设为水平方向/垂直方向的长条矩形进行开操作(先腐蚀、再膨胀)实现水平线和垂直线的检测/提取
rows, cols = binary.shape
scale = 30
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (cols // scale, 1))
eroded = cv2.erode(binary, kernel, iterations=2)
dilated_col = cv2.dilate(eroded, kernel, iterations=3)
scale = 30
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, rows // scale))
eroded = cv2.erode(binary, kernel, iterations=2)
dilated_row = cv2.dilate(eroded, kernel, iterations=3)
效果如下:


简单解释一下,部分代码 C&V 来的可能理解不准确:
cols // scale以及rows // scale我理解下来没有什么特殊意义,写一个定值应该也行(没试过),只要保证 kernel 是要检测的形状即可(这里是水平&垂直形状的长条)。我调整过几次scale以确保能够将数字中的一些水平线和垂直线过滤掉。
腐蚀和膨胀的迭代次数为了最终效果也调整过几次。
将水平线与垂直线进行按位与操作,获取交点,然后进行一次腐蚀操作,让“交点”更小,方便后一步获取交点横纵坐标。
# 对检测到的水平线和垂直线进行按位与操作
bitwise_and = cv2.bitwise_and(dilated_col, dilated_row)
# 对二值化图像进行腐蚀操作,减少交点范围
kernel = np.ones((3, 3), dtype=np.uint8)
eroded_points = cv2.erode(bitwise_and, kernel, 1)
cv2.imwrite("./cell_pic/eroded_points.png", eroded_points)
效果如下:

获取交点坐标值:
# 获取交点横、纵坐标
ys, xs = np.where(eroded_points > 0)
x_list = []
y_list = []
# 将临近的横、纵坐标合并(差值在10以内)
xs = np.sort(xs)
x_list.append(xs[0])
for i in range(1, len(xs)):
if xs[i] - xs[i - 1] > 10:
x_list.append(xs[i])
ys = np.sort(ys)
y_list.append(ys[0])
for i in range(1, len(ys)):
if ys[i] - ys[i - 1] > 10:
y_list.append(ys[i])
这里横/纵坐标做了简单的聚合,确保一个“点”代表一个坐标
根据坐标进行切割,并调用 pytesseract 进行 OCR 识别:
# 根据横纵坐标逐个切割单元格,并将单元格内内容填入对应二维数组中
board = [[0 for j in range(9)] for i in range(9)]
for i in range(len(y_list) - 1):
for j in range(len(x_list) - 1):
cell = binary[y_list[i] + 1: y_list[i + 1],
x_list[j] + 1: x_list[j + 1]]
# 周围裁剪
cell = cell[20:-20, 20:-20]
# 周围填充
cell = cv2.copyMakeBorder(cell, 100, 100, 100, 100,
cv2.BORDER_CONSTANT, value=(0, 0, 0))
cell = cv2.threshold(
cell, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
cv2.imwrite("./cell_pic/cell" + str(i+1) +
"," + str(j+1) + ".png", cell)
number = pytesseract.image_to_string(
cell,
config='--psm 6 -c tessedit_char_whitelist=123456789')
if number != "":
# 移除换行符
number = number.replace("\n", "")
board[i][j] = number
裁剪效果如下:

(↑这里有张图)

简单解释一下:
按照坐标裁剪后还在周围裁剪了一次是因为初次裁剪周围还会有留有一些边框,为了排除这部分的影响又裁减了一次。
裁剪完又填充了一次理论上是不必要的,但是后面 OCR 实测下来中间的字符的大小合适识别成功率和准确性才能保证,所以简单做了一下填充。做了一次反色也是为了保证准确性,看网上部分资料说白底黑字会好一些,理论上不做也可以,没试过。
使用 OCR 配置了一些参数:
--psm 6:(机翻)将 Tesseract 设置为仅运行布局分析的子集并假定某种形式的图像,6=假定为单一的统一文本块。
一开始采用了“10 = Treat the image as a single character.”,结果发现效果并不好。
-c tessedit_char_whitelist=123456789:配置识别结果白名单。
写入 CSV 文件:
# 写入csv文件
with open("./sudoku-board.csv", "w") as f:
for i in range(9):
for j in range(9):
f.write(str(board[i][j]))
if j != 8:
f.write(",")
f.write("\n")
最终结果:
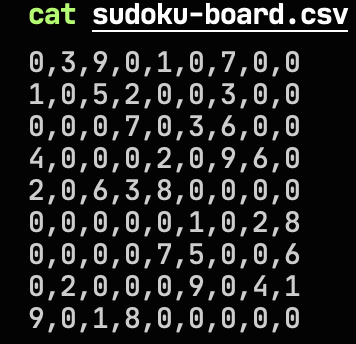
对比原始图片: