一、概述
Elasticsearch-Cerebro(也称为 Cerebro)是一个针对 Elasticsearch 集群的开源管理和监控工具。它提供了一个直观的Web界面,允许您轻松地查看、管理和监控 Elasticsearch 集群。以下是 Elasticsearch-Cerebro 的主要特点和概述:
-
可视化监控:
Cerebro提供了直观的可视化界面,让您能够实时监控 Elasticsearch 集群的性能和状态。您可以查看索引、节点、分片等信息,以便快速识别潜在问题。 -
集群管理:
Cerebro允许您执行集群管理任务,如创建、删除索引,分配和迁移分片,设置索引别名,进行快照和还原等。这使得管理Elasticsearch集群变得更加容易。 -
搜索和过滤:
Cerebro提供高级搜索和过滤功能,以帮助您查找和定位特定索引或节点。这对于大规模集群和多索引环境非常有用。 -
集成认证和授权:
Cerebro支持认证和授权机制,以确保只有经过授权的用户能够访问集群数据。这有助于提高集群的安全性。 -
轻量级部署:
Cerebro是一个轻量级应用程序,可以独立运行,而不需要大型的依赖项。您可以将它部署在单独的服务器上,与Elasticsearch集群分开。 -
多集群支持:
Cerebro允许管理多个Elasticsearch集群。这对于管理多个开发、测试和生产环境的集群非常有用。 -
RESTful API 支持:
Cerebro提供了RESTful API,允许您通过API执行操作,这对自动化任务和集成到其他工具中很有用。 -
开源和活跃的社区:
Cerebro是一个开源项目,具有活跃的社区支持,可以根据需要进行扩展和自定义。
总之,Elasticsearch-Cerebro 是一个强大的 Elasticsearch 管理和监控工具,通过直观的Web界面提供了丰富的功能,使您能够更轻松地管理和监控 Elasticsearch 集群。这对于维护和管理大规模、复杂的 Elasticsearch 环境非常有帮助。
关于 Elasticsearch-Cerebro 物理部署和详细使用可以参考我这篇文章:Elasticsearch 可视化集群工具 Cerebro
二、开始编排部署 Elasticsearch-Cerebro
1)部署 docker
# 安装yum-config-manager配置工具
yum -y install yum-utils
# 建议使用阿里云yum源:(推荐)
#yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce版本
yum install -y docker-ce
# 启动并开机启动
systemctl enable --now docker
docker --version
2)部署 docker-compose
curl -SL https://github.com/docker/compose/releases/download/v2.16.0/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
docker-compose --version
3)创建网络
# 创建
docker network create bigdata
# 查看
docker network ls
4)构建镜像
这里直接用现成的镜像,不再重复造轮子了。
GitHub地址:https://github.com/lmenezes/cerebro.git
docker pull lmenezes/cerebro:0.9.4
docker tag lmenezes/cerebro::0.9.4 registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/es_cerebro:0.9.4
docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/es_cerebro:0.9.4
5)编排 docker-compose.yaml 部署
这里提前指定一套 ES,也可以指定多套(如果也是docker-compose部署ES,必须在同一个network下,要不然通过主机名找不到解析。),ES部署可以参考我以下几篇文章:
#docker-compose.yaml
version: '3'
services:
cerebro:
#服务的名称,可自定义; 不是容器名称
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/es_cerebro:0.9.4 # 指定容器的镜像文件
container_name: cerebro # 这是容器的名称
hostname: cerebro
ports:
# 配置容器与宿主机的端口,镜像里默认启动的服务端口是9000
- "1234:1234"
command:
- -Dhttp.port=1234
- -Dhttp.address=0.0.0.0
# 指定 ES 连接地址
- -Dhosts.0.host=http://node-1:9200
networks:
- bigdata
# 连接外部网络
networks:
bigdata:
external: true
6)测试验证
web 地址:http://ip:9000
登录页面,选择配置好的ES地址登录或者填入其它ES地址登录:
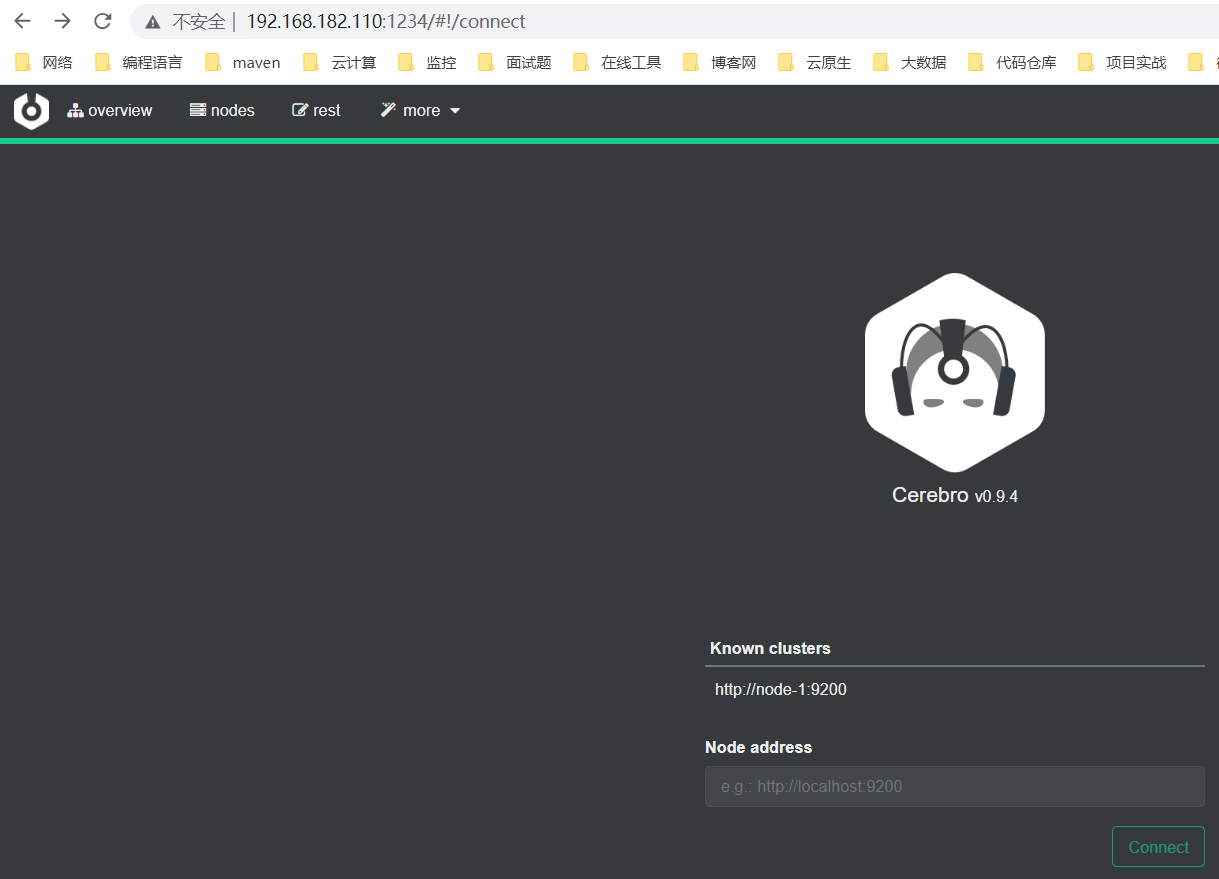
管理页面:
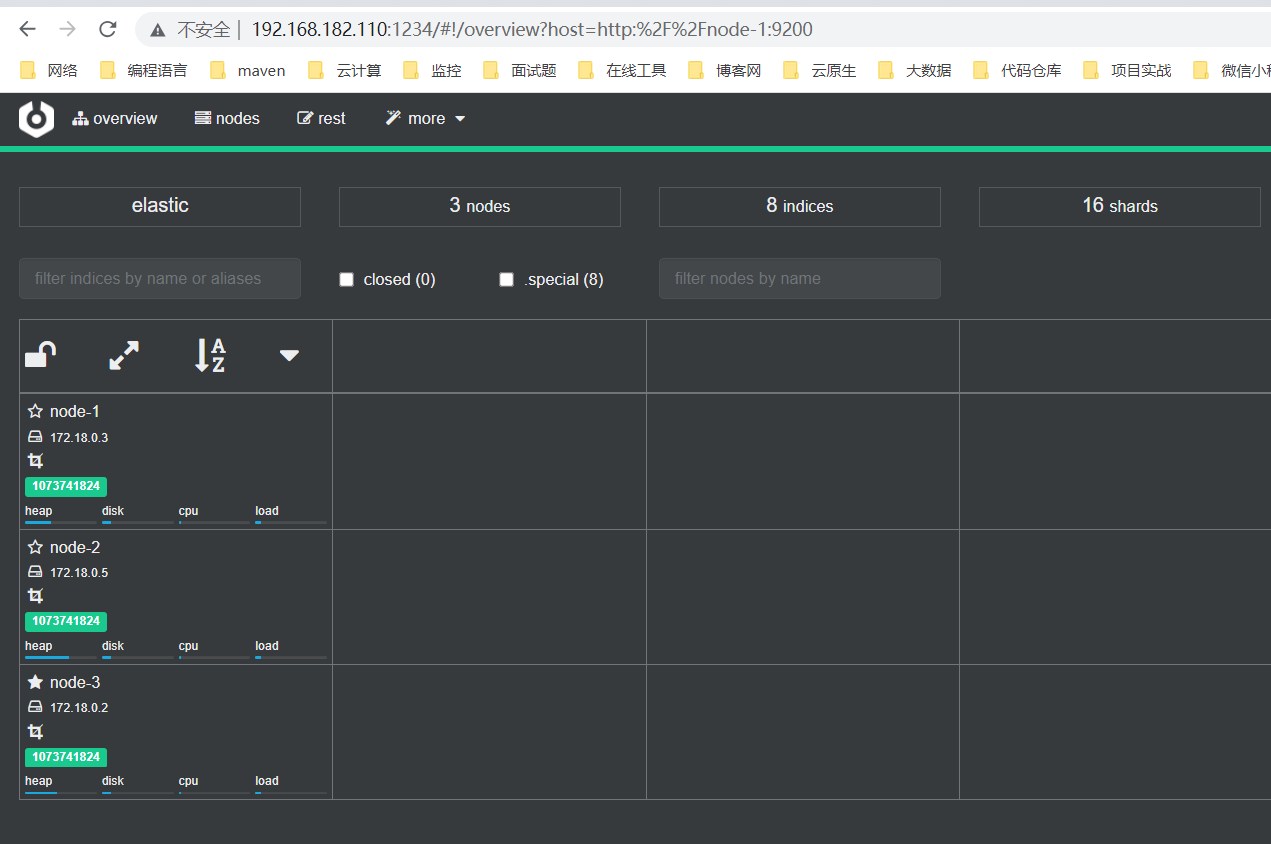
这上面管理界面的介绍和使用,可以参考我之前的文章:Elasticsearch 可视化集群工具 Cerebro,这里就不重复介绍了。
通过 docker-compose 快速部署 Elasticsearch-Cerebro 保姆级教程就先到这里了,有任何疑问也可关注我公众号:大数据与云原生技术分享,进行技术交流,如本篇文章对您有所帮助,麻烦帮忙一键三连(点赞、转发、收藏)~

- Elasticsearch-Cerebro docker-compose Elasticsearch 保姆 composeelasticsearch-cerebro docker-compose elasticsearch docker-compose保姆compose教程 docker-compose保姆compose rancher 中间件docker-compose保姆compose dolphinscheduler docker-compose保姆compose docker-compose保姆compose azkaban docker-compose保姆starrocks compose docker-compose clickhouse保姆compose 集群docker-compose elasticsearch logstash 集群docker-compose elasticsearch compose