综合设计——多源异构数据采集与融合应用综合实践
| 这个项目属于哪个课程 | 2023数据采集与融合技术 |
|---|---|
| 组名、项目简介 | 组名:普雷蒙奇、项目需求:多模态情感分析、项目目标:通过在网页中搜索关键词来得到一个综合的情感分析、项目开展技术路线:前端、python 、华为云平台、Django-restframework |
| 团队成员学号 | 102102112、102102115、102102116、102102118、102102119、102102120、102102156、102102159 |
| 这个项目目标 | 通过在网页中上传文本、图片、视频或音频分析其中的情感 |
| 其他参考文献 | [1]梁爱华,王雪峤 多模态学习数据采集与融合、[2]陈燕、赖宇斌 基于CLIP和交叉注意力的多模态情感分析模型 、[3]武星、殷浩宇 面向视频数据的多模态情感分析 |
Gitee文件夹链接(所有代码均存在一个人的码云中):
https://gitee.com/w-jking/crawl_project/blob/master/大作业/datacrawl(1).zip
项目整体介绍:
项目名称:
国产手机情感分析
项目背景:
近年来,国货新潮流兴起,华为Mate60系列供应链90%以上来自国内,消费者的真实反馈对于手机品牌口碑和市场表现至关重要,收集和分析消费者对于国产手机的反馈,不仅可以为用户提供一个选择手机品牌的依据,也可以为品牌提供有价值的建议和改进方向。
项目目标:
通过采集和挖掘不同模态(文本、图片、音频)的数据,运用不同的情感分析模型,构造一个可以对国产手机各个方面进行多模态分析的系统,对国产手机品牌得到一个综合的情感分析,直观的感受到大众对于国产手机的的态度,以便于更好的判断国产手机中的“国货之光”。
项目具体流程图:
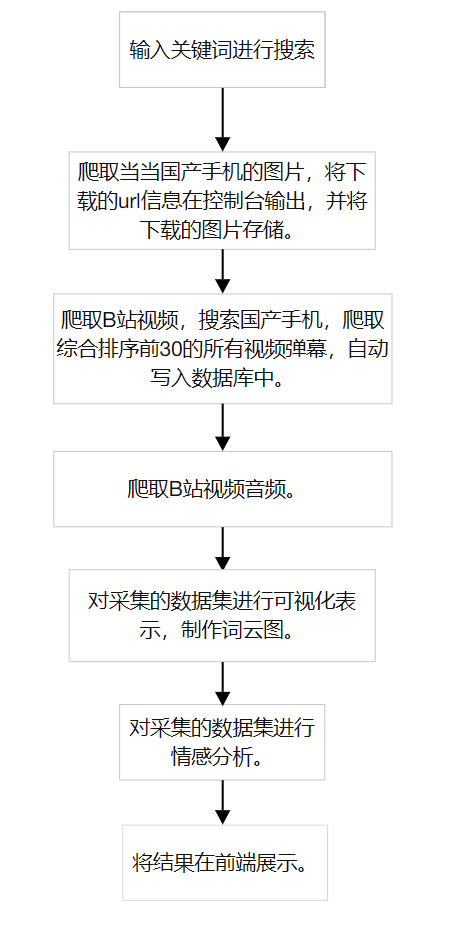
技术路线:
-
前端开发:
-
使用HTML、CSS和JavaScript进行前端的是界面设计,实现输入关键词和视频数量和弹幕数量后得到一个综合分析。
-
提升用户体验,使用动画效果和过渡效果,可以提高页面的交互性和吸引力。
-
-
后端开发:
-
使用python语言来实现后端开发的编写
-
使用Django框架来处理前端信息的接收,以及后端得到的信息返回
-
-
数据处理与分析:
-
文本爬取:
- 爬取B站弹幕和京东评论,但是京东评论在项目最后阶段爬取不到数据,所以只保留了弹幕的爬取。
- 采用request库的findall()函数获取指定cid的弹幕,并通过正则表达式提取出弹幕文本。
-
图片爬取:
- 爬取当当网的图片。
- 使用requests库的findall()函数和正则表达式取所有满足条件的图片链接。
- 并使用多线程机制将图片进行下载。
-
音/视频爬取:
- 爬取B站相关视频。
- 采用request库的findall()函数和正则表达式提取JSON中BV号。
- 使用正则表达式和json库获取视频和音频的url。
- 使用requests库来下载视频和音频文件。
-
文本分析: 首先考虑ERNIE-UIE文心模型,可是配置不成功,导致没有结果显示。接着考虑讯飞的情感分析模型,发现只能单句分析,不太符合需求,最后考虑百度云的API接口。
-
视频和音频分析:
- 对B站相关视频进行爬取,得到视频和音频。
- 使用Whisper方法将音频转为文本。
- 对上传的音频文件进行特征提取和情感识别。
-
图片分析:
- 使用预训练的BERT模型进行图像处理。
- 使用预训练的ResNet-50提取图片特征。
- 将图像特征输入到分类器中进行预测。
-
-
结果输出与展示:将分析结果通过前端界面展示。
输入框:
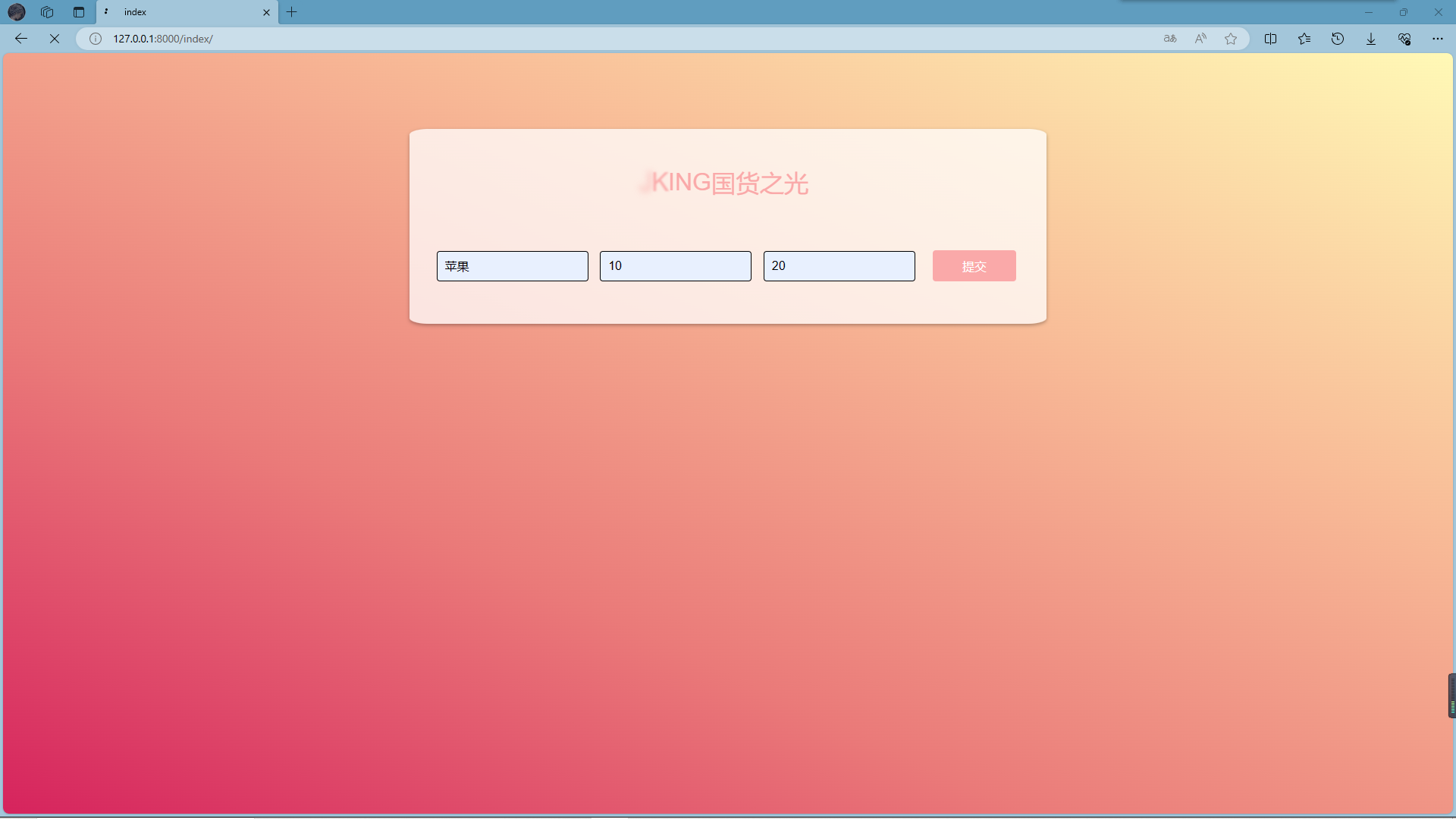
结果输出:
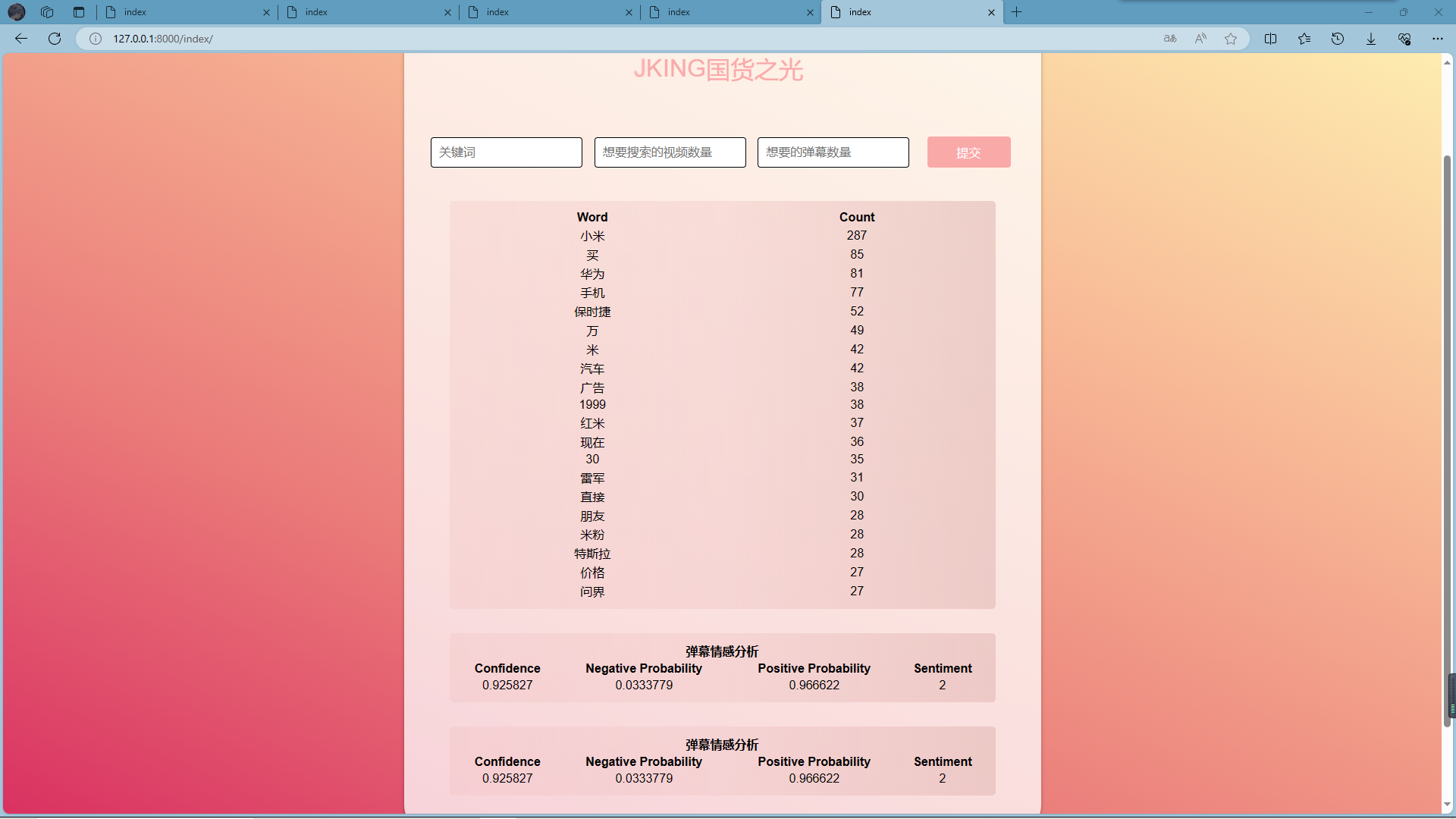
爬取关键词的情感分析:
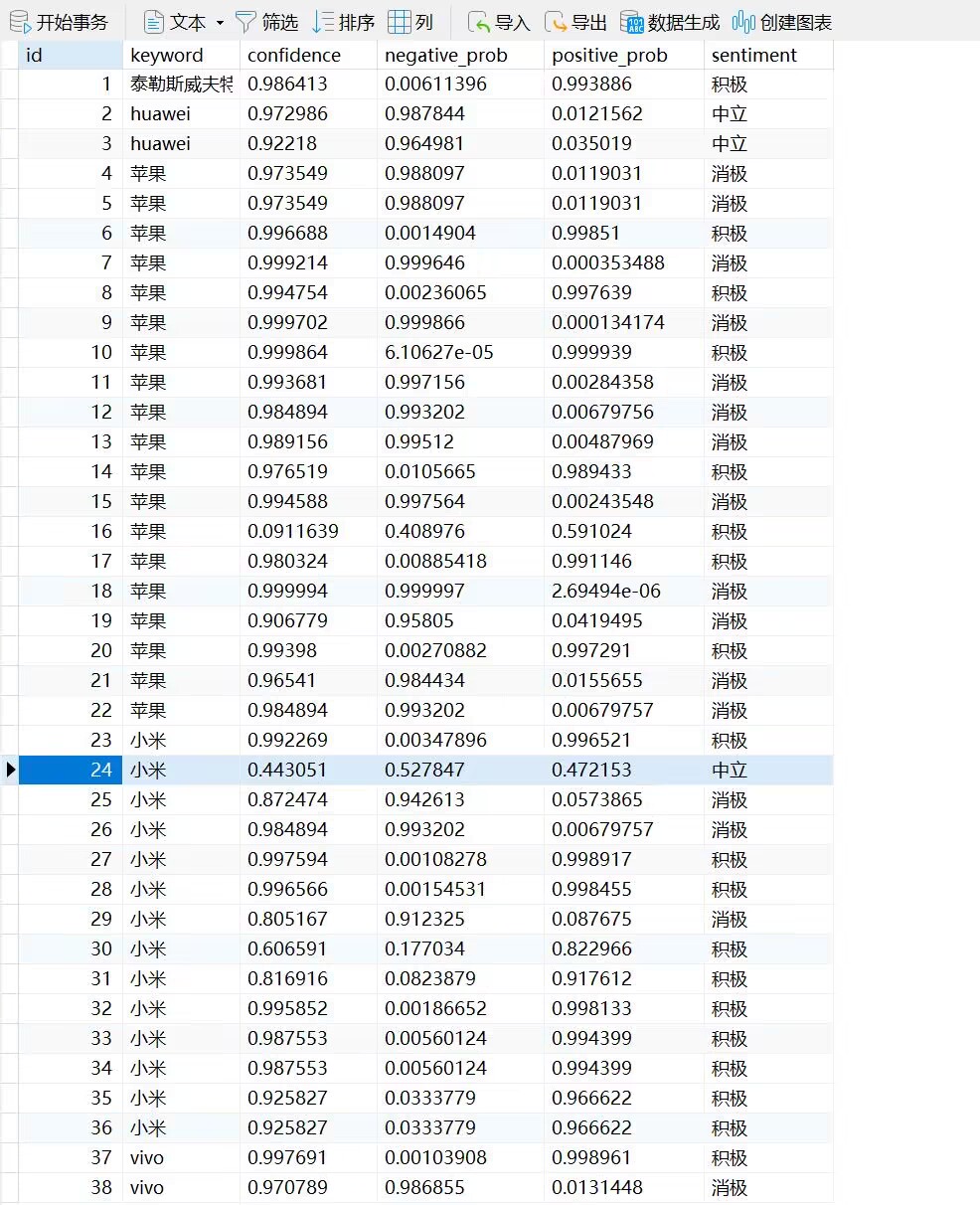
历史爬取数据:
个人分工
- 后端代码编写整合、OpenGauss数据库搭建和连接、Django网页搭建
数据库连接部分:
DATABASES = {
'default': {
# 'ENGINE': 'django.db.backends.sqlite3',
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'postgres', #数据库名
'USER': 'ykp', #用户名
'PASSWORD': 'gauss@115', #密码
'HOST': '119.3.174.128',#虚拟机ip
'PORT': 26000, #openGauss数据口的端口
'options': {'timezone': 'UTC'},
}
}
后端编写向前端传输数据部分:
class Index(APIView):
def get(self, request):
return render(request, "index.html")
def post(self, request):
keyword = request.POST.get("keyword")
num = int(request.POST.get("num"))
desired_danmu_count = int(request.POST.get("desired_danmu_count"))
history.objects.create(keyword=keyword, videonum=num, danmunum=desired_danmu_count)
list = self.dataCrawler(keyword, num, desired_danmu_count)
self.makeWordCloud(list)
analysisText = self.textAnalysis()
parsed_response = json.loads(analysisText)
items = parsed_response['items']
for item in items:
confidence = item['confidence']
negative_prob = item['negative_prob']
positive_prob = item['positive_prob']
sentiment = item['sentiment']
emotion = ''
if sentiment == 0:
emotion = '消极'
elif sentiment == 1:
emotion = '中立'
elif sentiment == 2:
emotion = '积极'
else:
pass
analysis.objects.create(keyword=keyword,confidence=confidence,negative_prob=negative_prob,positive_prob=positive_prob,sentiment=emotion)
folder_path = 'F:/datacrawl/audio' # 文件夹路径
# 获取文件夹内所有文件的列表
file_list = os.listdir(folder_path)
# 从文件列表中随机选择一个文件
random_file = random.choice(file_list)
pathstr = 'F:/datacrawl/audio/' + random_file
self.wav_to_text(pathstr)
audio = self.textAnalysis()
parsed_response = json.loads(audio)
items2 = parsed_response['items']
for item in items2:
confidence = item['confidence']
negative_prob = item['negative_prob']
positive_prob = item['positive_prob']
sentiment = item['sentiment']
emotion = ''
if sentiment == 0:
emotion = '消极'
elif sentiment == 1:
emotion = '中立'
elif sentiment == 2:
emotion = '积极'
else:
pass
analysis.objects.create(keyword=keyword,confidence=confidence,negative_prob=negative_prob,positive_prob=positive_prob,sentiment=emotion)
context = {'my_list':list, 'items':items, 'items2':items2}
return render(request, "index.html", context)
- 个人心得
通过这个项目,我学到了很多关于Django框架和数据库连接的知识,也提升了自己在后端开发方面的能力。同时,我更深入地了解了OpenGauss数据库的特点和用法。在整合的过程中也遇到了很多困难,尤其是在云平台数据库的连接,对这个框架从没听说过再到渐渐熟悉,个人能力也得到了很大的提升。