图文多模态方向:利用现有强大的预训练图像和语言大模型,冻结其参数并通过可训练模块建立起图像与语言模型间联系,实现对图文数据的联合处理能力。
CoGVLM
结构
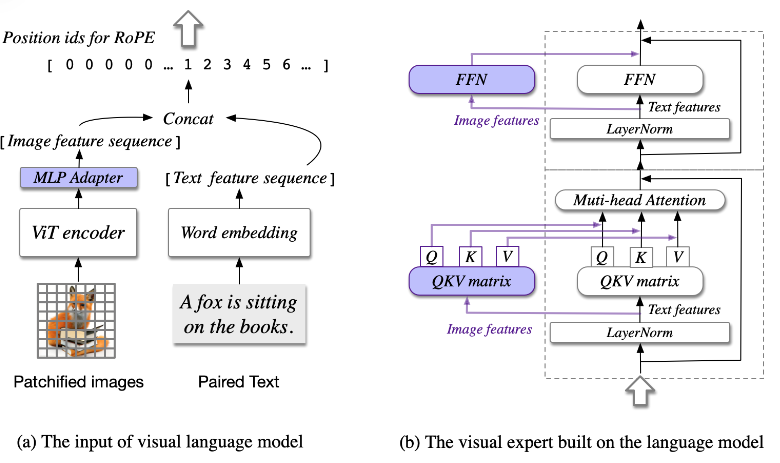
整个网络结构由4部分构成: 视觉模型(ViT encoder), 语言模型(LLM), MLP适配器(MLP adapter),视觉专家模块(visual expert module)。如图1所示。
-
视觉模型 ViT encoder
- 是一个提取图像特征,基于图像patch输入的Transformer模型。去除ViT模型最后一层,因为最后一层聚合[CLS]特征,用来进行对比学习。
-
语言模型 LLM
- 复用大语言模型能力
-
MLP适配器 MLP adapter
- 两层的MLP,将视觉模型提取的图像特征映射到与文本相同维度的特征空间。参考下图1(a),将图片拆分成patch后,经过视觉模型和MLP适配器这两个模块后,与文本特征(经过tokenize和embeding查表后特征)合并在一起。
- 但是图像特征序列共用相同的位置id=0,而文本特征序列的位置id则以其token序号依次增加。
-
视觉专家模块 visual expert module
- 原文用visual expert module表述,参考下图中的图1(b), 紫色标记的部分和与LLM共享的部分,构成了文中描述的Visual expert module。
实际上图1(b)所展示的,已经是视觉处理模块与语言处理模块交叉融合在一起了,融合处理视觉token特征与文本token特征,建立起视觉信息与语言文本信息之间沟通的桥梁。 该模块网络结构源自于语言模型LLM结构,每个Transformer模块中,self-Attention中QKV投影参数,处理视觉token特征的与处理文本token特征的各用一套,FFN层也是类似的。剩余Transformer模块其它参数则是共用的。
为什么会想这么设计呢? 文章认为,自然语言大模型LLM中的每个attention head都获取到语义信息的某个方面,而可训练的视觉专家模块就可以转换视觉图像特征和不同的语言attention head进行对齐,以达到最终的两种模态信息的深度融合。
公式化表示这个过程:视觉模块和语言模块输入前特征分别记为 \(X_I \in \mathbb {R}^{B \times H \times L_I \times D}\), \(X_T \in \mathbb {R}^{B \times H \times L_T \times D}\),二者按token序列方向合并即为 \(X \in \mathbb {R}^{B \times H \times (L_I + L_T) \times D}\)。图1(b)视觉-语言处理模块每层处理过程,有时按上述方式拆分特征,有时则合并特征。
从公式可以看出视觉和文本特征融合交互就发生在了这个softmax过程。
预训练
数据
- 使用的是开源的图文对数据集,包括LAION-2B, COYO-700M。去除无效url,不安全的图片NSFW,有噪音错误的文本注释,有政治偏见的图片,纵横比大于6或者小于6的图片等等,最终剩余1.5B的图片。
- 40M的Visual Grounding 数据集,文本注释中每一个名称在图像中都有一个坐标框标记的视觉物体与之相对应。
训练
- 第一阶段预训练采用的image caption loss,即文本部分的下一个token预测。整个CogVLM-17B模型在1.5B的图文对数据集上训练,batchsize=8192,迭代训练120000次。
- 第二阶段预训练采用混合loss,一个是上一阶段采用的Image caption loss, 一个是Referring Expression Compreshension 简称REC即根据文本物体的描述信息定位出图片中具体位置与之对应的视觉物体(图片中可能存在多个同类物体但是其具体细节或属性有差别)。 比如一种VQA的训练形式: "Question: Where is the object?", “Answer: [[x_0,y_0,x_1,y_1]]” 其中\(x,y \in [0,999]\),表示图片归一化后的坐标位置。 该部分也是仅考虑Answer部分的下一个token预测。 最终batchsize=1024训练60000次,在最后的30000次训练中,将图片输入分辨率有224x224调整为490x490.
- 整个模型的可训练参数是6.5B,训练时长是4096 A100天。
对齐
论文在广泛的任务进一步微调CogVLM,以便将CogVLM与任何主题的自由形式的指令进行对齐。微调后的模型命名为CogVLM-Chat,由于与多样化的指令进行对齐,因此能与人类灵活交流。如图2所示。

数据
用于SFT的高质量指令数据集来自LLaVA-Instruct,LRV-Instruction,LLaVAR和in-house,共计50000万条VQA视觉问答对。由于SFT指令数据集质量至关重要,但是LLaVA-Instruct数据集是由语言GPT-4生成,其中错误不可避免。于是通过人工检测和注释方式修正其中的错误。
SFT
SFT训练阶段,batchsize=640,训练8000次。50步的学习率预热过程,设置学习率为\(lr=10^{-5}\).为了阻止文本问答过拟合数据集,以更小的学习率更新预训练的语言模型,是其它参数学习率的十分之一。在整个SFT阶段,除了ViT encoder参数冻结,其它模块MLP适配模块、视觉专家模块、自然语言模块的参数都是可训练的。相比预训练阶段,增加了自然语言模块的参数,也将用来训练。
为了严格验证本文提出方法训练出的视觉-语言多模态模型的卓越性能和鲁邦泛化性能,论文进行了一系列的多模态测试集定量评估测试。这些测试集可以分为三大类
- 图像注释 Image Captioning:基于图像中的视觉信息,生成一段与之匹配的文本描述。用于测评的数据集集有,NoCaps, COCO, Flickr30K, TextCaps.
- 视觉问答 Visual Question Answering: 给定一张图片,根据文本所描述的关于图像中不同视觉内容问题,回答对应的答案。 用于测评的数据集有VQAv2, OKVQA, TextVQA, VizWiz-VQA, OCRVQA, ScienceQA, TDIUC.
- 视觉定位 Visual Grounding: 将文本信息提到的物体与图片中特定区域物体进行关联。用于测评的数据集有,Visual7W, RefCOCO, RefCOCO+, RefCOCOg。
实验
实验部分就是按照上面提到的三方面测试集,分别展示论文提出的模型是多多么的好啦~
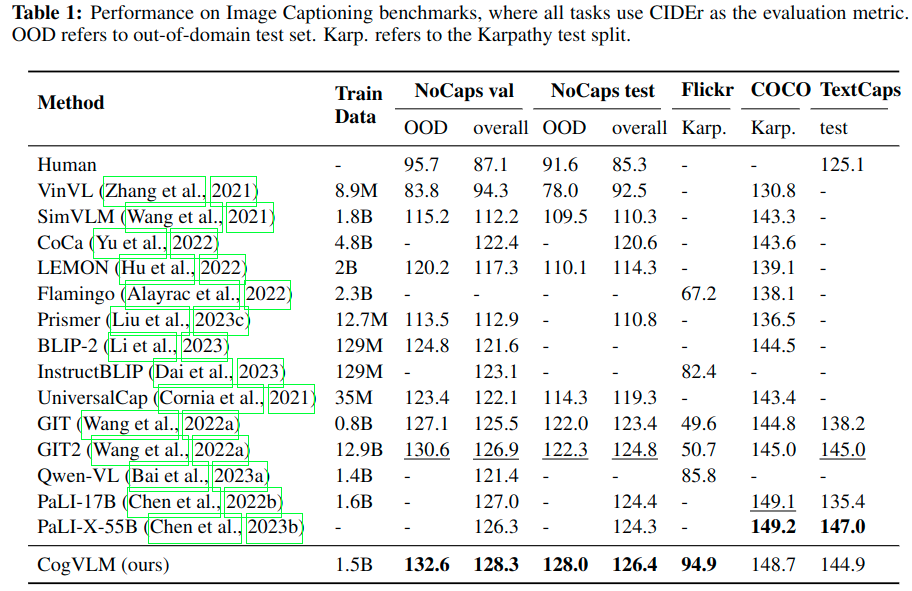
Image Captioning
在Nocaps和Flickr上测试zero-shot能力,在COCO和TextCaps上进行微调测试,具体与其它模型对比指标参考Table.1
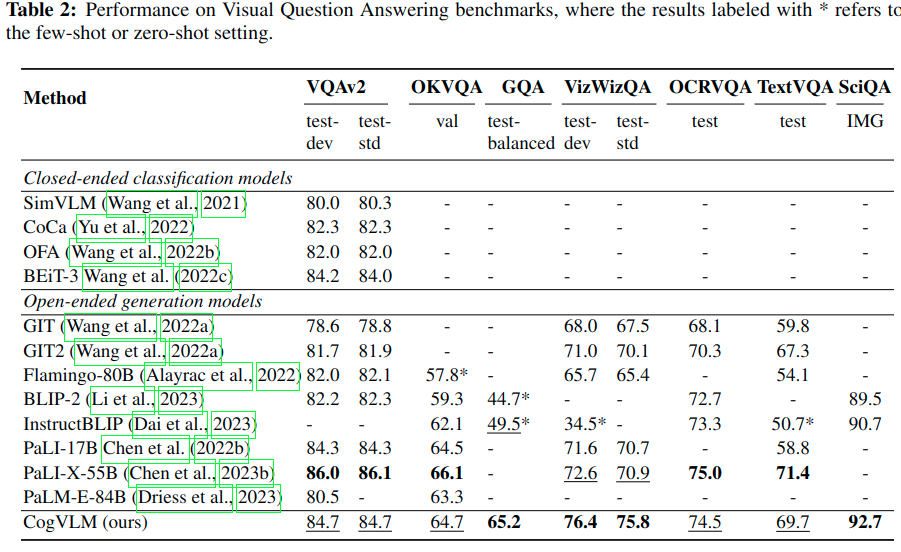
Visual Question Answering
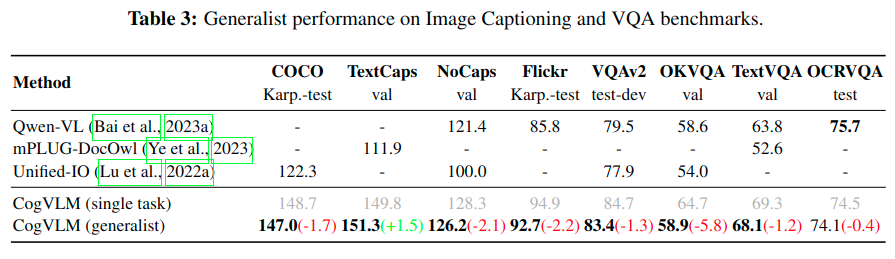
视觉问答式验证模型一般多模态能力的任务,这需要掌握视觉语言理解和常识推理等技能。具体与其它模型对比指标参考Table.2。 同时为了与Unified-IO,Qwen-VL, mPLUG-DocOwl等模型进行公平的对比,论文基于几十种多模态数据构成的数据集上训练一个统一模型并用一致的模型参数进行评估,具体指标对比参考Table.3。
Visual Grounding
论文为了模型具有一致的交互式的视觉定位能力,整理4种相关的数据集。
- Grounded Captioning (GC): 文本描述中的每个名称都有图片相对应的bbox坐标框
- Referring Expression Generation (REG): 图片中的每个坐标框,都有一段文本描述与之相对应,这段描述准确的表示与只带特定区域内的内容。
- Referring Expression Comprehension(REC): 文本描述的与与图片中多个坐标框内相关关联。
- Grounded Visual Question Answering (GroundVQA): VAQ类型的数据集,问题涉及到给定图片中的某个区域中的内容,而非全局。
在基于40M Visual Grounding数据集进行的第2次预训练之后,又基于上述提到的高质量数据集,训练得到了一般性定位增加grounding-enhanced模型,称之为CogVLM-Grounding。具体与其它模型对比指标参考Table. 4