一、选题背景
1.背景
自2020年初起,新冠病毒(COVID-19)迅速传播并导致全球大流行。该病毒最初在中国武汉市被确认,并随后迅速传播到全球各地。由于其高度传染性和致命性,许多国家不得不采取严格的措施来控制其传播。
在此期间,许多科学家和医疗专家投入了大量时间和资源来了解这种新的冠状病毒,如何预防和治疗它。研究人员在2020年至2022年期间进行了大量的研究,以了解病毒的传播方式、病毒结构、感染机制和治疗方法。
一些研究显示,COVID-19的传播途径包括空气传播、飞沫传播和接触传播。此外,研究人员还分析了COVID-19的基因组结构和变异情况,以更好地理解病毒的进化和传播。
随着研究的深入,各种治疗方法也陆续出现。例如,研究人员对药物进行试验,以确定哪些药物可以有效治疗COVID-19的症状。此外,COVID-19疫苗的研究也进展迅速,许多疫苗已被批准使用并分发给全球各地的人们。
总之,2020年至2022年是新冠疫情的关键时期,科学家和医疗专家们在这段时间内进行了大量的研究来帮助人们更好地了解这种疾病,并提供有效的治疗方法。
2.预期目标
- 分析数据:收集并整理新冠病例、死亡率、康复人数等数据,并使用Python编程语言进行数据分析。这包括对数据进行清洗、可视化、探索性分析和统计建模等。
- 疫情趋势预测:使用Python中的机器学习算法,如回归模型或时间序列模型进行预测。例如,根据历史病例数据对未来一段时间内的感染率进行预测。
- 可视化展示:将分析结果以图表、地图等形式以更易理解的方式呈现出来,从而更直观地展示新冠疫情的发展趋势。
- 实时监测:定期更新数据并自动化脚本,以实现实时监测新的数据添加到系统中。
- 支持政策制定:利用数据分析的结果,为公众、卫生部门和政策制定者提供信息,以帮助他们更好地了解疫情,预测病例数量和推断政策措施的效果。
二、2020-2022新冠疫情大数据分析
1.课题名称
"COVID-19疫情趋势预测与数据探索:基于Python的全球大数据分析"
2.数据获取途径
本次实验使用的数据'COVID-19.csv'来源于Tableau的全球新冠肺炎疫情追踪工具,数据来源于JHU CSSE COVID-19 Data和《纽约时报》,源数据地址: https://data.world/covid-19-data-resource-hub/covid-19-case-counts/workspace/file?filename=COVID-19+Activity.csv
三、实验数据代码与展示
1.导入数据并查看行列数和前几行


2.查看每个字段的数据类型,并将‘日期’字段改成时间属性
3.数据分析:分别得到2022年北京和纽约每日的累计确诊病例

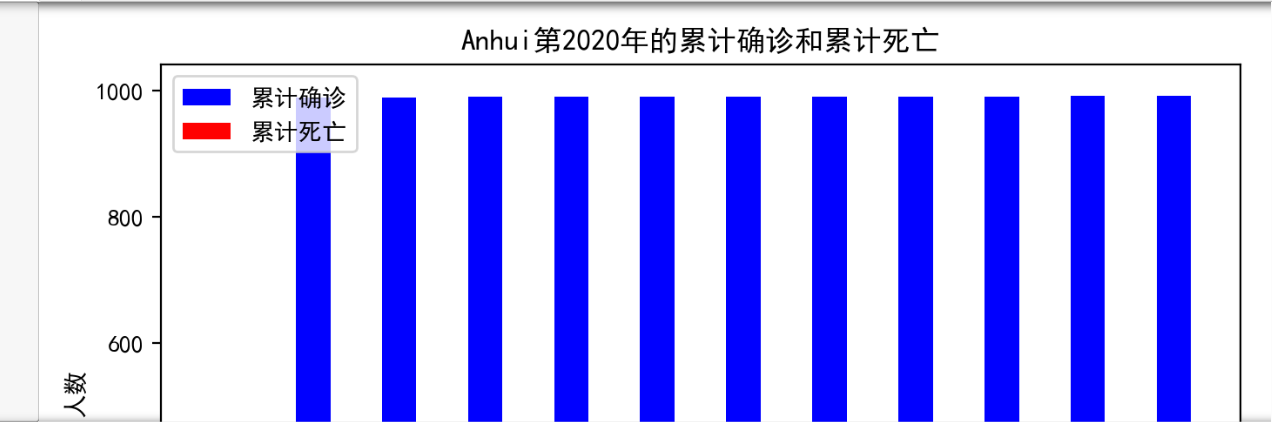
4.这里选取累计确诊病例和累计死亡病例了解一个地区的大致病情情况
5.选择最新数据中中国省份累计确诊人数中间10个[12:23]

6.中国大陆平均水平累计确诊省份比较图

7.比对上海和浙江的2021年每日确诊数量


8.各区域确诊人数情况分布图

四、完整程序代码
1 # 导入数据并查看行列数和前几行 2 import pandas as pd 3 df = pd.read_csv('COVID-19.csv',low_memory=False) 4 print(df.shape) 5 df 6 7 data = pd.read_csv(r"COVID-19.csv") 8 data.head() 9 10 # 查看每个字段的数据类型,并将‘日期’字段改成时间属性 11 df['日期'] = df['日期'].astype('datetime64') 12 df.info() 13 14 # 数据分析:分别得到2022年北京和纽约每日的累计确诊病例 15 data = df[(df['省份/州']=='Beijing')&(df['日期'].array.year==2022)] 16 data = data.sort_values(by='日期') 17 data 18 19 data2 = df[(df['省份/州']=='New York')&(df['日期'].array.year==2022)] 20 data2 = data2.groupby('日期')['累计确诊病例'].sum() 21 data2 22 23 # 绘制时间序列图 24 import plotly.graph_objects as go 25 26 fig = go.Figure(go.Scatter( 27 x=data['日期'], 28 y=data['累计确诊病例'], 29 name='Beijing', 30 marker_color = '#f57c00', 31 )) 32 33 fig.add_trace(go.Scatter( 34 x=data2.index, 35 y=data2.values, 36 name='New York', 37 yaxis='y2', 38 marker_color = '#00bcd4' 39 )) 40 41 fig.update_layout( 42 title='2022年北京和纽约累计确诊病例时间序列图', 43 yaxis_title='北京累计确诊数', 44 yaxis2=dict(side='right',overlaying='y',title='纽约累计确诊数') 45 ) 46 47 fig.show() 48 49 q1 = df.loc[(df['国家']=='China') & (df['省份/州']!='Hong Kong') & (df['省份/州']!='Unknown'),:] 50 51 q1 = q1.groupby(['省份/州'])['累计确诊病例'].max().reset_index() 52 53 import plotly.graph_objects as go 54 55 fig = go.Figure() 56 fig.add_trace(go.Bar(x = q1['省份/州'], y = q1['累计确诊病例'], 57 marker=dict(color = q1['累计确诊病例'], 58 colorscale='Bluered_r'))) 59 60 fig.add_annotation(x = list(q1['累计确诊病例']).index(min(list(q1['累计确诊病例']))), text="min") 61 fig.add_annotation(x = list(q1['累计确诊病例']).index(max(list(q1['累计确诊病例']))), text="max") 62 fig.update_layout( 63 title="截止2022年四月中国大陆各省份累计确诊病例", 64 xaxis_title="省份", 65 yaxis_title="累计确诊病例" 66 ) 67 fig.show() 68 69 import warnings 70 warnings.simplefilter(action="ignore") 71 72 import numpy as np 73 import pandas as pd 74 75 import matplotlib.pyplot as plt 76 import seaborn as sns 77 import squarify 78 import plotly 79 import plotly.io as pio 80 import plotly.express as px 81 import plotly.graph_objects as go 82 from plotly.subplots import make_subplots 83 84 plt.rcParams['font.sans-serif']=['SimHei'] 85 plt.rcParams['axes.unicode_minus'] = False 86 87 import re 88 89 data = pd.read_csv(r"COVID-19.csv") 90 data.head() 91 92 data = data.drop(data[data["每日新增确诊病例"]<0].index) 93 data = data.drop(data[data["每日新增死亡病例"]<0].index) 94 data = data.drop(data[data["区域"].isna()==True].index) 95 96 china_data = data[data["国家"]=="China"] 97 china_data["省份/州"].unique() 98 99 #堆积柱状图 100 #中国地区 101 # 这里选取累计确诊病例和累计死亡病例了解一个地区的大致病情情况 102 from collections import defaultdict 103 province = defaultdict(list) 104 day = ["01-31","02-29","03-31","04-30","05-31","06-30","07-31","08-31","09-30","10-31","11-30","12-31"] 105 for i in china_data["省份/州"].unique().tolist(): 106 da = china_data[china_data["省份/州"]==i] 107 da["日期"] = pd.to_datetime(da["日期"]) 108 da.set_index("日期",inplace=True) 109 da = da.sort_index(ascending=False) 110 for j in day: 111 da_2020 = da["2020-"+j] 112 # print(da_2020) 113 province[i].append([da_2020["累计确诊病例"].tolist()[0],da_2020["累计死亡病例"].tolist()[0]]) 114 print(province) 115 116 for i in province.keys(): 117 fig,ax = plt.subplots(figsize=(8,5),dpi=200) 118 label = [str(i) for i in range(1,13)] 119 value1_before = province[i] 120 value1 = [j[0] for j in value1_before] 121 value2 = [j[1] for j in value1_before] 122 width = .4 123 ax.bar(label, value1, width, label='累计确诊',color='blue') 124 ax.bar(label, value2, width, label='累计死亡',color='red') 125 ax.set_ylabel('人数') 126 ax.set_title(f'{i}第2020年的累计确诊和累计死亡') 127 ax.legend() 128 plt.show() 129 130 data4 = df.groupby(['省份/州'])[['累计确诊病例', '累计死亡病例']].max().reset_index() 131 132 data4['累计确诊病例水平'] = pd.qcut(data4['累计确诊病例'], 3, labels = range(1,4)) 133 134 fig = go.Figure(go.Scatter( 135 x=data4['累计确诊病例'], 136 y=data4['累计死亡病例'], 137 mode='markers', 138 marker_color=data4['累计确诊病例'], 139 text = data4['省份/州'], 140 hoverinfo='text', 141 )) 142 143 fig.update_layout( 144 title="2020.01-2022.04每日新增确诊病例及累计新增死亡病例散点图", 145 xaxis_title="每日新增确诊病例", 146 yaxis_title="每日新增死亡病例" 147 ) 148 fig.show() 149 150 #选择最新数据中中国省份累计确诊人数中间10个[12:23] 151 china_data = data[data["国家"]=="China"] 152 china_data = china_data.drop(columns=["地区编码"]) 153 #绘制各个省份的最新累计确诊人数对比 154 china_data["日期"] = pd.to_datetime(china_data["日期"]) 155 china_data.set_index("日期",inplace=True) 156 china_data = china_data.sort_index(ascending=False) 157 china_data 158 159 late_day_china_data = china_data["2022-04-29"] 160 print(late_day_china_data.shape) 161 late_day_china_data 162 163 value = dict(zip(late_day_china_data["省份/州"].tolist(),late_day_china_data["累计确诊病例"].tolist())) 164 after = dict(sorted(value.items(), key = lambda kv:(kv[1], kv[0]),reverse=True)[12:23]) 165 after 166 167 def max_shanqu(after): 168 ''' 169 param:获取最大值的位置 170 after为字典类型 171 return explode,x,labels 172 173 ''' 174 #获取位置 175 loca = list(after.values()).index(max(after.values())) 176 labels = list(after.keys()) 177 labels[loca] += "(Top Most)" 178 x = list(after.values()) 179 explode = [0]*len(labels) 180 explode[loca] = 0.1 181 explode = tuple(explode) 182 return explode,labels,x 183 184 e,l,x = max_shanqu(after) 185 e,l,x 186 187 plt.figure(figsize=(8,8)) 188 plt.pie(x=x, 189 labels=l, 190 explode = e, 191 autopct='%.2f%%', 192 #饼图中文本的属性 193 textprops={'color':'black',#文本颜色 194 'fontsize':10,#文本大小 195 'fontfamily':'Microsoft JhengHei',#设置微软雅黑字体 196 } 197 198 ) 199 plt.legend(title="10 province Pie", 200 loc="upper right", 201 fontsize=15, 202 bbox_to_anchor=(1, 0, 0.5, 1), 203 ncol=1,)#控制图例中按照两列显示,默认为一列显示 204 plt.title("中国大陆平均水平累计确诊省份比较图",fontsize=20) 205 plt.show() 206 #说明在中间省份的比例差不多,也就是说除了突发省份,大部分省份的防疫工作还不错 207 208 #比对上海和浙江的2021年每日确诊数量 209 Sh_data = china_data[china_data["省份/州"]=="Shanghai"]["2021"] 210 ZJ_data = china_data[china_data["省份/州"]=="Zhejiang"]["2021"] 211 fig,ax = plt.subplots() 212 213 n,bins_num,pat = ax.hist(Sh_data["每日新增确诊病例"],bins=10,alpha=0.8) 214 215 ax.plot(bins_num[:10],n,marker = 'o',color="yellowgreen",linestyle="--") 216 plt.title("上海2021年新增确诊人数") 217 plt.xlabel("人数") 218 plt.ylabel("频率") 219 220 221 fig,ax = plt.subplots() 222 223 n,bins_num,pat = ax.hist(ZJ_data["每日新增确诊病例"],bins=10,alpha=0.75) 224 225 ax.plot(bins_num[:10],n,marker = 'o',color="yellowgreen",linestyle="--") 226 plt.title("浙江2021年新增确诊人数") 227 plt.xlabel("人数") 228 plt.ylabel("频率") 229 230 q8 = df.loc[(df['数据来源'] == 'JHU CSSE Global Timeseries'),:] 231 q8_2 = q8.groupby(['数据来源', '区域', '国家'])['累计确诊病例'].max().reset_index() 232 q8_2 = q8_2.dropna() 233 q8_1 = q8_2.groupby(['数据来源', '区域'])['累计确诊病例'].sum().reset_index() 234 q8_1 = q8_1.dropna() 235 236 fig = go.Figure(go.Sunburst( 237 labels = q8_1['区域'].tolist() + q8_2['国家'].tolist(), 238 parents = q8_1['数据来源'].tolist() + q8_2['区域'].tolist(), 239 values = q8_1['累计确诊病例'].tolist() + q8_2['累计确诊病例'].tolist(), 240 branchvalues = 'total' 241 )) 242 243 fig.update_layout(margin = dict(t=0, l=0, r=0, b=0)) 244 fig.show() 245 246 data_region = data.copy() 247 data_region["日期"] = pd.to_datetime(data_region["日期"]) 248 data_region = data_region.set_index("日期") 249 data_region = data_region.sort_index(ascending=False) 250 # data_region 251 data_region_end = data_region["2022-04-29"] 252 # data_region_end 253 region = data_region_end["区域"].unique().tolist() 254 #得出区域中10个最高地区的(累计确诊病例/人口统计)进行求平均为区域的确证概率 255 before_data = {} 256 for i in region: 257 da = data_region_end[data_region_end["区域"]==i] 258 da["累计确诊率"] = da["累计确诊病例"]/da["人口统计"] 259 #在此基础上观察死亡率,这样保证了数据的一致性 260 da["累计死亡率"] = da["累计死亡病例"]/da["人口统计"] 261 da = da.sort_values("累计确诊率",ascending=False) 262 #取出前30 263 da_50 = da.iloc[0:50,:] 264 print(f"{i}的前30的平均确诊率为{da_50['累计确诊率'].mean()*100},平均死亡率为{da_50['累计死亡率'].mean()*100}") 265 before_data[i] = [round(da_50['累计确诊率'].mean()*100,3),round(da_50['累计死亡率'].mean()*100,3)] 266 267 before_data 268 269 [plt.cm.Spectral(before_data[i][1]) for i in before_data.keys()] 270 271 ## recovery_percent确诊率为大小,死亡率为颜色 272 name = before_data.keys() 273 recovery_percent = [before_data[i][0] for i in before_data.keys()] 274 colors = [plt.cm.Spectral(before_data[i][1]) for i in before_data.keys()] 275 276 # 绘图details 277 plot = squarify.plot(sizes = recovery_percent, # 指定绘图数据 278 label = name, # 指定标签 279 color = colors, # 指定自定义颜色 280 alpha = 0.6, # 指定透明度 281 value = recovery_percent, # 添加数值标签 282 edgecolor = 'white', # 设置边界框为白色 283 linewidth =0 # 设置边框宽度为3 284 ) 285 # 设置标签大小为 286 plt.rc('font', size=20) 287 # 设置标题大小 288 plot.set_title('至4月份各个区域的大致累计确诊和死亡率',fontdict = {'fontsize':15}) 289 # 除坐标轴 290 plt.axis('off') 291 # 除上边框和右边框刻度 292 plt.tick_params(top = 'off', right = 'off') 293 # 图形展示 294 plt.show() 295 296 data = df[df['日期'].array.year==2022] 297 data = data.loc[data['日期']=='2022-01'] 298 data1 = data.groupby('国家')['累计确诊病例'].sum() 299 data1 300 301 data1.values 302 303 import plotly.graph_objects as go 304 from plotly.subplots import make_subplots 305 306 fig = make_subplots(rows = 2,cols = 1, # 指定行列个数 307 subplot_titles=['各区域新增确诊人数分布图','各区域新增确诊人数占比图'], 308 ) 309 310 colors = ['#a4adf8','#eaa098','#72dcc6','#c8a7f8','#f2c6a8'] 311 312 for (k,v),i in zip(data.groupby('国家')['每日新增确诊病例'],colors): 313 fig.add_trace(row = 1,col = 1,trace = go.Box( 314 y=v, 315 name = k, 316 317 boxpoints = 'all', 318 boxmean = True, 319 marker = dict( 320 size = 2, 321 color = i, 322 ), 323 324 line = dict( 325 width = 1, 326 ), 327 )) 328 fig.add_trace(row = 2,col = 1,trace = go.Bar( 329 x = data1.index, 330 y = data1.values, 331 width=0.6, 332 opacity=0.8, 333 334 marker=dict( 335 color=colors, 336 line=dict(color='black',width=6) 337 ), 338 )) 339 340 fig.update_traces(showlegend = False) 341 342 fig.update_layout( 343 title = '各区域确诊人数情况分布图', 344 xaxis2 = dict( 345 title = '区域', 346 ), 347 yaxis = dict( 348 title = '每日新增确诊病例', 349 range=[0,1000], 350 ), 351 yaxis2 = dict( 352 title = '总新增确诊人数', 353 ), 354 margin = dict(l = 0,r = 0,b = 0) 355 ) 356 fig.show()
五、总结
新冠疫情大数据分析是一个非常复杂的过程,需要从多个角度对数据进行处理和分析。一般来说,我们可以将分析流程分为以下几个步骤:
- 数据收集:从各种公开数据源(如政府网站、科学期刊等)收集疫情相关数据,例如病例数、死亡率、感染风险等。
- 数据清洗和预处理:将收集到的原始数据进行清洗和预处理,去除异常值、填充缺失值、数据归一化等操作。
- 数据可视化:利用Python中的各种数据可视化库(如Matplotlib、Seaborn等)进行图表绘制,以便更好地观察数据变化趋势和分布情况。
- 数据分析和建模:利用Python中的机器学习库(如Scikit-learn、TensorFlow等)对处理后的数据进行分析和建模,得出一些有意义的结果和结论。
- 结果展示和报告撰写:根据前面的数据分析和建模结果,进行结果展示和报告撰写,向相关人员或者团队进行汇报。
总的来说,通过对新冠疫情数据的分析,我们可以更好地了解疫情发展的趋势和规律,提高疫情防控的效率和精准性,为公众提供更好的服务和保障。