一、集群配置
1、版本使用
|
技术
|
版本
|
|---|---|
| iceberg | 1.3.1 |
| flink | 1.16.1 |
| spark | 3.2.1 |
| hive | 2.3.7 |
| dlc-presto | 待定 |
2、集群配置调整
(1)使用hive查询的话所有hiveserver2节点修改hive-site.xml文件,添加jar包,添加如下配置,然后重启服务
<property>
<name>iceberg.engine.hive.enabled</name>
<value>true</value>
</property>|
|
(2)把iceberg包放入hive auxlib目录中,可以不用每次执行添加jar包操作,放入到hive auxlib目录可以不用重启hive就生效
--1.3.1版本,拷贝后修改权限
cp iceberg-hive-runtime-1.3.1.jar /usr/local/service/hive/auxlib
chmod 755 iceberg-hive-runtime-1.3.1.jar
--0.13.1版本
cp iceberg-hive-runtime-0.13.1.jar /usr/local/service/hive/auxlib
二、客户端连接
1、spark方式连接(推荐)
(1)堡垒机登录服务器glink01
(2)切换root用户有权限跳转服务器,sudo su - root
测试环境:ssh 10.224.194.147
灰度环境(spark3.0.1):ssh 10.224.196.134
线上环境:堡垒机直登10.224.192.138
(3)登录服务器后切换hadoop用户
sudo su - hadoop
(4)spark-sql方式登录(记得exit方式退出,否则资源不释放)
IcebergSparkSessionExtensions是iceberg对spark做的扩展功能,有存储过程、修改表结构等功能测试环境新版(参数已加到配置文件中)
spark-sql --master local[*]
测试环境local方式登录(1.3.1版本):
spark-sql --master local[*] \
--jars /usr/local/service/iceberg/tx-iceberg-spark-runtime-3.2_2.12-1.3.1.jar \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.iceberg_catalog=org.apache.iceberg.spark.SparkSessionCatalog \
--conf spark.sql.catalog.iceberg_catalog.type=hive
spark-sql --master local[*] --jars /usr/local/service/iceberg/tx-iceberg-spark-runtime-3.2_2.12-1.3.1.jar --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.type=hive
测试环境local方式登录(旧的0.13.1版本)
spark-sql --master local[*] --jars /usr/local/service/iceberg/iceberg-spark-runtime-3.2_2.12-0.13.1.jar --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.type=hive线上环境提交yarn方式(1.3.1版本,!!!退出记得用exit方式否则资源不释放)
spark-sql --master yarn \
--deploy-mode client \
--queue sailing \
--name wangshidatest \
--driver-memory 20G \
--num-executors 10 \
--executor-cores 1 \
--executor-memory 16G \
--jars /usr/local/service/iceberg/tx-iceberg-spark-runtime-3.2_2.12-1.3.1.jar \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.iceberg_catalog=org.apache.iceberg.spark.SparkSessionCatalog \
--conf spark.sql.catalog.iceberg_catalog.type=hive \
--conf spark.dynamicAllocation.maxExecutors=15
其它参数-小文件合并时大表才加driver参数
--driver-memory 20G \线上时间戳类型查询报错的话加参数
set spark.sql.storeAssignmentPolicy=ANSI;
yarn上删除任务
yarn application -kill application_id
2、hive方式连接(不推荐)
(1)堡垒机登录服务器glink01
(2)切换root用户有权限跳转服务器,sudo su - root
测试环境:ssh 10.224.194.147
灰度环境(spark3.0.1):ssh 10.224.196.134
线上环境:堡垒机直登10.224.192.138
(3)登录服务器后切换hadoop用户
sudo su - hadoop
(4)方式1:hive客户端方式登录(推荐)
控制台执行:hive
添加iceberg jar包(集群auxlib目录配置的话可不添加):ADD JAR /usr/local/service/iceberg/iceberg-hive-runtime-1.3.1.jar
(5)方式2:beeline方式登录(不推荐-记得exit方式退出)
在控制台执行beeline
进入客户端后连接hiveserver2:!connect jdbc:hive2://10.224.195.139:2181,10.224.195.50:2181,10.224.196.83:2181/;serviceDiscoveryMode=zookeeper;zooKeeperNamespace=hiveserver2
输入账号密码:root|hadoop 密码见内部群或集群配置
查询数据:参考方式一添加jar包后才可以查询
操作后退出:!quit
三、建库建表(管理员操作)
1、创建数据库-现有的话不需要创建
使用ofs存储-常用
create database iceberg_test location "/user/hive/warehouse/iceberg_test.db"
使用emr core节点存储(!!仅测试环境测试用)
create database iceberg_test;
2、删除表(添加PURGE才会删chdfs数据文件,不加只会删hive元数据)
use iceberg_test;
drop table iceberg_test.test3 PURGE;
3、建表-先进库里面
use iceberg_test;
(1)推荐建表sql(指定为format v2,只有v2才支持更新数据)
CREATE TABLE iceberg_test.test3(
id bigint COMMENT 'unique id',
`empcode` STRING
)USING iceberg
TBLPROPERTIES('format-version'='2','table.drop.base-path.enabled'='true');
(2)最基本的建表sql,默认format是v1版本
CREATE TABLE spark_catalog.iceberg_test.test3 (
`id` int ,
`empcode` STRING
) USING iceberg;
(3)修改表format版本
alter table spark_catalog.iceberg_test.test3 SET TBLPROPERTIES('format-version'='2');4、插入测试数据
insert into table spark_catalog.iceberg_test.test3 values (1,"code1");
四、查询数据
#注释了些测试用的参数
#set hive.execution.engine=spark;
#set engine.hive.enabled=true;
#set iceberg.engine.hive.enabled=true;
#set iceberg.mr.catalog=hive;
#set spark.driver.extraClassPath=/usr/local/service/hive/lib/antlr-runtime-3.5.2.jar;
#set spark.executor.extraClassPath=/usr/local/service/hive/lib/antlr-runtime-3.5.2.jar;
#set hive.vectorized.execution.enabled=false;
#set tez.mrreader.config.update.properties=hive.io.file.readcolumn.names,hive.io.file.readcolumn.ids;
use iceberg_test;
select * from iceberg_test.test3;五、文件分析
1、建表后可查看底层数据存储位置。
hdfs dfs -ls /usr/hive/warehouse/iceberg_test.db/test3
目录数据文件如下
drwxr-xr-x - hadoop supergroup 0 2023-10-20 14:51 /usr/hive/warehouse/iceberg_test.db/test3/data
drwxr-xr-x - hadoop supergroup 0 2023-10-20 14:51 /usr/hive/warehouse/iceberg_test.db/test3/metadata
2、分析metadata文件
hdfs dfs -ls /usr/hive/warehouse/iceberg_test.db/test3/metadata
目录数据文件如下
-rw-r--r-- 2 hadoop supergroup 1202 2023-10-20 14:45 /usr/hive/warehouse/iceberg_test.db/test3/metadata/00000-3e5e7244-e7b0-43f4-a5e2-09f166cb0427.metadata.json
-rw-r--r-- 2 hadoop supergroup 2198 2023-10-20 14:51 /usr/hive/warehouse/iceberg_test.db/test3/metadata/00001-063d2d17-58df-41c4-af5f-899add03281c.metadata.json
-rw-r--r-- 2 hadoop supergroup 5799 2023-10-20 14:51 /usr/hive/warehouse/iceberg_test.db/test3/metadata/5183f5e9-7516-4ee8-a454-9c6263b7e624-m0.avro
-rw-r--r-- 2 hadoop supergroup 3776 2023-10-20 14:51 /usr/hive/warehouse/iceberg_test.db/test3/metadata/snap-2379142480402238200-1-5183f5e9-7516-4ee8-a454-9c6263b7e624.avro
3、查看json文件
hdfs dfs -cat /usr/hive/warehouse/iceberg_test.db/test3/metadata/00001-063d2d17-58df-41c4-af5f-899add03281c.metadata.json
{
"format-version" : 1,
"table-uuid" : "26a04890-7a11-4fec-a10f-1344a0e47843",
"location" : "hdfs://HDFS8000006/usr/hive/warehouse/iceberg_test.db/test3",
"last-updated-ms" : 1697784686845,
"last-column-id" : 2,
"schema" : {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "int"
}, {
"id" : 2,
"name" : "empcode",
"required" : false,
"type" : "string"
} ]
},
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "int"
}, {
"id" : 2,
"name" : "empcode",
"required" : false,
"type" : "string"
} ]
} ],
"partition-spec" : [ ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "hadoop"
},
"current-snapshot-id" : 2379142480402238200,
"snapshots" : [ {
"snapshot-id" : 2379142480402238200,
"timestamp-ms" : 1697784686845,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1697784671445",
"added-data-files" : "1",
"added-records" : "1",
"added-files-size" : "656",
"changed-partition-count" : "1",
"total-records" : "1",
"total-files-size" : "656",
"total-data-files" : "1",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "hdfs://HDFS8000006/usr/hive/warehouse/iceberg_test.db/test3/metadata/snap-2379142480402238200-1-5183f5e9-7516-4ee8-a454-9c6263b7e624.avro",
"schema-id" : 0
} ],
"snapshot-log" : [ {
"timestamp-ms" : 1697784686845,
"snapshot-id" : 2379142480402238200
} ],
"metadata-log" : [ {
"timestamp-ms" : 1697784337831,
"metadata-file" : "hdfs://HDFS8000006/usr/hive/warehouse/iceberg_test.db/test3/metadata/00000-3e5e7244-e7b0-43f4-a5e2-09f166cb0427.metadata.json"
} ]
}
|
|
4、下载hdfs文件到本地
hadoop fs -get /usr/hive/warehouse/iceberg_test.db/test3/metadata/5183f5e9-7516-4ee8-a454-9c6263b7e624-m0.avro ~/wangshida/iceberg
hadoop fs -get /usr/hive/warehouse/iceberg_test.db/test3/metadata/snap-2379142480402238200-1-5183f5e9-7516-4ee8-a454-9c6263b7e624.avro ~/wangshida/iceberg
hadoop fs -get /usr/hive/warehouse/iceberg_test.db/test3/data/00000-0-d5a9981c-8476-4505-aa83-c9983ba467ef-00001.parquet ~/wangshida/iceberg
5、查看avro文件内容,需要用单独的jar包查看,所以先下载到本地查看
java -jar ./avro-tools-1.8.1.jar tojson ./iceberg/snap-2379142480402238200-1-5183f5e9-7516-4ee8-a454-9c6263b7e624.avro | less
{
"manifest_path": "hdfs://HDFS8000006/usr/hive/warehouse/iceberg_test.db/test3/metadata/5183f5e9-7516-4ee8-a454-9c6263b7e624-m0.avro",
"manifest_length": 5799,
"partition_spec_id": 0,
"added_snapshot_id": {
"long": 2379142480402238200
},
"added_data_files_count": {
"int": 1
},
"existing_data_files_count": {
"int": 0
},
"deleted_data_files_count": {
"int": 0
},
"partitions": {
"array": []
},
"added_rows_count": {
"long": 1
},
"existing_rows_count": {
"long": 0
},
"deleted_rows_count": {
"long": 0
}
}java -jar ./avro-tools-1.8.1.jar tojson ./iceberg/5183f5e9-7516-4ee8-a454-9c6263b7e624-m0.avro | less
{
"status": 1,
"snapshot_id": {
"long": 2379142480402238000
},
"data_file": {
"file_path": "hdfs://HDFS8000006/usr/hive/warehouse/iceberg_test.db/test3/data/00000-0-d5a9981c-8476-4505-aa83-c9983ba467ef-00001.parquet",
"file_format": "PARQUET",
"partition": {},
"record_count": 1,
"file_size_in_bytes": 656,
"block_size_in_bytes": 67108864,
"column_sizes": {
"array": [
{
"key": 1,
"value": 47
},
{
"key": 2,
"value": 52
}
]
},
"value_counts": {
"array": [
{
"key": 1,
"value": 1
},
{
"key": 2,
"value": 1
}
]
},
"null_value_counts": {
"array": [
{
"key": 1,
"value": 0
},
{
"key": 2,
"value": 0
}
]
},
"nan_value_counts": {
"array": []
},
"lower_bounds": {
"array": [
{
"key": 1,
"value": "\u0001\u0000\u0000\u0000"
},
{
"key": 2,
"value": "code1"
}
]
},
"upper_bounds": {
"array": [
{
"key": 1,
"value": "\u0001\u0000\u0000\u0000"
},
{
"key": 2,
"value": "code1"
}
]
},
"key_metadata": null,
"split_offsets": {
"array": [
4
]
},
"sort_order_id": {
"int": 0
}
}
}6、查看parquet数据文件-hadoop用户。因版本兼容和环境问题费时较多
下载工具包:https://repo1.maven.org/maven2/org/apache/parquet/parquet-tools/1.11.0/
(1)查看数据
查看前几行数据
hadoop jar ./parquet-tools-1.11.0.jar head -n 10 /usr/hive/warehouse/iceberg_test.db/test3/data/00000-0-d5a9981c-8476-4505-aa83-c9983ba467ef-00001.parquet
查看所有数据
hadoop jar ./parquet-tools-1.11.0.jar cat /usr/hive/warehouse/iceberg_test.db/test3/data/00000-0-d5a9981c-8476-4505-aa83-c9983ba467ef-00001.parquet
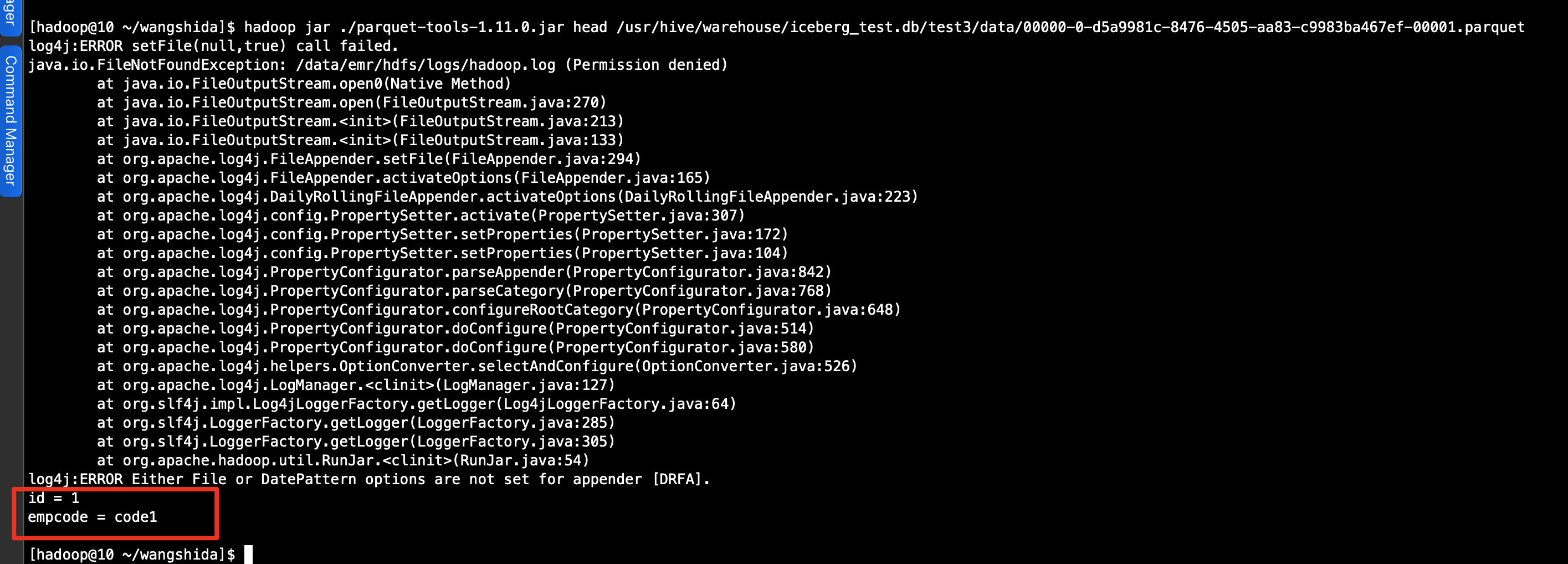
(2)查看元数据
hadoop jar ./parquet-tools-1.11.0.jar schema /usr/hive/warehouse/iceberg_test.db/test3/data/00000-0-d5a9981c-8476-4505-aa83-c9983ba467ef-00001.parquet
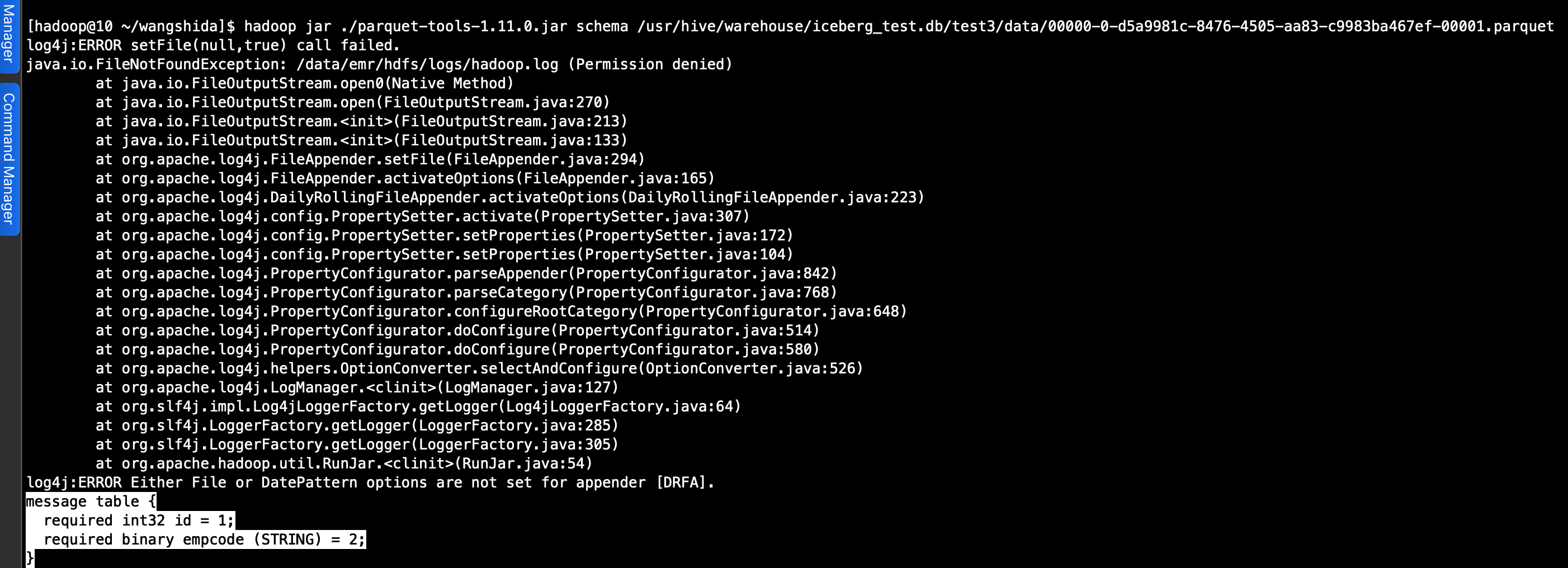
(3)查看meta信息
hadoop jar ./parquet-tools-1.11.0.jar meta /usr/hive/warehouse/iceberg_test.db/test3/data/00000-0-d5a9981c-8476-4505-aa83-c9983ba467ef-00001.parquet

7、通过sql查看元数据信息
(1)查看表快照信息
select * from spark_catalog.data_lake_ods.dws_service_subclazz_lesson_user_learn_stat_rt_v2.snapshots;
数据样例:
2023-12-04 16:59:54.979 4270722947875310895 4387207514912842768 overwrite snap-4270722947875310895-1-886c8c53-4409-47c6-ac93-a107280ffb59.avro {"added-data-files":"16","added-delete-files":"16","added-equality-delete-files":"16","added-equality-deletes":"22754348","added-files-size":"871385292","added-records":"22754348","changed-partition-count":"1","flink.job-id":"000000001de734af0000000000000000","flink.max-committed-checkpoint-id":"2","flink.operator-id":"e883208d19e3c34f8aaf2a3168a63337","total-data-files":"32","total-delete-files":"32","total-equality-deletes":"45471042","total-files-size":"1738325852","total-position-deletes":"0","total-records":"45471042"}
(2)查询表历史信息
select * from spark_catalog.data_lake_ods.test.history;
数据样例:
2023-12-04 16:59:54.979 4270722947875310895 4387207514912842768 true
(3)查询表data file文件列表
select * from spark_catalog.data_lake_ods.test.files ;
数据样例:
2 00002-0-09e082bc-4d7e-4f52-94c9-67e672e5c135-00002.parquet PARQUET 0 1419808 19356556 {1:7902810,2:2824871,4:8620639} {1:1419808,2:1419808,4:1419808} {1:0,2:0,4:0} {} {1:,2:,4:-?=-?=-?=b}} {1:-?=-?=T-?=G-?=,2:X-?=-?=-?=W,4:-?=c-?=-?=v} NULL [4] [1,2,4] 0 {"clazz_lesson_number":{"column_size":8620639,"value_count":1419808,"null_value_count":0,"nan_value_count":null,"lower_bound":1263763655281666,"upper_bound":393727528547897347},"clazz_number":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"companion_learn_duration":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"companion_lesson_length":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"is_black_user":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"is_combine_valid_learn_user":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"is_live_attend_user":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"is_should_attend_user":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"is_valid_learn":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"is_valid_live_learn":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"learn_combine_duration":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"learn_duration":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"lesson_length":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"lesson_live_length":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"lesson_live_property":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"lesson_standard_length":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"lesson_video_length":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"lesson_video_property":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"live_learn_duration":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null},"subclazz_number":{"column_size":2824871,"value_count":1419808,"null_value_count":0,"nan_value_count":null,"lower_bound":0,"upper_bound":24696091250786816},"user_number":{"column_size":7902810,"value_count":1419808,"null_value_count":0,"nan_value_count":null,"lower_bound":0,"upper_bound":247697329422028},"video_learn_duration":{"column_size":null,"value_count":null,"null_value_count":null,"nan_value_count":null,"lower_bound":null,"upper_bound":null}}
(4)查询表manifests信息
select * from spark_catalog.data_lake_ods.dws_service_subclazz_lesson_user_learn_stat_rt_v2.manifests ;
数据样例:
1 9462 0 4270722947875310895 0 0 0 16 0 0 []