Kaggle:Otto Group Classification
数据处理
导入相应的包之后,从csv文件中读取数据,指定id列为index列。本身id列也不携带预测信息。同时将训练数据和测试数据拼接在一起。
train_data = pd.read_csv("dataset/train.csv", index_col="id")
test_data = pd.read_csv("dataset/test.csv", index_col="id")
all_features = pd.concat((train_data.iloc[:, :-1], test_data))
提供的训练数据是由93列数值特征和1列类别。由于训练数据是按照类比顺序排列的,所以在进行其他操作前先将其打乱。
首先对所有93列特征进行零均值和单位方差的标准化处理。
train_data = train_data.sample(frac=1) # 在划分训练集和验证集之前打乱数据
all_features = all_features.apply(lambda x: (x - x.mean()) / (x.std()))
然后将数据对应的类别转换成one-hot向量,使用pd.get_dummies()函数可以轻松做到。同时原本这里数据的类别叶转换成了列名,方便后续构造用以提交的数据表。
train_label = pd.get_dummies(train_data["target"])
print(train_label.head(4))
训练数据有6w条左右,所以这里我们可以粗滤得将前5000条数据划分为验证集,剩下的数据作为训练集。
num_train = train_data.shape[0]
valid_features = torch.tensor(all_features[:5000].values, dtype=torch.float32)
train_features = torch.tensor(all_features[5000:num_train].values, dtype=torch.float32)
valid_labels = torch.tensor(train_label[:5000].values, dtype=torch.float32)
train_labels = torch.tensor(train_label[5000:num_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[num_train:].values, dtype=torch.float32)
使用Dataloader进行分批处理
train_dataset = torch.utils.data.TensorDataset(train_features, train_labels)
loader = DataLoader(dataset=train_dataset, batch_size=128, shuffle=True)
定义模型、损失和优化
我们这里要解决的问题是一个多分类问题,所以是以softmax函数作为模型的基本。通常情况下,使用CrossEntropyLoss()内置了softmax操作。
loss = nn.CrossEntropyLoss(reduction='mean').to(device)
定义一个简单的线性模型作为baseline,然后定义一个复杂的模型。这个模型由四个线性层组成,前面三层将把特征从93扩充到512再到256,最后一层则作为softmax的前置,输出是个类别,由于隐藏层的权重比较多,所以加入了dropout来缓解过拟合的问题。
def base_net():
net = nn.Sequential(
nn.Linear(93, 9)
)
return net
class OttoNet(nn.Module):
def __init__(self):
super(OttoNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(93, 512), nn.ReLU(),
nn.Dropout(0.2))
self.layer2 = nn.Sequential(
nn.Linear(512, 512), nn.ReLU(),
nn.Dropout(0.2))
self.layer3 = nn.Sequential(
nn.Linear(512, 256), nn.ReLU(),
nn.Dropout(0.2))
self.layer4 = nn.Linear(256, 9)
def forward(self, X):
out = self.layer1(X)
out = self.layer2(out)
out = self.layer3(out)
return self.layer4(out)
训练和预测
通过迭代构建训练函数,每一代输出一次相关的训练信息。
def train(net, train_f, train_l, valid_f, valid_l, num_epochs, learning_rate, weight_decay):
train_ls, test_ls = [], []
valid_acc = 0
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9,weight_decay=weight_decay)
for epoch in range(num_epochs):
for X, y in loader:
X, y = X.to(device), y.to(device)
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(loss(net(train_f), train_l).item())
if valid_labels is not None:
net.eval()
with torch.no_grad():
valid_pred = net(valid_f)
test_ls.append(loss(valid_pred, valid_l).item())
_, pred = torch.max(valid_pred.data, dim=-1)
_, label = torch.max(valid_l.data, dim=-1)
valid_acc = (pred == label).sum().item() / 5000 * 100
#valid_acc = pred.shape/5000 * 100
print('[Epoch %d], train_loss=%.5f, valid_loss=%.5f, valid_acc=%3f %%'% (epoch + 1,train_ls[-1], test_ls[-1],valid_acc))
return train_ls, test_ls
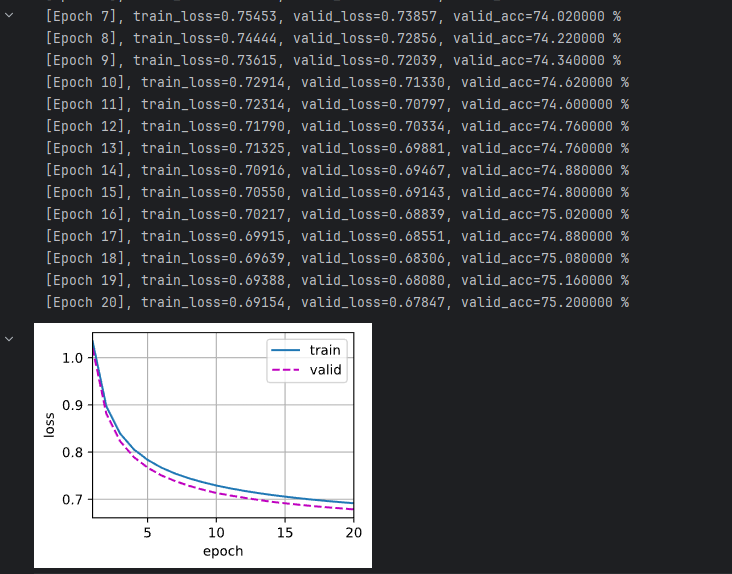
baseline的预测结果
num_epochs, lr, weight_decay = 20, 0.001, 0
net = base_net().to(device)
train_ls, valid_ls = train(net, train_features.to(device), train_labels.to(device), valid_features.to(device), valid_labels.to(device),
num_epochs, lr, weight_decay)
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls], xlabel='epoch', ylabel='loss', xlim=[1, num_epochs], legend=['train', 'valid'])
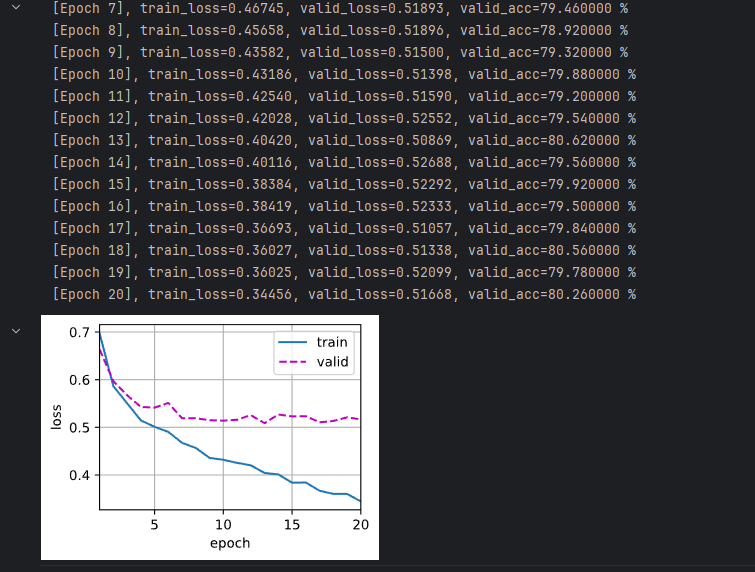
复杂模型的预测结果,可以看到还是有过拟合的问题存在。
测试
kaggle要提交的是每个样本对应各个类别的概率结果,所以使用模型进行预测后要加上softmax()。
提交kaggle要多看官网的要求!浪费很多时间在这里。
输出预测结果并提交,最终kaggle得分在0.5左右。
test_pred = nn.functional.softmax(net(test_features.to(device)))
test_pred = test_pred.cpu().detach().numpy()
print(test_pred.shape)
submission = pd.DataFrame(test_pred)
submission.index = submission.index + 1
submission.columns = train_label.columns
submission.to_csv('submission_.csv',index=True,index_label="id")
总结:
这个题目主要是一个softmax多分类的问题,用pytorch实现起来很简单,重点还是在对数据的处理上。就是要注意在划分验证机和训练集之前要打乱数据,其他的也都和前面做的房价预测相似。最后用来提交的是对样本每个类别的概率,而不是提交预测的是哪个类。学到了pandas中对表格的一些手段。