Ansor:Generating High-Performance Tensor Program for Deep Learning
Abstract
高性能的张量程序对于保证深度神经网络的高效执行十分关键,但是在不同硬件平台上获取高性能的张量程序并不容易。近年的研究中,深度学习系统依赖硬件供应商提供的算子库,或者多种搜索策略来获得高性能的张量程序。这些方法可能需要较多的工程上的努力来开发平台专用的优化代码,或者由于搜索空间的限制和低效的搜索策略而达不到高性能的要求。
我们提出了Ansor,一个为深度学习应用的张量程序生成框架。与现有的搜索策略相比,Ansor通过对搜索空间的分层表示中采样程序,探索更多的优化组合。使用进化搜索和可学习的代价模型对采样程序进行调优,找到最好的程序。Ansor能够找到目前最先进的搜索方法之外的高性能程序。除此之外,Ansor使用一个任务调度器同时优化深度神经网络的多个子图。我们展示了在Intel CPU,ARM CPU和NVIDIA GPU上Ansor与最先进算法的提升,分别有3.8,2.6和1.7的相对加速。
1 Introduction
深度神经网络(DNN)的低延迟执行在自动驾驶、增强现实、语言翻译和其他的AI应用中发挥至关重要的作用。DNNs可以被表示成有向无环计算图(DAG),其中节点表示算子(例如convolution,matrix multiplication),边表示算子之间的依赖。现有的深度学习框架(Tensorflow,PyTorch,MXNet)将DNNs中的算子映射到硬件供应商提供的算子库上(cuDNN,MKL-DNN)来获得高性能。但是这些算子库需要巨大的工程量对每个硬件平台和算子进行调优。为每个目标加速器生成高效算子的巨大工程量限制了新算子和特定加速器的开发和创新。
由于DNNs性能的重要性,研究人员和行业从业者开始转向基于编译器搜索来自动生成张量程序(low-level张量算子实现)。给定一个算子或包含多个算子的计算图,用户通过高级声明式语言定义计算(第2章),编译器自动根据不同硬件平台生成程序。
为了找到高性能张量程序,需要在一个能覆盖有效张量程序优化的足够大搜索空间中进行搜索的方法,但是已有方法不能找到所有的优化组合,因为需要依赖预定义的手工编写的模板(TVM,FlexTensor)或者通过评估未完全的程序进行激进的修剪(Halide auto-scheduler),导致他们不能完全覆盖搜索空间(第2章),这些工作用于搜索空间构建的规则十分有限。
在本文中,我们采用了全新的搜索策略来构建高性能张量程序,可以自动地构建包含全面优化的巨大搜索空间,空间中每个张量程序都有被选择的可能性。因此能够发现已有方法可能错过的高性能程序。
这个目标有多个挑战
- 给定计算定义,需要自动构建搜索空间,覆盖尽可能多的张量程序
- 需要高效的搜索,不通过比较未完成的程序。搜索空间可能比已有模板能覆盖的大多个数量级
- 当优化拥有多个子图的DNNs时,应当识别并优化对端到端性能最关键的那些子图
为此,我们设计并实现了Ansor,一个自动张量程序生成框架。Ansor实现了分层表示来覆盖巨大搜索空间,这种表示将high-level结构和low-level细节解耦,能够灵活地枚举high-level的结构,有效采样low-level的细节。给定计算定义,这个搜索空间将自动构建,然后Ansor将从搜索空间中选取完成的程序,使用进化搜索和一个可学习代价模型进行调优。为了优化有多个子图的DNNs的性能,Ansor动态考虑DNNs中那些最有可能提升端到端性能的子图。
我们将Ansor和标准的深度学习基准、手工库、最先进的基于搜索的框架进行对比评估。实验结果显示Ansor在Intel CPU,ARM CPU和NVIDIA GPU上分别有3.8,2.6和1.7的相对加速。对于大多数计算定义,Ansor在现有的基于搜索的方法的空间之外找到了最好的程序。相比于现有搜索方法,Ansor的搜索更加高效,即使在更大的搜索空间中也能更短时间生成张量程序。Ansor能够在时间上比最先进的框架少几个数量级。Ansor能够自动扩展新算子,只需要提供算子的数学定义,而不需要手工模板。
总的来说,本文作出了以下贡献
- 提供了一种对计算图构建张量程序的巨大分层搜索空间的方法
- 一种使用可学习的代价模型的进化策略对张量程序进行调优
- 一种基于梯度下降的优先选择DNNs中对端到端性能影响大的子图
- 一种实现,对Ansor系统全面的评估表明上述技术在多个DNNs和硬件平台上优于最先进的系统
2 Background
深度学习生态系统正在拥抱快速发展的硬件平台多样性,包括CPUs、GPUs、FPGAs和ASICs,为了在这些平台上部署DNNs模型,需要为DNNs使用的算子提供高性能程序。所需的算子集包含标准算子(matmul、conv2d)和机器学习研究人员发明的新算子(capsule conv2d,dilated conv2d)。
为了以高效的方式在广泛的硬件平台上提供这些算子的可移植性,多种编译器技术已经出现(TVM,Halide,Tensor Comprehensions)。用户通过高级声明性语言以类似数学表达式的形式定义计算,编译器根据定义生成优化的张量程序。下图展示了使用TVM张量表达式语言定义的矩阵乘法,用户主要定义张量的形状,以及如何计算输出张量中每个元素。

但是,从高级定义自动生成高性能的张量程序是十分困难的。根据目标平台的体系结构,编译器需要在包含组合优化选择(tile structure,tile size,vectorization,parallelization)的极其大而复杂的空间中搜索,寻找高性能的程序需要搜索策略能全面地覆盖空间,并且高效地搜索。我们在这一章节介绍两种较新的高效的方法,其他相关的工作在第8章。
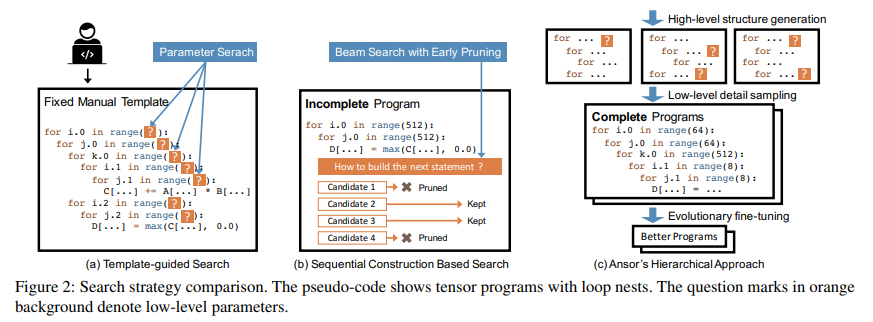
根据模板的搜索
在根据模板的搜索中,搜索空间是通过手工编写的模板确定的。例如图2a展示的,编译器(例如TVM)需要用户手写一个计算定义的模板。模板定义了张量程序包含可调优的参数(例如size和unrolling factor)的结构。编译器需要根据给定的输入张量的形状搜索到特定硬件的最优配置。这种方法能在普通的深度学习算子上取得较好的性能,但是部署模板需要工程量,例如TVM已经拥有超过15K行的模板代码数。新算子和新硬件的出现会导致进一步增长。另外,创建高质量的模板需要对张量算子和硬件有一定的经验。需要大量搜索来形成这些模板,除去设计模板的复杂度,手写的模板只能覆盖有限的搜索空间,因为手动穷举每种优化选择每种算子是不现实的。这种方法需要为每个算子定义一个模板,FlexTensor提出了一种通用的模板来覆盖乘法算子,但是这个模板仍然只是用于单个算子的粒度,无法包含多个算子调用的优化(例如算子融合),有多个算子的计算图优化应当包含这些算子符合的不同方案来形成搜索空间。基于模板的搜索方法不能达到这一点,因为不能拆分模板并重新组合。
基于连续构建的搜索
这种方法通过解耦程序为一系列固定的决策来形成搜索空间。编译器使用beam search等算法来搜索好的决策(例如Halide auto-scheduler),通过这种方法,编译器通过顺序展开计算图中的节点构建张量程序。对于每个节点,编译器将决策如何进行转换为low-level张量程序(例如决策计算位置,存储位置,size等)。当所有的节点都被展开,完整的张量程序就构建好了。这种方法使用展开的规则应用于每个节点,所以能够自动地进行搜索。由于每种可能的选择是很多的,为了让顺序的过程可接受,这种方法保留top-k种候选的程序,在每次决策之后。编译器评估并比较候选张量程序的性能,使用可学习的代价模型选出top-k,其他的被丢弃。搜索过程中,候选的程序是不完整的,因为计算图中只有一部分被展开,只完成了一些决定,图2b展示了这一点。
然而,评估不完整程序的性能是十分困难的
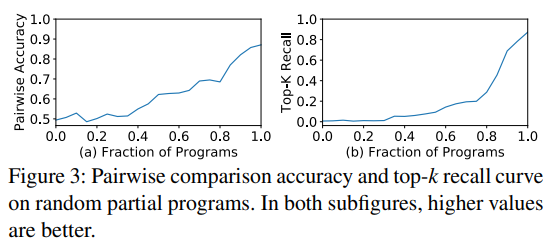
- 代价模型无法精确地预测不完整程序的性能,使用完成程序训练的代价模型只能用来预测完整的程序,因为需要编译程序然后测量运行时间,得到标签进行训练。直接使用这种模型比较不完整程序可能导致精度的降低。作为测试,我们在20000个随机的不完整程序上进行训练(第5.2章),使用这个代价模型进行预测,不完整程序只包含完整程序中循环转换的部分。我们使用两个指标进行评估,pairwise comparison的准确度和top-k程序the recall@k(k=10)。如图3展示两条曲线,从各自的50%和0%开始,意味着没有任何信息的情况下进行随机猜测,有50的pairwise comparison的准确度和0%的top-k recall,意味着用完整程序训练的模型在准确预测不完整程序性能时工作不好。
- 顺序决策的固定顺序限制了搜索空间的设计。例如一些优化需要在计算图中添加新的节点(adding cache nodes,使用rfactor),对不同程序的这些决策十分不同。将不完整的程序进行对齐评估十分困难。
- 基于顺序构建的搜索是不可扩展的。扩大的搜索空间需要加入更多的顺序构建步骤,这将导致更差的预测效果。
Ansor的层次化方法
如图2c中展示的,Ansor的后端使用了层次化的搜索空间,解耦了高层次的结构和低层次的细节。Ansor能够自动为计算图构建搜索空间,无需手动开发模板。然后Ansor将对空间中完整的程序进行采样,并对完整的程序进行调优,避免了对未完成程序不准确的估计。图2展示了Ansor方法和现有方法关键的不同之处。
3 Design Overview
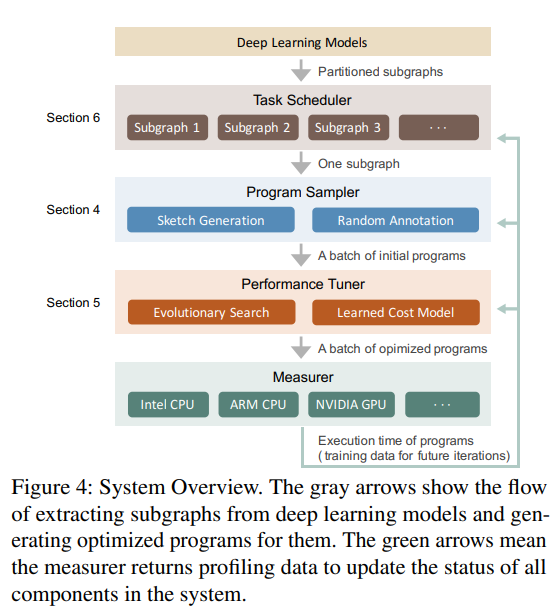
Ansor是一个自动张量程序构建框架。图4展示了Ansor整体的系统结构。输入是一系列需要优化的DNNs,Ansor使用Relay中的算子融合算法将DNNs转化为通用的模型格式(例如ONNX,TensorFlowPB)来划分为更小的子图。然后Ansor为这些子图构建张量程序。Ansor有三个关键组件:
- 一个程序采样器,可以构建巨大的搜索空间并从中采样不同的程序。
- 一个性能调优器,对采样后的程序进行性能调优。
- 一个任务调度器,分配时间资源给DNNs中的众多子图。
程序采样器。Ansor必须解决的一个关键的挑战是,为给定计算图生成巨大的搜索空间。为了覆盖有着多种高层次结构和低层次细节的不同张量程序,Ansor使用层次化的搜索空间表示,有两个级别:sketch和annotation(第4章)。Ansor将高层次的程序结构定义为sketches,剩下的十亿级别的低层次选择(例如tile size,parallel,unroll annotations)定义为annotations。这种表示允许Ansor灵活地枚举高层次结构,并高效地对低层次细节进行采样。Ansor包含一个程序采样器,对空间中的程序进行随机采样,全面覆盖搜索空间。
性能调优器。随机采样的程序性能不一定较好,下一个挑战是对它们进行调优。Ansor使用进化搜索和可学习的代价模型迭代地进行调优(第5章)。在每次迭代中,Ansor使用新程序的重采样和之前迭代中留下的较好的程序作为初始人口,开始进化搜索。进化搜索调优程序通过变异和交叉(无顺序的重写),解决了顺序构建的限制。从可学习的代价模型查询性能比实际运行测量快上多个数量级,所以我们能够在数秒内评估上千个程序的性能。
任务调度器。使用程序采样和性能调优使得Ansor为计算图找到高性能的张量程序。直觉上讲,将整个DNN视为单个的计算图,并为其创建一个完整的张量程序很有可能达到最优的性能。但是,这种做法十分低效,因为必须面对不必要的指数级增长的搜索空间。经典的做法是,编译器将一个DNN中大的计算图划分为几个小的子图(TVM,Relay)。由于DNNs逐层构建的特性,这种划分对于性能的影响很小。这给Ansor带来了最后的挑战:如何在为多个子图构建程序时分配时间资源。Ansor的任务调度器(第6章)使用一种基于梯度下降的调度算法,将资源分配给那些更有可能提高端到端DNN性能的子图。
4 Program Sampling
搜索空间算法搜索并决定它能找到的最好的程序。现有的方式构建的搜索空间有以下限制和特点:
- 手动枚举(TVM)。通过模板手动枚举所有可能的选择是不切实际的,所以现有的手工模板只能启发式地覆盖有限的搜索空间。
- 激进地提前剪枝(Halide auto-scheduler)。根据未完成程序的性能评估进行提前剪枝,这阻碍了搜索算法发现搜索空间中的某些区域。
本章我们将介绍把搜索空间的边界进一步往外推的技术,解决了以上限制。为了解决(1),我们递归应用灵活的推导规则集合,自动扩大搜索空间。为了解决(2),我们随机地对搜索空间中完整的程序进行采样,因为随机采样有相同的概率采样到每一个点,我们的搜索算法有可能发现空间中的任意一个程序。我们并不依赖随机采样找到最优的程序,因为每一个采样的程序将在之后进行调优(第5章)。
为了能够采样到足以覆盖搜索空间的程序,我们定义了有两个层次(sketch和annotation)的层次化搜索空间。我们定义高层次的程序结构为sketches,剩下的十亿级的低层次选择(tile size,parallel,unroll annotations)作为annotations。在顶层,我们通过递归地应用一些推到规则构建sketches;在底层,我们随机地对这些sketches进行注解,得到完整的程序。这种表示从数十亿种低层次选择中摘要出了一些最基本的结构,能够灵活地枚举高层次结构,并高效采样低层次细节。
Ansor支持CPU和GPU,我们将在4.1和4.2中阐释CPU的采样过程,然后在4.3中讨论在GPU上的过程有何不同之处。
4.1 Sketch Generation
如同图4所示,程序采样器接受划分好的子图作为输入。图5的第一列展示了输入的两个例子。输入有三个等价形式:数学表达式、通过直接展开循环指数获得的原始程序、对应的计算图(有向无环图,DAG)。
为了给有多个节点的DAG构建sketches,我们按照拓扑顺序遍历所有节点,逐次构建结构。对于计算节点来说,节点是计算密集型的,有很多数据重用的机会(conv2d,matmul),我们为这些算子建立基本的分块和融合结构作为sketch。对简单的element-wise节点(ReLU,element-wise add),可以安全地内联这些算子。注意,一些新的节点(caching nodes,layout transform nodes)可能会在创建sketch的过程中被引入到DAG。
我们提出了一种基于推导的枚举方法,通过递归地应用几个基本规则创建所有可能的sketch。这个过程将一个DAG作为输入,输出一系列skteches。我们定义状态State \(\sigma = (S, i)\),其中S是当前为DAG部分构建完成的sketch,i是目前节点的index。DAG中的节点安装从输出到输入的顺序进行拓扑排序。推导从最原始的程序和最后一个节点开始,初始状态state \(\sigma = (\text{navie program, index of the last node})\)。然后我们递归地在状态上应用全部推导规则。对于每一条规则,如果当前状态满足应用条件,就对状态\(\sigma = (S, i)\)应用规则得到\(\sigma' = (S', i')\),其中\(i' \le i\)。这种方式index i单调减少。当i=0,一个状态就成为终止状态。在枚举中,多个规则可能应用在一个状态上,产生多个成功的状态,一条规则也可能产生多个成功的状态。所以我们维护一个队列来存储所有中间状态。当队列为空时,过程停止。sketch构建结束后,所有在终止状态的\(\sigma.S\)形成了sketch列表。对于一个典型的子图,sketches的数量一般少于10个。

推导规则。表1列出了我们在CPU上使用的推导规则。我们首先提供条件的定义,然后描述每条规则的作用。IsStrictInlinable(S, i)表示S中的节点i是否为简单的element-wise算子,这类算子总是可以内联(e.g., element-wise add, ReLU)。HasDataReuse(S, i)表示S中的节点i是否为计算密集算子,这类算子有更多的算子内数据重用的机会(e.g., matmul, conv2d)。HasFusibleConsumer(S, i)表示S中的节点i是否只有一个消费者j,并且节点j能够被融合进节点i(e.g., matmul + bias_add, conv2d + relu)。HasMoreReductionParallel(S, i)表示S中的节点i是否在空间轴上几乎没有并行,但在规约轴上有大量的并行机会(e.g., 计算矩阵的2-norm, 矩阵乘C_2_2 = A_2_512 * B_512_2)。我们在计算定义中执行静态分析来获得这些预测所需要的值。分析过程通过解析数学表达式中读写的模式自动完成。下一步,我们介绍每个推导规则的作用。
规则1只是简单跳过一个不是严格可内联的节点。规则2总是内联那些严格可内联的节点。因为规则1和2的条件是互斥的,一个i > 1的状态智能满足他们中的一条,并继续推导。
规则3,4和5对有数据重用的节点进行多级分块和融合。规则3对能够数据重用的节点执行多级分块,在CPU上,我们使用SSRSRS的分块结构,S表示空间轴的分块,R表示规约轴的分块。例如,在矩阵乘法C(i, j) = A(i, k ) * B(k, j)中,i和j是空间轴,k是规约轴。这种SSRSRS的结构将(i, j, k)循环展开为10层循环(i0, j0, i1, j1, k0, i2, j2, k1, i3, j3)。虽然我们不改变循环的顺序,这种多级分块同样能够覆盖一些重排序的情况。例如将上面的10层循环特化为重排序(k0, j2, i3),只需要设置其他循环次数为1。这种SSRSRS分块结构对深度学习中的计算密集型算子是通用的(e.g., matmul, conv2d, conv3d),因为它们都是由空间轴的循环和规约轴的循环组成。
规则4执行多级分块,并将可融合的消费者进行融合。例如,我们将element-wise算子(e.g., ReLU, bias add)融合进分块的算子(e.g., conv2d, matmul)。如果当前数据重用节点没有可融合的消费者,规则5将加入一个caching节点。例如,DAG图中最后的输出节点没有任何消费者,所以它直接将结果写入主存。但这种做法是低效的,因为访存有较高的延迟。通过cache节点融合,最终输出节点将结果写入cache块,块中所有计算完成之后cache块一次写入主存。
规则6使用rfactor,将规约循环分解为空间循环,提高并行度。

样例。图5展示了三个构建好的sketches样例。这些sketches与TVM的手工模板不同,因为手工模板既指定了高层次结构,又指定了低层次细节,而sketches仅仅定义高层次机构。例如对于例子input1,DAG中排序后的四个节点为(A,B,C,D)。为了给DAG推导sketches,我们从输出节点D(i=4)开始,并依次对这些节点应用规则。特别地,sketch1的推导过程是:
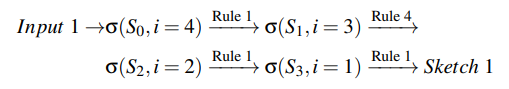
对于样例input2,排序后的5个节点为(A,B,C,D,E)。类似地,从输出节点E(i=5)开始递归地应用规则。sketch2推导过程:
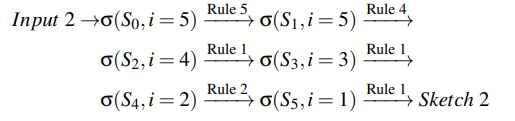
类似地,sketch3的推导过程:
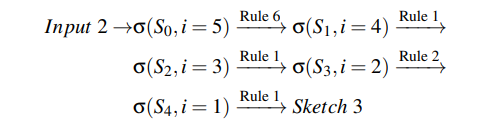
定制。虽然提出的这些规则在实践中足以覆盖大多数算子的结构,但是总会有异常情况。例如一些特殊的算法(e.g., Winograd convolution)和加速器原语(e.g., TensorCore)需要特殊的分块结构提升性能。虽然基于模板的搜索方法(TVM)能够为每一种新的情况手写新的模板,但这需要大量的设计工作。另一方面,Ansor中基于推导的sketch创建足够灵活,能够为各种新出的算法和硬件生成需要的结构,因为我们允许用户注册新的推导规则,并与已有的规则进行整合。
4.2 Random Annotation
上一章节中生成的sketches是不完整的程序,因为它们仅有分块结构,但没有具体的分块大小和循环注释,例如并行,展开,向量化。在这一章节中,我们对sketches进行注释,使其变为完整程序,能够进行后续的调优和评估。
给定一个生成的sketches列表,我们随机选取一个sketch,随机填充分块大小,并行一部分外层循环,向量化一部分内层循环,展开很少一部分内层循环。我们还随机改变程序中一些节点的计算位置,对分块结构进行一些轻微的调整。这里的所有“随机”指的是所有有效值的均匀分布。如果一些特殊的算法需要特定的注释来提升性能(e.g., special unrolling),我们允许用户在计算定义中给出一些简单的提示,来应用这种注释的策略。最终,因为改变常量张量的布局可以在编译期间完成,不回带来运行时开销,我们根据多级分块结构重写常量张量的布局,使得它们尽量地cache友好。这种优化十分有用,因为卷积的权重张量或者dense layers对于推理程序来说都是常量。
随机采样的样例如图5展示的,采样的程序可能包含比sketch更少的循环,因为循环长度为1的部分被简化了。
4.3 GPU Support
对于GPU,我们改变原来的SSRSRS多级分块结构为SSSRRSRS来匹配GPU的体系结构。循环中的前面三个空间分块轴分别绑定至BlockIdx,虚拟线程(减少规约带宽冲突),ThreadIdx。我们加入两条sketch的推导规则,一条是通过加入caching节点利用shared memory(类似于规则5),另一条是为了cross-thread规约(类似于规则6)。
5 Performance Fine-tuning
经过程序采样器采样的程序在搜索空间中有很好的聚集性,但是它们的性能没有保障。这是因为优化的选择,例如分块结构和循环注释都是随机采样的。本章将介绍性能调优器,通过进化搜索和可学习的代价模型对采样的程序调优。
调优是迭代执行的。在每一轮迭代中,我们首先使用进化搜索找到一小批根据代价模型得到的有希望的程序,然后再硬件上测量实际的执行时间,最终测量得到的数据将被用于重新训练代价模型,使其更加准确。
进化搜索使用随机的采样程序,以及之前测量中的高性能程序作为初始人口,然后应用变异和交叉产生下一代。代价模型用于预测每个程序的健康值,这里的情况是一个程序的吞吐量。我们运行进化得到一个固定数目几代程序,从搜索的过程中选择最好的程序。我们使用可学习的代价模型,因为代价模型能够相对准确地估计程序的健康值,比起实际测量快几个数量级。这允许我们在数秒内比较上千个程序的性能,然后选取最优希望的程序进行实际的运行测量。
5.1 Evolutionary Search
进化搜索是一个通用的元启发式算法,从生物进化中获得灵感。通过迭代地变异高品质程序,我们能够产生潜在的更高品质的程序。进化从采样的最初一代开始,为了创建下一代程序,我们首先根据一定概率从这一代中选择一些程序。选择程序的概率与代价模型预测的健康值成比例,这意味着有更高性能得分的程序更有可能被选择。对于选出来的程序,我们随机应用一种进化操作产生一个新的程序。基本上,对于在采样(4.2)中的每一种决策,我们设计了一个对应的进化操作来重写并进行调优。
Tile size mutation。这个操作扫描整个程序,然后随机算则一个分块的循环。对于这个分块的循环,将该级别的分块大小除以一个随机的因子,然后将这个因子乘到另一级别上。因为这个操作保持分块大小的乘积与原始循环长度相同,所以变异后的程序总是有效的。
Parallel mutation。一些优化需要通过编译器的注释进行指定。这个操作扫描程序,然后随机选择一个注释,对于这个注释,这个操作随机变异注释为另外一个有效的值。例如,我们潜在的代码生成器支持提供最大数量的自动展开,使用auto_unroll_max_step=N的注释,我们随机减少这个N的值。
Computation location mutation。这个操作扫描程序,随机选择一个灵活的节点,这个节点不是多级分块的(e.g., 卷积层的padding节点)。对于这个节点,操作随机改变它的计算位置到另一个有效的连接点。
Node-based crossover。交叉通过组合两个或更多父代的基因产生新的后代。在Ansor中,程序的基因是它们的重写步骤。每个Ansor生成的程序都是从最初的原始实现中重写得到的。Ansor在sketch创建和随机注释的过程中,为每个程序保存了完整的重写历史。我们可以将重写步骤视为一个程序的基因,这是因为它描述了程序如何从最初的原始实现形成而来。基于这一点,我们能够通过组合两个已有的程序生成新的程序。但是,从两个程序中任意组合重写步骤可能会打破步骤之间的依赖关系,生成无效的程序。Ansor中交叉操作的粒度是DAG中的节点,因为交叉不同节点的重写步骤通常有更少的依赖关系。Ansor为每个节点随机选择一个父代,然后与被选择节点的重写步骤混合。当节点间存在依赖关系时,Ansor尝试分析并启发式地简单调整步骤。Ansor进一步验证混合程序来保证功能的正确性。验证是简单的,因为Ansor只使用循环变换重写步骤的很小一部分集合,然后底层的代码生成器能够通过依赖关系分析检查正确性。
进化搜索利用变异和交叉来生成一系列候选者,重复几轮之后输出有最高得分的一小部分程序。这些程序将被编译并在目标硬件上运行,获得真实的运行时间开销。收集到的测量数据被用于更新代价模型。通过这种方式,代价模型在目标硬件上的准确性会逐步提升。最后,进化搜索能够为目标硬件平台逐渐生成更高品质的程序。
不同于TVM和FlexTensor的搜索算法,它们只能在一个固定的网格状参数空间中工作。在Ansor中,针对张量程序专门设计了进化搜索。能够应用于通用的张量程序,解决有复杂依赖关系的搜索空间。不像Halide自动调度器的unfolding规则,这些操作能够对程序无顺序的修改,解决了顺序的限制。
5.2 Learned Cost Model
为了在搜索过程中快速估计程序的性能,代价模型是必要的。我们采用了与相关工作(Halide,TVM)类似的可学习的代价模型。基于可学习代价模型的系统有更好的可移植性,因为一个模型的设计可以在不同硬件后端上复用,只需要提供不同的训练数据。
由于我们的目标程序主要是数据并行的张量程序,通常由多级嵌套循环和最内层的一些赋值语句组成,我们训练代价模型来预测最内层循环的单个语句。对于整个程序,我们讲每一个最内层的语句预测得分相加作为整体的得分。我们通过提取整个程序的上下文特征构建最内层语句的特征向量。提取的特征包括计算特性和访存特性。(一个具体的提取特征列表在本文的附录中[58])
我们使用加权的平方误差作为损失函数。因为我们主要关心如何从搜索空间中找到性能高的程序,我们将更多的权重放在那些运行时间快的程序上。具体来说,模型f对有着y吞吐量的程序P的损失函数为
其中S(P)是程序P最内层循环语句的集合。我们直接使用吞吐量y作为权重。训练gradient boosting决策树作为基本模型f。模型训练用于从所有DAG图中的张量程序。我们一个DAG图中的所有张量程序的吞吐量归一化至[0, 1]。在优化DNN时,需要测量的程序数量通常小于30000。训练gradient boosting decision tree在这样的小数据集上是非常快的,所以我们每次都重新训练一个新的模型,而不是做一些更新。
6 Task Scheduler
一个DNN可以被划分为多个独立的子图(e.g., conv2d + relu)。对于这些子图,花费时间对它们进行调优并不能显著提升端到端DNN的性能。这有两方面原因:
- 子图不是性能瓶颈。
- 调优对于子图的性能只有微小的提升。
为了避免浪费时间对不重要的子图调优。Ansor动态分配不同的时间资源给不同的子图。拿ResNet-50作为例子,图划分后模型有29个不同的子图。大多数子图是有着不同形状配置(输入size,kernel size,stride等)的卷积层。我们需要为不同的卷积层创建不同的程序,因为最好的张量程序依赖于这些shape的配置。在实际应用中,用户可能在应用中使用了多个DNNs,这产生更多子图,也有更好的机会减少整体的调优时间。因为我们可以在子图直接重用和分享一些已有的知识。一个子图可以在DNN中出现多次,或者在不同DNN中出现多次。
我们将为一个子图构建高性能程序的过程定义为一个任务。这意味着优化一个DNN需要完成多个tasks(e.g., ResNet-50需要29个任务)。Ansor的任务调度器在迭代中为任务分配时间。在每次迭代时,Ansor选择一个任务,创建该子图的一批优化程序,并在硬件上测量。我们定义一次迭代为时间资源的单位。当我们分配一个单位的时间资源给一个任务,任务将获得机会生成并测量新的程序,这将有机会找到更优的程序。我们接下来介绍对于调度问题的描述以及解决方法。
6.1 Problem Formulation
在调优一个DNN或者一系列DNNs时,用户可能有多种目标,例如减少DNN的延迟,达到一组DNNs的延迟需求,或者当调优DNN不能显著性能时,最小化调优时间。因此,我们提供给用户一些目标函数来表达他们的目标,用户可以自定义他们的目标函数。
假定总共有n个任务。\(t \in Z^n\)为分配向量,其中\(t_i\)是花费在任务i上的时间单位。令任务i能使得子图达到最小延迟为分配向量的函数\(g_i(t)\),端到端模型的开销是子图的函数\(f(g_1(t), g_2(t), ..., g_n(t))\)。目标是最小化端到端开销:\(f(g_1(t), g_2(t), ..., g_n(t))\)

为了最小化单个DNN的端到端开销,我们定义\(f(g_1(t), g_2(t), ..., g_n(t)) = \sum^n_{i=1}w_i \times g_i\),其中w_i是DNN中任务i出现的次数。这个公式是符合直觉的,因为f是DNN延迟的近似表达。
当调优多个DNNs时,有几种选择。表2展示了调优多个DNNs的一些目标函数示例。令m是DNNs的数量,S(j)是属于DNN j的任务,f_1累加每个DNN的延迟,意味着优化一个流水线,其中串行地执行每个DNN一次。f_2中,定义L_j为DNN j的延迟需求,表示一个DNN达到延迟需求后,不希望继续花费时间调优。f_3中定义B_j为DNN j的参考延迟,目标是最大化加速比的几何平均值。f_4中,定义函数ES(g_i, t),返回提前终止值,通过查找任务i的历史,这可以让每个任务尽早停止。
6.2 Optimizing with Gradient Descent
我们提出了一种基于梯度下降的调度算法来高效地优化目标函数。给定当前分配t,想法近似于梯度下降的目标函数\(df/ft\),目的是为了选择任务i使得\(i = argmax(df/dt)\)。我们通过optimistic guess并考虑任务之间的相似性来估计这个梯度。推导过程在本文的俘虏,估计梯度使用以下方法。
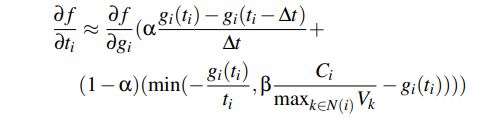
其中,\(\Delta t\)是一个小的反向窗口大小,g_i(t_i)和g_i(t_i - \delta t)可以从历史的分配中得到。N(i)是与任务i相似的任务集合,C_i是浮点算子在任务i中的数量,V_k是每秒钟能从任务k得到的浮点算子的数量。参数alpha和beta用于控制权重,以信任某些预测。
为了运行这个算法,Ansor从t=0开始,并利用循环warm up,得到初始的分配向量t = (1, 1, ..., 1),warm-up结束后,在每轮迭代中计算每个任务的梯度,选择其中最大的。然后分配资源单位并更新分配向量t_i = t_i + 1。优化的过程不断进行,直到用完时间资源。为了鼓励搜索过程,我们采用了一种贪心策略,保留\(\epsilon\)的可能性随机选择一个任务。
以优化一个单独的DNN端到端延迟为例,Ansor优先选择有着最高初始延迟的子图,因为估计方法认为有最大的优化空间。然后,如果Ansor花费了很多轮迭代,但并没有观察到延迟的减少,Ansor将选择其他子图,因为\(df/dt\)减小了。
7 Evaluation
Ansor的核心是采用C++实现的,大约12K行代码(3K的搜索策略,9K的其他框架)。Ansor使用自己的IR生成程序,这些程序下降到TVM的IR进行目标代码生成。Ansor利用TVM作为最终的代码生成器。
我们在三个层次上评估生成的程序:单算子,子图,整体的神经网络。在每个级别的评估中,我们比较Ansor和state-of-the-art搜索框架,以及硬件专用的手工优化库。我们还评估Ansor的搜索效率,以及各个搜索组件的效率。
生成的张量程序以三个硬件平台作为基准:Intel CPU(18核 Platinum 8124M@3.0GHZ),NVIDIA GPU(V100),以及ARM CPU(4核 Cortex-A53@1.4GHZ on the Raspberry Pi 3b+),我们使用float32数据类型。
7.1 Single Operator Benchmark
Workloads。我们首先评估Ansor在常见深度学习算子的效果,包括1D,2D,3D卷积,矩阵乘法,组卷积,dilate卷积,深度卷积,转置卷积,capsule卷积,matrix 2-norm。对于每个算子,选择4中常见的shape配置,并用两个batch sizes 1和16。总共有10 op * 4 shape * 2 batch size = 80 test cases。shape配置在本论文的目录。我们在Intel CPU上运行这些cases。
Baselines。我们使用PyTorch(v1.5),Halide auto-scheduler(commit: 1f875b0),FlexTenso(commit: 7ac302c),AutoTVM(commit: 69313a7)作为基准,PyTorch后端是供应商提供的算子库MKL-DNN,Halide auto-scheduler是基于Halide搜索框架顺序构造。AutoTVM和FlexTensor是基于TVM的模板搜索框架。因为Halide auto-scheduler不支持AVX-512模型的与训练,我们不使用AVX-512模型作为(7.1, 7.2)评价,对于每个算子,我们使用每个框架能取得最好的layout。
Search setting。针对每个case,我们让搜索框架运行或调优1000次。总共可以测量最多80 * 1000个程序。使用相同的测试尝试是公平的,在不清楚详细实现的情况下。另外,1000次测量通常足以让这些框架收敛。
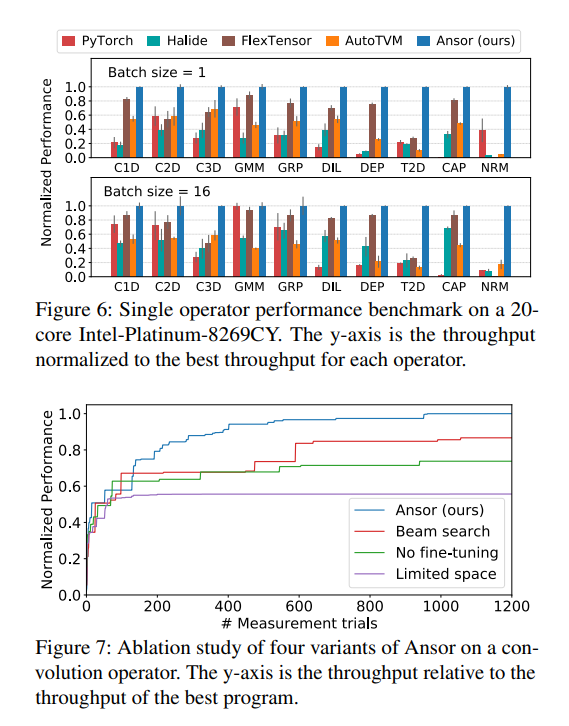
Normalization。图6展示了归一化的表现。对于每个test case,我们用最好框架的结果归一化。画出4种shape的平均结果。所以最好的框架结果为1,error bar表示标准差。
Results。如图6所示,Ansor在所有算子和batch size中表现最好,或与最好的性能相当。Ansor相比于现有框架加速了1.1 - 22.5倍。Ansor的性能提升来自于它巨大的搜索空间和高效的搜索策略。对于大多数算子,我们能够在现有框架的搜索空间之外构建出最优的程序,因为Ansor能够探索更多的优化组合。例如,NRM的加速是因为Ansor能够并行规约loops,而其他的框架不行,T2D的加速是因为Ansor可以使用正确的分块结构和展开策略,使得代码生成器简化了0的乘法。而其他框架不能捕捉这些有用的优化。例如,Halide的展开规则不能将GMM规约循环进行分块,C2D的外层规约循环也不能分块。AutoTVM的模板限制了分块结构,不能覆盖Generated Sketch 1,(图5)。FlexTensor的模板,在padding位置改变时无法改变,所以NRM等算子无法进行优化。
Ablation study。我们运行了4种不同情况下Ansor在卷积算子的表现,并绘制出曲线。我们选择ResNet-50的最后一个卷积算子,batch size=16作为test case,因为搜索空间足够大,能够有效评估搜索策略。其他算子也有类似的模式。图7表示,每个曲线是5次运行的。Ansor(ours)使用所有介绍到的技术,Beam Search在采样过程中不进行调优,并截断不完整的程序。No fine-tuning不进行调优,只进行随机采样。Limited space限制搜索空间大小,更类似于手工模板方法。如图7所示,去掉了这些技术之后,搜索空间和调优的去除对最终性能都有显著影响。激进地提前阶段程序,由于不准确的估计,排除了一些最终性能较好的程序。
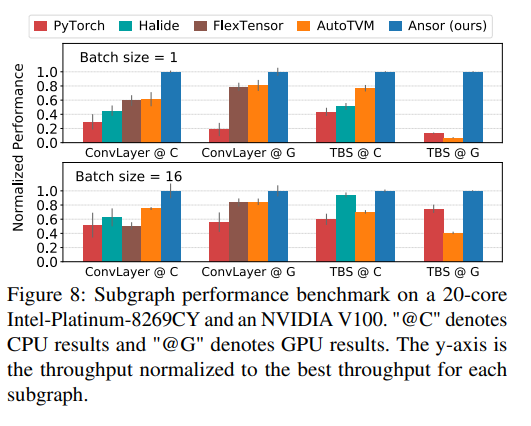
7.2 Subgraph Benchmark
我们在DNN的两个常见子图上进行评估。ConvLayer包括2D卷积,batch normalization和ReLU激活函数,是卷积神经网络的一个常见模式。TBS包括两个转置矩阵乘法,一个batch矩阵乘法,softmax,是多头注意力中的模式。与7.1中单算子模式类似,我们选择4个不同的shape配置和两个batch size,每个test case运行1000次,输出归一化的结果。我们使用相同的baseline框架,在Intel CPU和NVIDIA GPU上运行。Halide auto-scheduler在GPU的支持还在试验阶段,所以没有进行实验,FlexTensor无法运行复杂的子图,例如TBS。
图8展示了Ansor由于手工算子库和其他搜索框架约1.1-14.2倍,Ansor能够在不同平台生成高性能程序。FlexTensor在单算子上表现较好,但是在子图上表现较差,因为对算子融合的支持较少。
7.3 End-to-End Network Benchmark
Workloads。我们测试了几个DNN的端到端推理执行时间,包括ResNet-50,MobileNet-V2,用于图像分类;3D-ResNet-18,用于动作识别;DCGAN generator,用于图像生成,以及BERT,用于语言理解。我们在三个硬件平台上进行测试。对于服务器级别的Intel CPU和NVIDIA GPU,我们记录batch size 1和16的结果,对于边缘设备ARM CPU,实时性十分重要,所以我们只记录batch size 1的结果。
Baselines and Settings。我们使用PyTorch(v1.5 with torch script),TensorFlow(v2.0 with graph mode),TensorRT(v6.0 with TennsorFlow integration),TensorFlow Lite(V2.0)和AutoTVM作为baseline框架。我们没有使用Halide auto-scheduler和FlexTensor,因为它们对常见的深度学习模型格式(ONNX,TensorFlow PB)和高层的图优化支持较差。最终,我们期待端到端的执行时间是DNN中所有子图延迟的总和。AutoTVM能通过手工模板和图级别优化(e.g. graph-level layout search, graph-level constant folding)显著提升性能。Ansor同样执行了layout重写,如4.2章的描述。我们让AutoTVM和Ansor运行自动调优,直到进行了1000 * n次尝试,其中n是子图的数量。这通常来说可以收敛。我们设置目标为最小化DNN的整体延迟,并逐个构造程序。PyTorch,TensorFlow,TensorRT,TensorFlow Lite都使用静态kernel库(MKL-DNN on Intel CPU, CuDNN on NVIDIA GPU, Eigen on ARM CPU)不支持自动调优,AVX-512在Intel CPU上框架均使用。
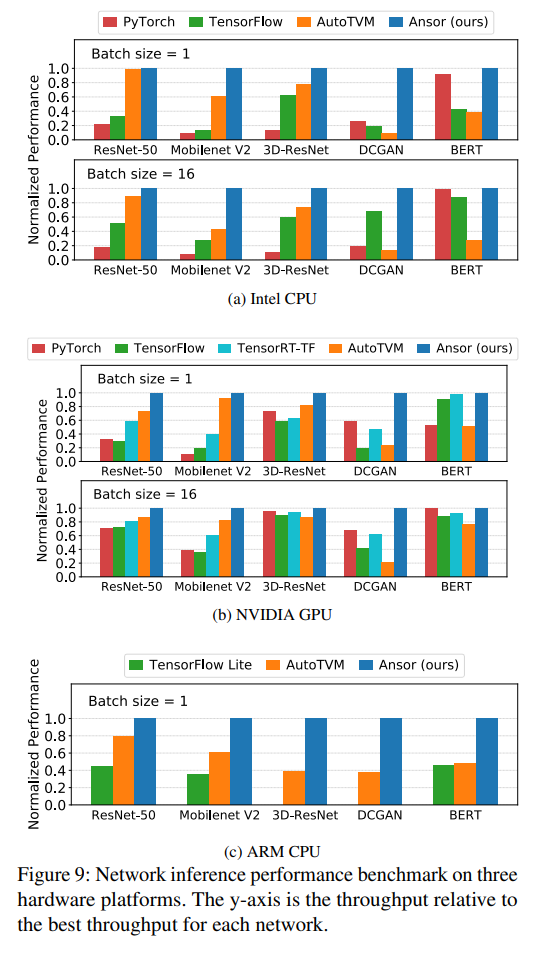
Results。图9展示了Intel CPU,NVIDIA GPU和ARM CPU上的结果。整体上,Ansor展现出了最好或与最好相当的性能。与基于搜索的AutoTVM相比,Ansor达到或超越了所有的cases,有1.0 - 21.8的加速比。与最好的选择相比,Ansor提升了DNN的执行性能,分别在Intel CPU,ARM CPU和NVIDIA GPU有3.8,2.6和1.7的加速比。DCGAN的显著加速是因为其主要包括transpose2d卷积,能够被Ansor很好地优化。AutoTVM由于高度优化的模板以及global layout搜索取得了很好的性能。Ansor不进行global lay搜索,但重写weight张量的layout(4.2章)。Ansor使用更多层分块,将weight张量分为更多层。对于ResNet-50,layout rewrite带来大约40%的提升。与供应商提供的静态算子库相比,Ansor在不常见的shapes和小batch size上有更多优势,因为这些情况不容易进行手工优化。
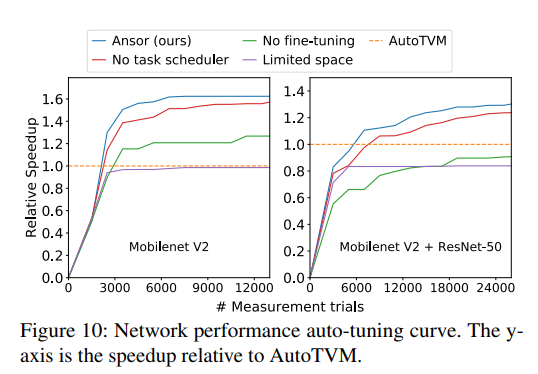
Ablation study。我们在如图10的两个test cases上进行。左边的图进行4个变量,为单个mobilenet-V2生成程序。右边的图为mobilenet-V2和ResNet-50生成程序。设置纵坐标值为相比于AutoTVM的加速比。如图10所示,No task scheduler表示使用循环分配策略,对所有子图分配相同的资源。Limited space限制搜索空间。No fine-tuning不进行调优,只随机采样。Limited space效果最差,证明最优程序不在限制的搜索空间中。No fine-tuning,随机指定分块和注解的效果不比AutoTVM的效果更好。No task scheduler在两个cases均比AutoTVM更好,Ansor在搜索效率和最终性能上都表现最好。
7.4 Search Time
Ansor高效搜索,能够用更少的搜索空间达到或超过AutoTVM的性能。Ansor将时间划分,利用任务调度器同时优化所有子图。而AutoTVM和其他系统没有这个任务调度器,所以它们逐个为子图生成代码。Ansor节省了搜索时间,通过优先处理重要的子图,而AutoTVM在每个子图上都需要花费预定义好的时间,可能会在不重要的子图上有所浪费。
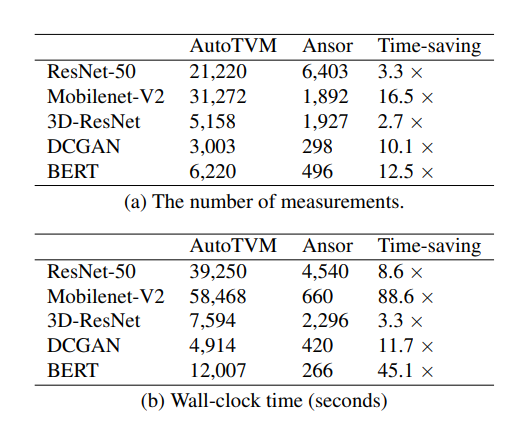
表3展示了Ansor在Intel CPU网络上要达到AutoTVM性能所需要的搜索时间。我们列出两个矩阵:测量次数和墙钟时间。测量次数是搜索耗费的时间,墙钟时间是整体的时间。如表所示,Ansor能够使用更短的时间达到AutoTVM的性能。3a表示从任务调度器中节省了搜索时间。3b表示Ansor没有引入过多的提前搜索,以及有更准确的测量。(在Intel CPU上,Ansor使用更少的次数找到精确的测量),在其他后端上,Ansor相比于AutoTVM节省的时间也与此类似。
特别地,Ansor在单个机器上为一个完整的子图构建优化程序需要数个小时。对于推理应用是可接受的,因为在部署之前只会进行一次。另外,整体的Ansor架构能够容易地被并行。
7.5 Cost Model Evaluation
本章,我们评估可学习代价模型的预测质量。我们使用在Intel CPU调优ResNet-50时测量的25000个程序作为数据集。其中随机选择20000个作为训练集,剩下5000个作为测试集。
图11画出了预测吞吐量和测量吞吐量,吞吐量根据采样的性能最好程序归一化。预测吞吐量时模型的输出,所以它们可能是消极的。图11a,点分布在对角线上,意味着模型做出了准确的预测。分布不是均匀的,因为程序是搜索过程中收集的。好的程序有更高的可能性被选择。所以大多数程序在图中的右上角。吞吐量为0的程序是无效的,或者由于超时kill掉。在图11b中,我们排序了5000个点,从最慢的到最快的程序,使用相对排名作为x坐标,所以在x坐标上是均匀分布的。这更好地展示了搜索程序的性能。
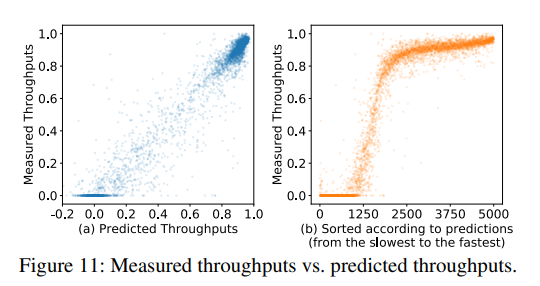
模型在测试集上到达了0.079RMSE,0.958R^2相关,0.851 pairwise comparison accuracy,0.624 recall@30 of top-30 programs。
8 Related Work
Automatic tensor program generation based on scheduling languages。Halide提出了调度语言,可以描述循环优化原语。这种语言对于手动优化和自动优化都十分合适。Halide有三种自动调度版本,基于不同的技术。最新的使用beam search和可学习的代价模型是其中最好的,也被用于我们的实验。TVM实现了类似的调度语言,以及基于模板指导搜索的AutoTVM。FlexTensor提出通用模板,可以应用于一系列算子,但是他的模板是对单个算子设计的,使用它们优化多个算子是不容易的,例如算子融合。同时还有一些工作ProTuner,使用Monte Carlo树搜索,解决了Halide auto-scheduler预测不准确的问题。ProTuner主要针对图像处理,而Ansor针对深度学习,并引入了新的搜索空间和其他优化。
Polyhedral compilation models。多面体编译模型定义程序的优化为一个整数线性编程(ILP)问题。通过仿射变化来优化循环,最小化依赖语句的数据重用距离。Tiramisu和TensorComprehensions是两个多面体编译器,针对深度学习领域。Tiramisu提供了一种类似Halide的调度语言,需要手工进行调度。TensorComprehensions能够自动搜索GPU代码,但是不足以解决计算边界的问题。在conv2d和matmul等算子上的表现不如TVM。这是因为缺少某些优化,以及多面体问题不准确的隐式代价模型。
Graph-level optimization for deep learning。图级别优化将算子视作计算图中的一个基本单位。在图级别执行优化,不改变算子内部的实现。常见的图级别优化包括layout优化,算子融合,常量折叠,auto-batching,auto generation of graph substitution等,图级别与算子级别的优化是相互补充的。图级别优化对于高性能算子的实现也有帮助,例如通用算子融合依赖Ansor的代码生成能力,我们将这部分相交的优化以及更多的图级别优化作为将来的工作。
Search-based compilation and auto-tuning。基于搜索的编译和自动调优早已在其他领域展示出其强大的功能。Stock是一个基于随机搜索的优化器。搜索除了for循环以外的硬件指令序列。而Ansor为嵌套循环生成张量程序。OpenTuner是一个通用的框架,针对程序调优。依赖用户指定搜索空间,而Ansor自动构建搜索空间。传统高性能计算库例如ATLAS和FFTW也使用了自动调优,近来的工作NeuroVectorizer和AutoPhase使用深度强化学习来自动向量化程序,优化编译短语顺序。
9 Limitation and Future work
Ansor的一个限制是Ansor不支持动态shape,Ansor需要计算图中的shape是静态的,并且能够提前知道。如此才能分析并创建搜索空间,执行测量。如何为动态shape和符号生成程序是将来一个有趣的方向。另一个限制是Ansor只支持稠密算子,为了支持稀疏神经网络和图神经网络中常用的稀疏算子(e.g. SpMM),我们期望大部分的Ansor能够被复用,但是我们不希望重新设计搜索空间。最后,Ansor只在high level进行程序优化,依赖其他的代码生成器(e.g. LLVM和NVCC)来进行平台相关的优化(e.g. instruction selection)。Ansor对于特定指令优化的利用不足,例如Intel VNNI,NVIDIA Tensor Core,和ARM Dot执行混合精度以及低精度算子。目前的代码生成器还没有很好地解决这一问题。
10 Conclusion
我们提出了Ansor,一个自动搜索框架,能够为深度神经网络生成高性能张量程序。通过高效地在搜索空间中搜索,优化性能瓶颈。Ansor能够在现有方法之外找到高性能程序,Ansor比现有手工库和基于搜索的框架在一系列神经网络和硬件平台上有至多3.8的加速比。通过自动搜索更好地程序,我们希望Ansor将帮助我们弥补不断提升的算力和有限的硬件表现之间的差距。Ansor目前已经整合进Apache TVM开源项目。
- High-Performance Performance Generating Learning Programhigh-performance performance generating learning high-performance high-performance performance networking the high-performance performance imperative cdeepfuzz high-performance performance storage object area performance learning合同 generating probability-generating-function generating-function-editor generating approach what best