要求:在中国气象网(http://www.weather.com.cn)给定城市集合的7日天气预报,并保存在数据库。
Gitee:https://gitee.com/HJ_orange/crawl_project/tree/master/实践作业2
代码如下
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
import requests
import re
import sqlite3
# 创建一个 SQLite 数据库连接
conn = sqlite3.connect('weathers.db')
c = conn.cursor()
# 创建一个新表,如果表已经存在则忽略
c.execute('''CREATE TABLE IF NOT EXISTS weathers
(num TEXT, address TEXT, date TEXT, weather TEXT, temp TEXT)''')
url = "http://www.weather.com.cn/weather/101230101.shtml"
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
num = 0
for li in lis:
try:
num = num+1
address = "福州"
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print("{:<5} {:<5} {:<10} {:<10} {:<10}".format(num, address, date, weather, temp))
c.execute("INSERT INTO weathers VALUES (?, ?, ?, ?, ?)", (num, address, date, weather, temp))
except Exception as err:
print(err)
conn.commit()
except Exception as err:
print(err)
finally:
conn.close()
运行结果
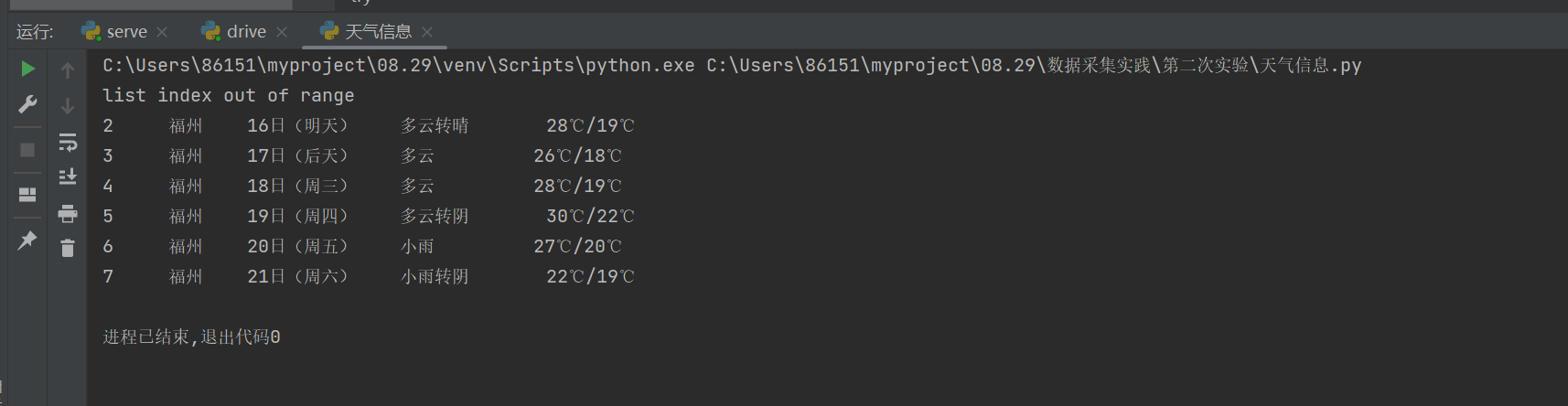
心得体会
这是比较简单的复现,总体来说难度不大
Task2
要求:用requests和自选提取信息方法定向爬取股票相关信息,并存储在数据库中。
候选网站:东方财富网:https://www.eastmoney.com/新浪股票:http://finance.sina.com.cn/stock/
Gitee:https://gitee.com/HJ_orange/crawl_project/tree/master/实践作业2
代码如下
import json
import re
import requests
import pandas as pd
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
def get_data(page):
url = "http://44.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406854618710877052_1696660618066&pn=" + str(page) + "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14&_=1696660618067"
response = requests.get(url)
content = response.text
start = content.find('(')
end = content.rfind(')')
data_str = content[start+1:end]
data = json.loads(data_str)
data = data['data']['diff']
name = ['f12','f14','f2','f3','f4','f5','f6','f7']
count = 0
list_data = []
for i in range(len(data)):
list_item = []
list_item.append(i)
for j in name:
list_item.append(data[i][j])
count += 1
list_data.append(list_item)
return list_data
count = 1
data = []
keypage = input("请输入要搜索的特定页面(用空格分隔):")
for i in range(1,keypage+1):
k = getdata(i)
# print(k)
for i in k:
data.append(i)
# print(data,len(data))
df = pd.DataFrame(data=data,columns=['序号','代码','名称','最新价','涨跌幅','跌涨额','成交量','成交额','涨幅',"最高","最低", "今开","昨收"])
print(df)
运行结果
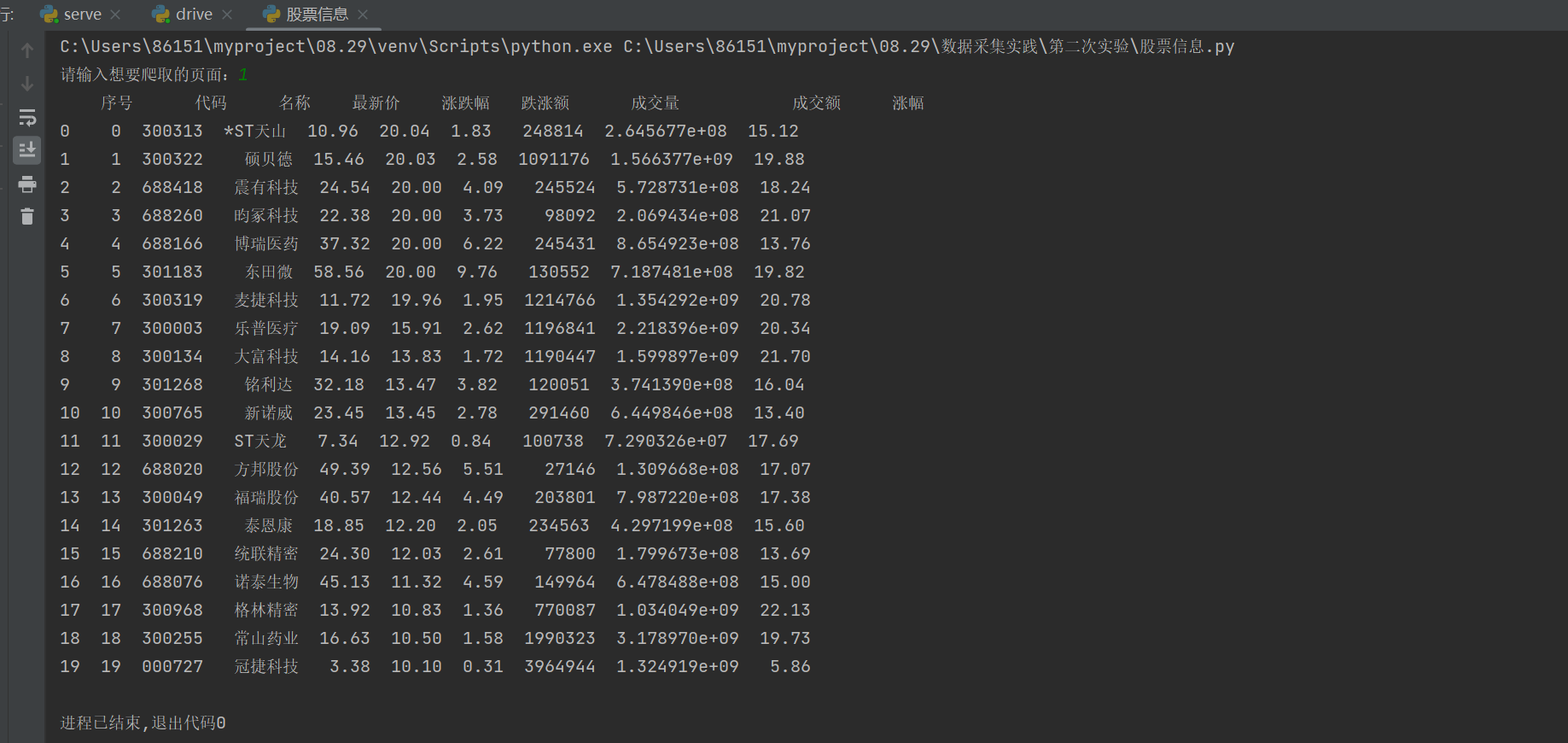
心得体会
相比前面的方法 不一样的点在于通过js文件获取到所要爬取数据的url,了解了更多js文件提取信息方面的方法。
Task3
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
Gitee:https://gitee.com/HJ_orange/crawl_project/tree/master/实践作业2
代码如下:
import requests
import bs4
import urllib.request
from bs4 import BeautifulSoup
def ThriveList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
a = tr('a')
tds = tr('td')
ulist.append([tds[0].text.strip(), a[0].string.strip(), tds[2].text.strip(),
tds[3].text.strip(), tds[4].text.strip()])
def GetHTML(url):
res = requests.get(url)
res.raise_for_status()
res.encoding = res.apparent_encoding
return res.text
req = urllib.request.Request(url)
response = urllib.request.urlopen(req)
data = response.read().decode()
return data
def PrintList(ulist1, num):
tplt = "{0:^10}\t{1:^10}\t{2:^10}\t{3:^12}\t{4:^10}"
print(tplt.format("排名", "学校", "\t\t省份", "类型", "总分"))
for i in range(num):
u = ulist1[i]
print(tplt.format(u[0], u[1], u[2], u[3], u[4]))
if __name__ == '__main__':
uinfo = []
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
html = GetHTML(url)
ThriveList(uinfo, html)
PrintList(uinfo, 10)
抓包过程

心得体会
在这个实验中更加深刻的体会到正则表达式匹配在一些特殊情况下的优越之处。