Image As Set Of Points
Abstract
提取图像特征的几种方法:
- ConvNets:将图像视为矩形中有组织的像素,并通过局部区域的卷积运算提取特征;
- Vision Transformers(ViTs):将图像视为一系列补丁,并通过全局范围内的注意力机制提取特征。
- Context Clusters(CoCs):上下文聚类将图像视为一组无组织的点,并通过简化的聚类算法提取特征。具体来说,每个点包括原始特征(如颜色)和位置信息(如坐标),并采用简化的聚类算法分层分组和提取深层特征
introduction
目前特征提取的范式有:基于卷积的,基于self-attention的,卷积和注意力相结合的,基于MLP的,基于图的.
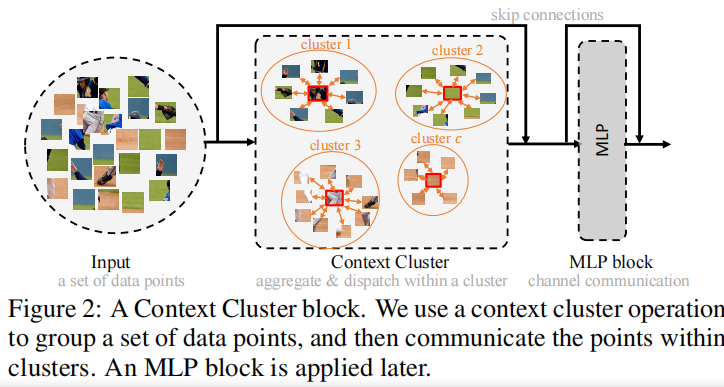
在这篇文章中, 作者将图像视为一组数据点并将所有点分组为簇(cluster,聚类操作)。在每个集群中,作者将点聚合到一个中心,然后自适应地将中心点分配给所有点。这个操作被称之为上下文聚类(context cluster).

图一表示用于图像分隔的context cluster. 作者将图像视为一组点,并且抽取了\(C\)个中心以进行点聚类。点要素被聚合,然后在集群内进行调度。对于中心点\(C_{i}\)来说,首先将这个cluster内的所有点\(\left\{x_{i}^{0},x_{i}^{1},\dots,x_{i}^{n}\right\}\)聚合。
然后将聚合结果动态分发到集群中的所有点
method
在本节中,作者首先描述 Context Clusters 工作流程。然后彻底解释了所提出的用于特征提取的上下文聚类操作(如图 2 所示)。
之后,作者设置了 Context Cluster 架构。
Context Clusters Pipeline
From Image to Set of Points
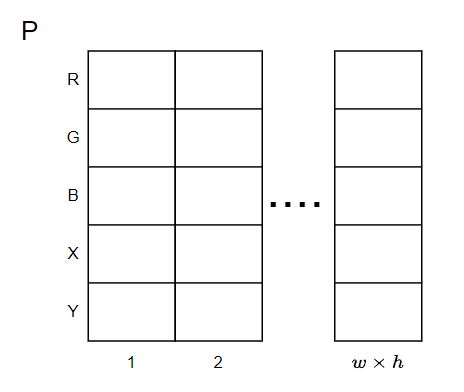
对于一个输入图像\(I\in R^{3\times w\times h}\),为每个像素\(I_{i,j}\)生成一个坐标,表示为\([\frac{i}{w}-0.5,\frac{i}{h}-0.5 ]\).
然后将图像表示为点的集合\(P\in R^{5\times n}\),其中\(n=w \times h\).
Feature Extraction with Image Set Points
使用context cluster blocks提取深层特征,结构如下图所示:
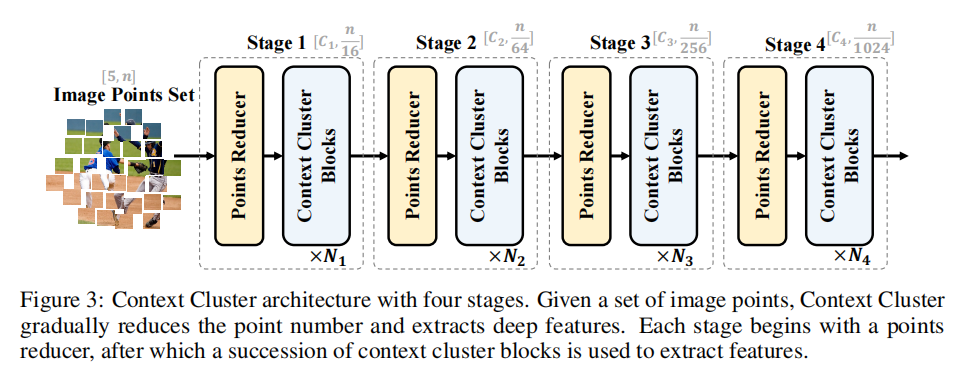
给定一组点\(P\in R^{5\times n}\), 作者首先减少点数以提高计算效率,然后应用一系列context cluster block来提取特征。
为了减少点数,我们在空间中均匀地选择一些锚点,最近的 k 个点通过线性投影连接和融合。
请注意,如果所有点都按顺序排列并且 k 设置正确(即 4 和 9),则可以通过卷积运算来实现这种减少,就像在 ViT 中一样(Dosovitskiy 等人,2020)。
class PointRecuder(nn.Module):
"""
Point Reducer is implemented by a layer of conv since it
is mathmatically equal.
Input: tensor in shape [B, in_chans, H, W]
Output: tensor in shape [B, embed_dim, H/stride, W/stride]
"""
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=None):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
return x
Context Cluster Operation
在本小节中,作者介绍了工作中的关键贡献,context cluster操作。
整体上,首先将特征点分组为簇;然后,每个集群中的特征点将被聚合,然后分派回来,如图 1 所示。
Context Clustering
给定一组点\(P\in R^{N\times d}\), 作者根据相似性将所有点分为几组,每个点单独分配给一个集群。
首先将\(P\)线性投影到\(P_{s}\)以进行相似度计算。遵循传统的 SuperPixel 方法 SLIC (Achanta et al., 2012),我们在空间中均匀地提出 c 个中心,中心特征是通过对其k个最近点求平均来计算的。
然后计算\(P_{s}\)和结果中心点集之间的成对余弦相似度矩阵\(S\in R^{c\times n}\)
之后,作者将每个点分配到最相似的中心,从而产生 c 个cluster。值得注意的是,每个集群可能有不同数量的点。在极端情况下,一些集群可能有零点,在这种情况下它们是冗余的.
Feature Aggregating
作者根据与中心点的相似性动态聚合集群中的所有点。
假设一个cluster含m个点(P中的一个子集),m个点与中心的相似度为\(s∈R^{m}\)(S中的一个子集),作者将这些点映射到一个值空间得到\(P_{v}\in R^{m\times d'}\) ,其中\(d'\)是值维度。
作者还像聚类中心一样在价值空间中提出了一个中心\(v_{c}\).
聚合特征\(g\in R^{d'}\) 由下式给出:
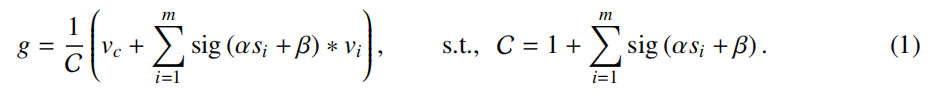
这里 α 和 β 是可学习的标量,用于缩放和移动相似度,而 sig (·) 是一个 sigmoid 函数,用于将相似度重新缩放到 (0, 1)。 \(v_{i}\) 表示 \(P_{v}\) 中的第 i 个点。根据经验,这种策略会比直接应用原始相似性取得更好的结果,因为不涉及负值。
不考虑 Softmax,因为这些点彼此不矛盾。我们将价值中心 \(v_{c}\) 纳入等式用于数值稳定性以及进一步强调局部性。为了控制幅度,聚合的特征被因子 C 归一化。
Feature Dispatching
然后根据相似性将聚合的特征 g 自适应地分配到集群中的每个点。通过这样做,点可以相互通信并共享集群中所有点的特征,如图 1 所示。
对于每个点\(p_{i}\):
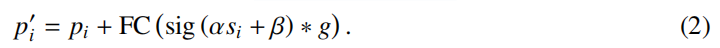
这里按照相同的程序来处理相似性,并应用一个全连接 (FC) 层来匹配特征维度(从值空间维度 d' 到原始维度 d).
Architecture Initialization
虽然 Context Cluster 从根本上不同于卷积和注意力,但来自 ConvNets 和 ViTs 的设计哲学,例如层次表示和元 Transformer 架构(Yu 等人,2022c),仍然适用于 Context Cluster。为了与其他网络保持一致并使我们的方法与大多数检测和分割算法兼容,我们在每个阶段逐步将点数减少 16、4、4 和 4 倍。我们在第一阶段为选定的锚点考虑 16 个最近的邻居,在其余阶段我们选择他们的 9 个最近的邻居。
一个潜在的问题是计算效率。假设我们有 n 个 d 维点和 c 个簇,计算特征相似度的时间复杂度为 O(ncd),这在输入图像分辨率很高(例如 224 × 224)时是不可接受的。
为了避免这个问题,我们通过将点分成几个局部区域来引入区域划分,如 Swin Transformer (Liu et al., 2021b),并在局部计算相似度。
结果,当局部区域的数量设置为 r 时,我们明显将时间复杂度降低了 r 倍.
Discussion
Fixed or Dynamic centers for clusters?
传统的聚类算法和 SuperPixel 技术都迭代更新中心直到收敛。然而,当将聚类用作每个构建块中的关键组件时,这将导致过高的计算成本。推理时间将呈指数增长。在 Context Cluster 中,我们将固定中心视为推理效率的替代方案,这可以被视为准确性和速度之间的折衷。
Overlap or non-overlap clustering?
我们将点仅分配给特定的中心,这与以前的点云分析设计理念不同。我们有意坚持传统的聚类方法(非重叠聚类),因为我们想证明简单和传统的算法可以作为通用骨干。尽管它可能会产生更高的性能,但重叠聚类对我们的方法来说并不是必不可少的,并且可能会导致额外的计算负担。