近些年来人脸三维重建的发展主要围绕数据表示来进行,从一开始的显式表示到探索线性参数化表示,到后来非线形参数化表示和神经场表示,表示能力越来越强。此外,还有些方法结合了参数化模型表示和GAN等生成模型,以优化参数化模型对细节的缺失。
从0开始的三维人脸重建入门 (三)
NPMs (NPMs: Neural Parametric Models for 3D Deformable Shapes)
这一篇文章是人体重建的方法,写在这里是为了引出下一篇人脸重建的算法。上面我们研究了NeRF利用体渲染方法对场景使用神经网络进行隐式表示,这篇文章是另一种用神经网络对3D场景的隐式表示的探索,特别的,用在人体重建领域。
SDF:Signed Distance Fields,描述的是任意点到物体表面的符号距离,\(S D F(\boldsymbol{x})=s: \boldsymbol{x} \in \mathbb{R}^3, s \in \mathbb{R}\),即通常给定一个输入点,将物体外的点到物体表面的距离看作正数,物体内的点到物体表面的距离看作负数,前面有工作(DeepSDF)用类似autodecoder的方式训练得到这样一个网络。该隐式表示可以通过marching cube算法转化为mesh,即通过等值面和每个六面体的面的关系确定三角面的顶点,组成mesh。

不同于NeRF对一个场景的表示,DeepSDF对每个id的人以输入code作为condition进行表示:
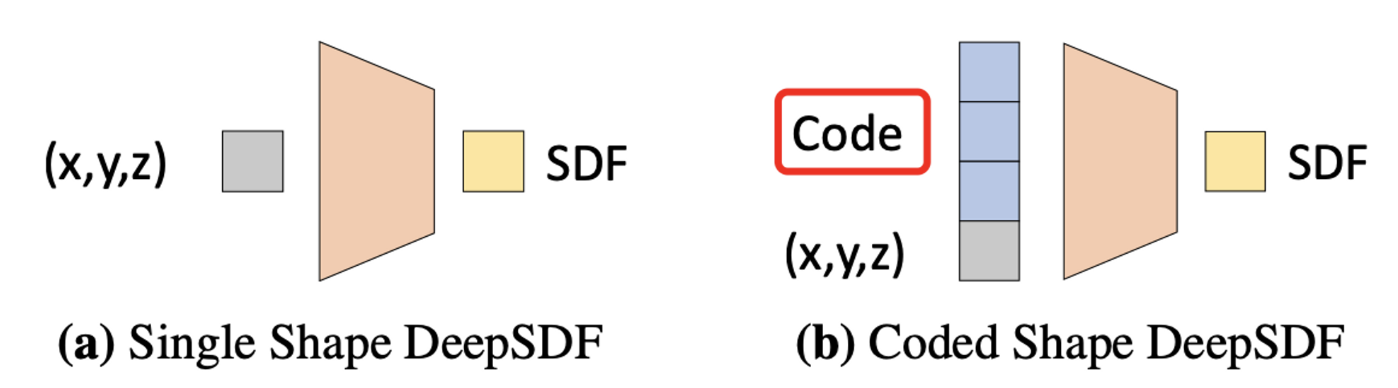
DeepSDF对图中code的优化蛮有意思,即交替优化code和解码网络的权重:
先随机初始化code,优化网络的权重:
再固定网络的权重,去优化code:
为啥这样make sense呢?在优化网络权重的阶段,由于code是gaussian随机的,相当于是噪声,相当于是没有提供有用的信息,网络在优化loss的时候会尽可能利用输入的有用信息,即坐标,所以权重优化的时候code对loss的贡献是很小的;而在权重学习好了之后,固定权重去优化输入z也是的确合理的做法。
回到NPM,NPM用的就是上面的方法来训练identity shape,不同人用不同的shape code表示:
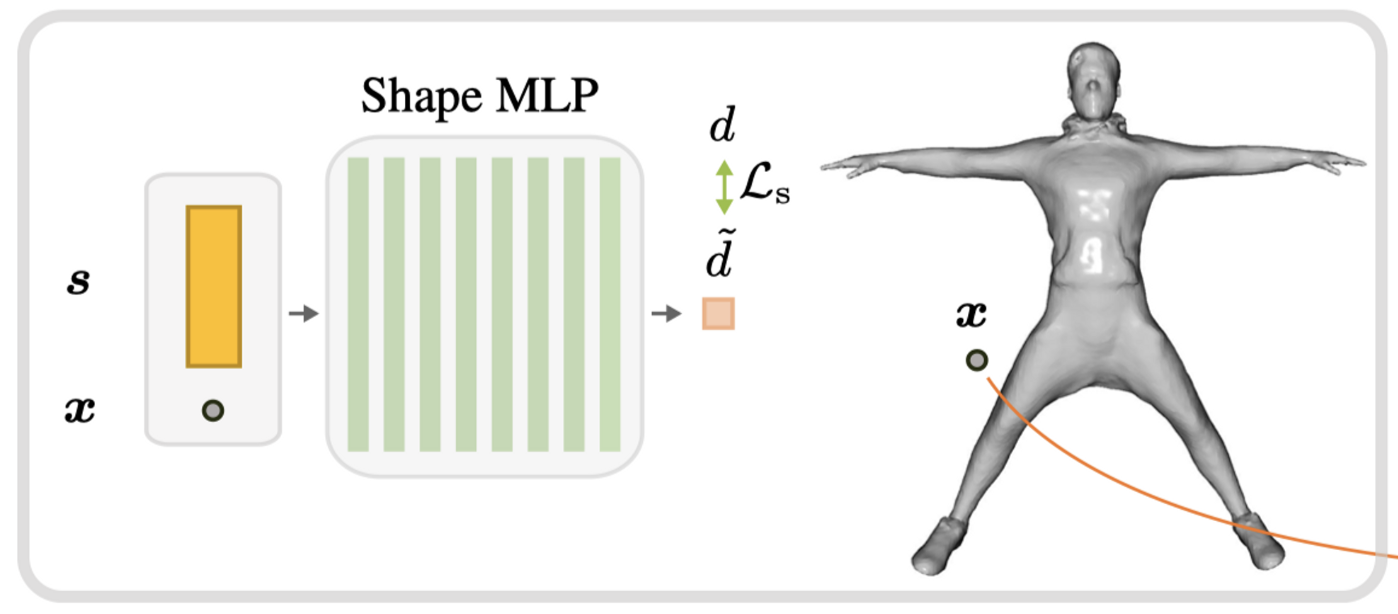
当这个网络和shape code训练完毕,shape code就有了意义,用来训练pose code和对应的pose网络:
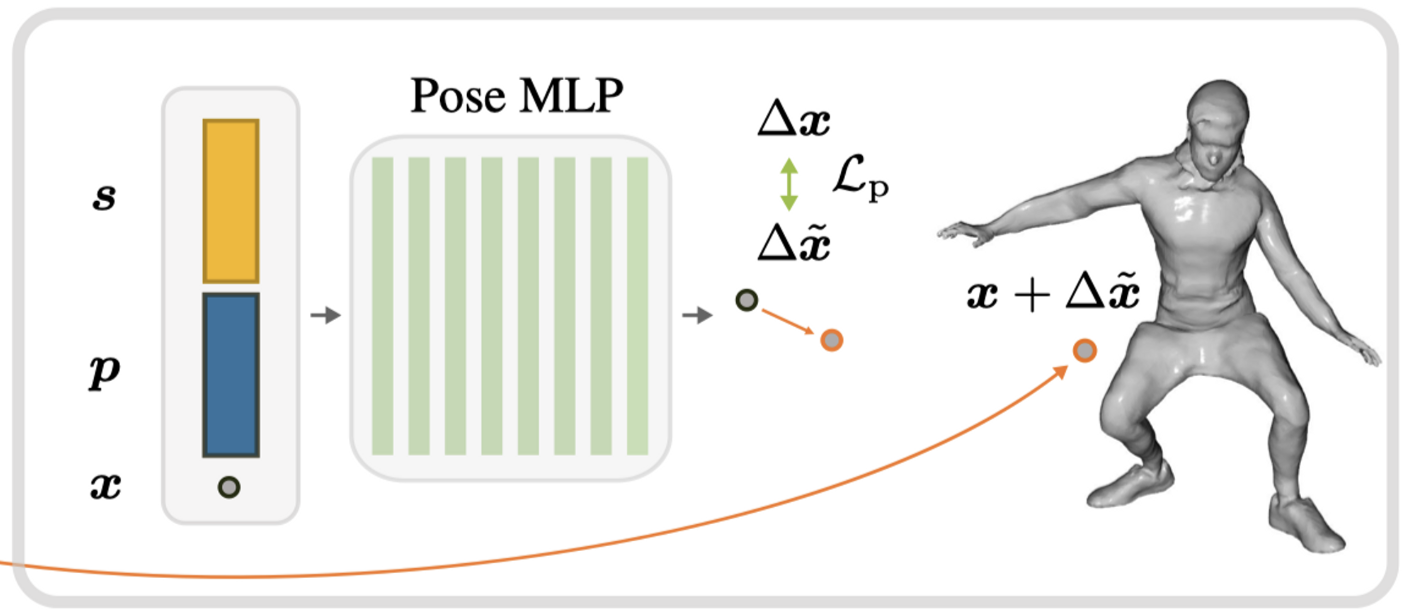
这里pose网络回归shape点到pose点的offset,pose code的训练方式和shape code如出一辙。
至此实现对不同人体不同pose的神经隐式表示。
Learning Neural Parametric Head Models
有了NPM的基础,同样可以实现对人脸的神经隐式建模,即考虑identity shape和expression shape,训练方式和NPM也是一样的。
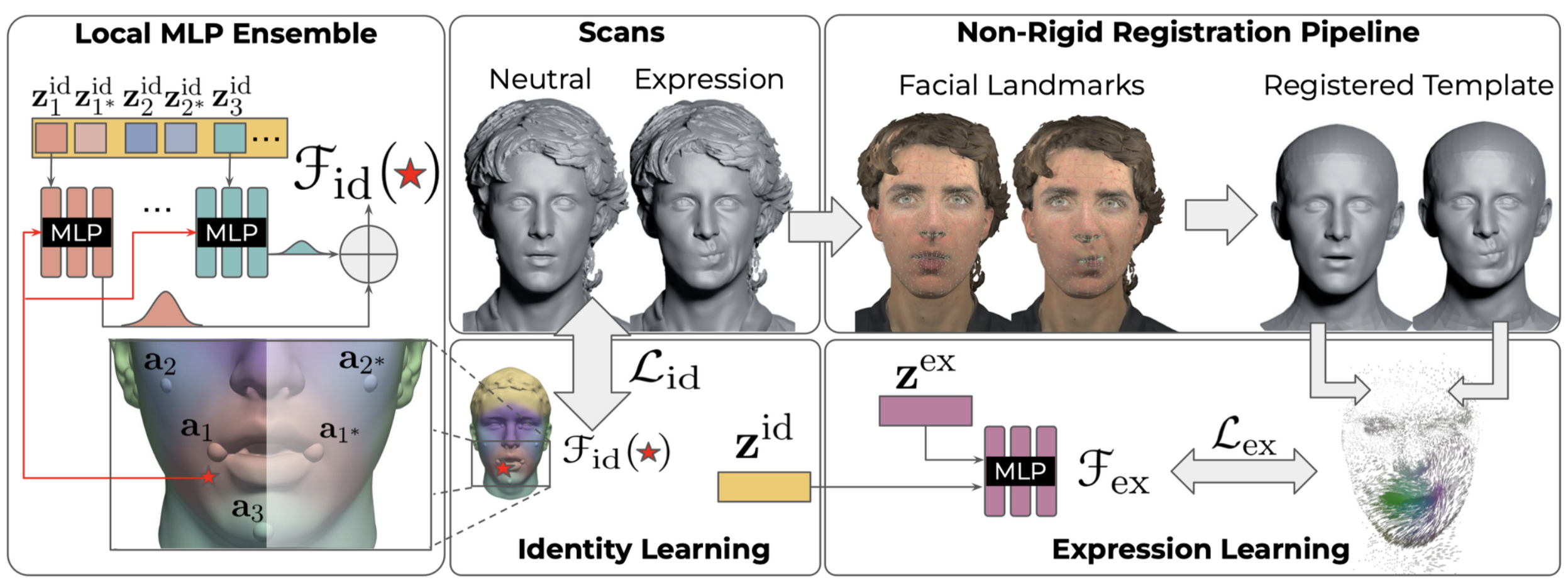
不同于人体对identity shape code的描述,针对人脸选了一些patch,不同patch用不同的identity shape code而非共用。
identity训练完之后,训练expression code。
Efficient Geometry-aware 3D Generative Adversarial Networks
文章提出tri-plane的隐式神经表示,相比于NeRF的表示,tri-plane的表示由于使用的网络较小,所以速度上要更快;而相比于显式的voxel表示,其可以表示的分辨率更高,而voxel显式表示如果要表示更高的分辨率,就需要更多的内存开销。
如下图:
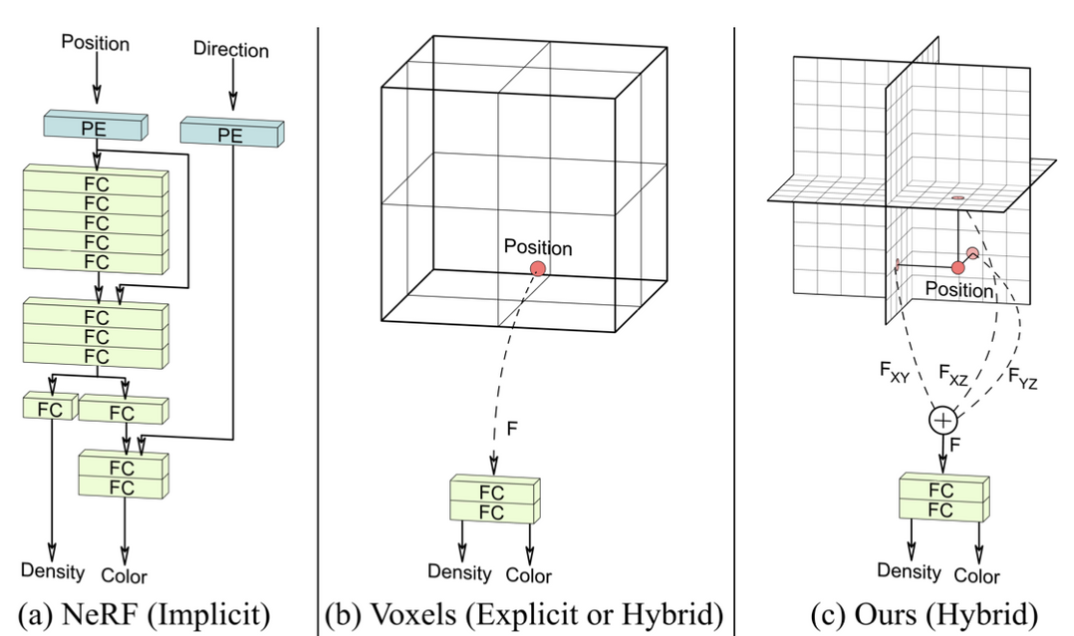
左边对应的是NeRF表示,在query时由于网络权重比较多,会相对较慢;中间时voxel-grid表示,相比于NeRF,提前申请好3D空间存储特征,如果是voxel混合表示则一般需要接个全连阶层将3D特征转化为密度和颜色;tri-plane相比于voxel表示,将该点位的特征转化为了对应三个平面的投影特征之和,因此存储时只需要存储三个平面的特征即可,而voxel则需要存储整个空间的特征。总之,tri-plane的方法以空间换时间提前存储局部特征,改进了NeRF查询速度上的不足,又以投影和表示空间中的点,改进了显式表示下空间占用过多的问题,因此tri-plane是一种混合表示,既有空间位置的显示表示,又将表示下的feature经过fc层将隐式的feature转化为显式的密度和颜色。
一个比较有疑问的地方是,NeRF通过将direction作为输入,确保color是在不同观测方向时不同;而tri-plane表示从目前看并不能表示出不同观测方向观测颜色的不同。但是看了后面的网络结构,就知道在生成器生成tri-plane表示的时候其实已经将相机的参数作为输入了,因此tri-plane表示应该是一种pose-dependent的表示,在推理的时候如果要移动相机位置,需要重新用生成器生成tri-plane表示,所以其实理论上如果仅仅这样,tri-plane的表示缺点也是蛮明显的,这样每次移动一下相机都要重建推理一次。而文章在之后解决了这一问题。
不仅于此,本文的另一个贡献是希望利用GAN的训练策略,生成任意的三维场景。相比于NeRF的“overfitting”单一场景,本文通过对latent code的编辑实现3D场景的改变。
其整体的结构大致如下:
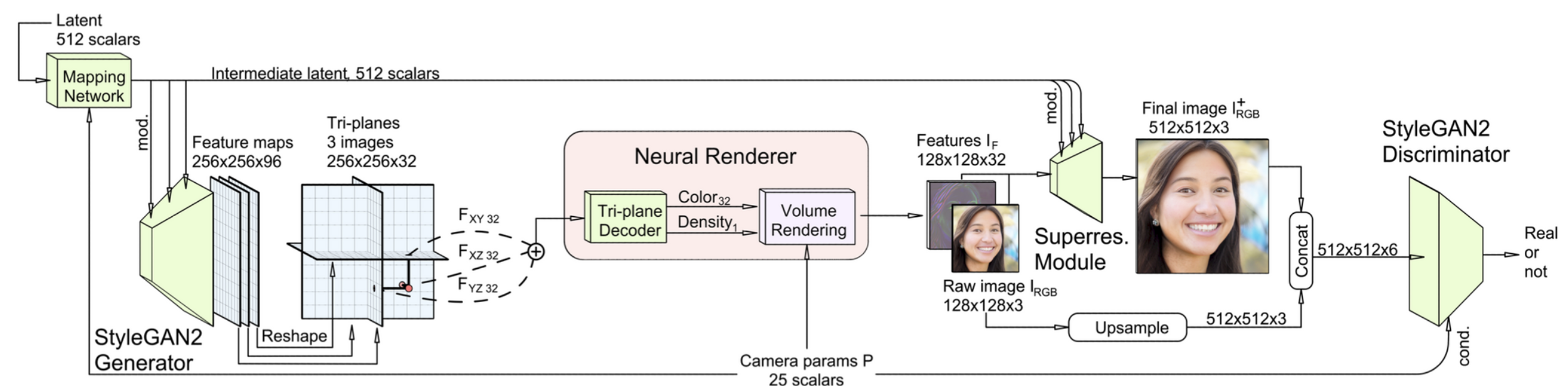
生成器的结构是StyleGAN2的结构,其输入有两个,一个是相机参数P,一个是latent code,这俩输入经过mapping全连接作为生成器的输入,经过生成器得到tri-plane表示,之后neural rendering渲染成该视角下的feature,该feature是32维的,相比于传统渲染成3通道的图像,由于后面要经过超分模块,所以通道数的增加其实是增强了表示能力的,因此就没有选用3通道,也自然没有设计渲染图和原图的损失,而是在超分后计算损失。
上面提到要解决生成器pose-dependent的问题,即如果我们给定一个camera pose,生成tri-plane,而我们在渲染时如果采用不同的camera pose,就会出现“billboard”效应:

这正是由于tri-plane时pose-dependent的,在不同pose下显然就有问题,因为此时的tri-plane就表示不了其他pose的情况,渲染的结果就除了生成器的pose,其他pose无法保证。文章的解决办法是,在训练时生成器的pose输入是在数据集中随机采样,而渲染的pose是该图片的camera pose,这样学习到的tri-plane就不是pose-dependent,而是pose-distribution-dependent,因为对于输入提供的信息是从数据集中随机采样的,而且同一图片在训练时生成器会有不同的pose,因此学习到的信息就是依赖于数据集的pose分布,而非图片的pose。
那之前我们说过NeRF的pose作为观测方向输入,可以描述不同观测方向颜色不同,而tri-plane其实没法描述这种情况的。超分模块接收了camera pose渲染的结果作为输入,一定程度上也能隐式的告诉超分camera pose的信息吧,因此超分模块可能是可以描述观测方向不同导致的光影变化的。
再者,从重建的一些结果看,似乎也没有光影变化较大的重建结果,可能限制了一些场景,在人脸这种简单场景下还是可以的。
最后,判别器判别是否“成对”,真实数据concat自身,生成数据concat真实数据。需要注意的是,判别器condition了camera pose,这是因为不condition camera pose会出现一种“collapse”,即容易导致生成的3D结构只是一层一层的“纹理”,这是因为判别器没有捕捉到camera pose的信息,因为判别器的输入就只有图像,只能通过渲染后的2D纹理判别,因此前面的网络更倾向于利用纹理来更新权重,以防止被判别器“看破”,而加了camera pose作为condition,判别器则会有一条明显通路判别不同camera pose的渲染图是不一致的,因此前面的权重在反向传播时会一定程度上强化camera pose的影响,从而编码更多信息。

上图第二行是不加camera pose condition的结果,其他则是加了camera pose condition后对camera pose扰动后的结果,因此上图证明了加了camera pose condition后不会出现“collapse”,并且对不精确的camera pose(即有一定扰动)重建效果也不太会受到太大影响,即有一定鲁棒性。