StarGANv2-VC: 一个多样化、无监督、非平行的自然音声转换框架
摘要
我们提出了一种使用生成对抗网络(GAN)的无监督非平行多对多声音转换(VC)方法,称为StarGAN v2。通过使用对抗性源分类器损失和感知损失的组合,我们的模型明显优于先前的VC模型。虽然我们的模型仅通过20名英语讲话者进行训练,但它可以推广到各种声音转换任务,如任意对多、跨语言和歌声转换。使用样式编码器,我们的框架还可以将普通的朗读语音转换为风格化的语音,例如情感和假声语音。对非平行多对多声音转换任务的主观和客观评估实验表明,我们的模型产生自然的声音,接近最先进的基于文本到语音(TTS)的声音转换方法的声音质量,而无需文本标签。此外,我们的模型完全卷积,并且配合像Parallel WaveGAN这样的快于实时的声码器,可以执行实时声音转换。
1. 引言
声音转换(VC)是一种将一个说话者的声音身份转换为另一个说话者的技术,同时保留语言内容。这项技术有各种应用,例如电影配音、通过跨语言转换进行语言学习、说话辅助以及歌声转换。然而,大多数声音转换方法需要平行语句才能实现高质量的自然转换结果,这严重限制了该技术的应用条件。最近在使用深度神经网络模型进行非平行声音转换的研究主要可以分为三类:基于自动编码器的方法、基于TTS的方法和基于GAN的方法。自动编码器方法,例如[1, 2, 3, 4],旨在通过训练具有适当约束的模型从输入音频中编码与说话者无关的信息。这种方法需要精心设计的约束来去除与说话者相关的信息,转换后的语音质量取决于从潜在空间中可以检索多少语言信息。另一方面,基于GAN的方法,例如CycleGAN-VC3 [5] 和StarGAN-VC2 [6],不对编码器进行约束,而是使用鉴别器来教导解码器生成听起来像目标说话者的语音。由于不能保证鉴别器会从真实数据中学到有意义的特征,这种方法通常会遇到转换语音与目标语音之间的不相似或者生成语音中的失真等问题。与前两种方法不同,基于TTS的方法如Cotatron [7]、AttS2S-VC [8]和VTN [9]利用文本标签,并且通过从输入语音中提取对齐的语言特征来直接合成语音。这确保了转换后的说话者身份与目标说话者身份相同。然而,这种方法需要文本标签,而这些标签通常不容易获得。
在这里,我们提出了一种新的方法,使用最近提出的图像风格转换GAN架构StarGAN v2 [10]进行无监督非平行多对多声音转换。我们的框架产生自然的语音,明显优于先前的最先进方法AUTO-VC [1],在自然性和说话者相似性方面接近基于TTS的方法,如在Voice Conversion Challenge 2020(VCC2020)[11]中报告的VTN [9]。此外,尽管它只在具有有限说话者数量的单语音数据上进行训练,我们的模型可以推广到各种声音转换任务,包括任意对多的转换、跨语言转换和歌声转换。此外,当在包含多种语音风格的语料库上进行训练时,我们的模型显示出将语音转换为风格语音的能力,例如将普通的朗读语音转换为富有情感的表演语音,将胸声转换为假声。
在这项工作中,我们有多项贡献:(i)将StarGAN v2应用于声音转换,实现了从普通语音到具有多样化风格的语音的转换;(ii)引入了一种新颖的对抗性源分类器损失,大大提高了转换语音和目标语音之间的说话者身份相似性;(iii)据我们所知,这是第一个在感知损失中同时使用自动语音识别(ASR)网络和基频(F0)提取网络的声音转换框架。
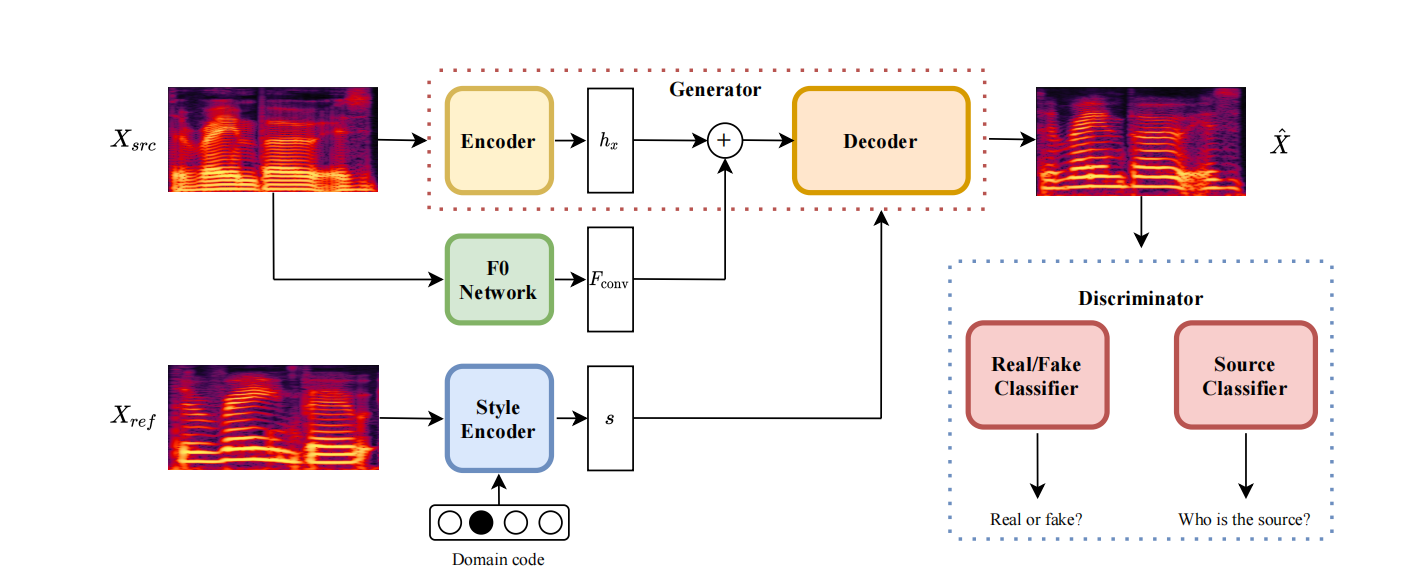
图1:带有风格编码器的StarGANv2-VC框架
在这个图中,Xsrc表示源输入,Xref表示包含风格信息的参考输入,ˆX代表转换后的mel频谱。hx、Fconv和s分别表示源的潜在特征、从源的卷积层提取的F0特征,以及在目标领域中的参考的风格代码。hx和hF0按通道连接作为解码器的输入,hsty通过自适应实例归一化(AdaIN)[12]注入解码器。两个分类器形成鉴别器,确定生成的样本是否真实,以及ˆX的源说话者是谁。在另一种方案中,风格编码器被映射网络替代,不需要参考mel频谱Xref。
2. 方法
2.1. StarGANv2-VC
StarGAN v2 [10] 使用一个单一的鉴别器和生成器来根据来自风格编码器或映射网络的领域特定风格向量在每个领域中生成多样的图像。我们采用了相同的架构来进行语音转换,将每个说话者视为一个独立的领域,并添加了一个预训练的联合检测和分类(JDC)F0提取网络 [13] 来实现F0一致的转换。我们的框架概述如图1所示。
生成器。生成器G将输入的mel频谱Xsrc转换成反映hsty中的风格的G(Xsrc, hsty, hf0),其中hsty可以由映射网络或风格编码器提供,而hf0则由F0提取网络F中的卷积层提供。F0网络。F0提取网络F是一个预训练的JDC网络[13],从输入的mel频谱中提取基频。JDC网络具有卷积层,后跟BLSTM单元。我们只使用对于X∈X的卷积输出Fconv(X)作为输入特征。
映射网络。映射网络M生成一个带有随机潜在代码z∈Z的风格向量hM = M(z, y),其中y∈Y表示领域。潜在代码从高斯分布中采样,以在所有领域中提供多样化的风格表示。直到最后一层,风格向量表示在所有领域中是共享的,然后在最后一层应用领域特定的投影。
风格编码器。给定一个参考mel频谱Xref,风格编码器S在领域y∈Y中提取风格代码hsty = S(Xref , y)。类似于映射网络M,S首先在所有领域中通过共享层处理输入。然后,领域特定的投影将共享特征映射到领域特定的风格代码。
鉴别器。[10]中的鉴别器D具有共享层,学习所有领域中真实和伪造样本之间的共同特征,然后是领域特定的二进制分类器,用于在每个领域y∈Y中对样本是否为真进行分类。然而,由于领域特定的分类器仅由一个卷积层组成,可能无法捕捉到说话者发音等领域特定特征的重要方面。为了解决这个问题,我们引入了一个附加的分类器C,与D具有相同的架构,它学习转换后样本的原始领域。通过学习哪些特征在转换后仍然逃避输入领域,这个分类器可以提供关于生成器不变的但对原始领域具有特色的特征的反馈,生成器可以根据这些特征改进,生成更相似的目标领域样本。更详细的说明见图2。
2.2. 训练目标
StarGANv2-VC的目标是学习一个映射G:Xysrc → Xytrg,将源领域ysrc ∈ Y的样本X ∈ Xysrc转换为目标领域ytrg ∈ Y中的样本ˆX ∈ Xytrg,而不需要平行数据。
在训练过程中,我们随机采样目标领域ytrg ∈ Y和风格代码s ∈ Sytrg,可以通过映射网络得到s = M(z, ytrg),其中z ∈ Z是潜在代码,也可以通过风格编码器得到s = S(Xref , ytrg),其中Xref ∈ X是参考输入。给定mel频谱X ∈ Xysrc,源领域ysrc ∈ Y和目标领域ytrg ∈ Y,我们使用以下损失函数来训练我们的模型。
对抗性损失。生成器接收输入mel频谱X和风格向量s,并学习通过对抗性损失生成新的mel频谱G(X, s)。 Ladv = EX,ysrc [log D(X, ysrc)] + EX,ytrg,s [log (1 − D(G(X, s), ytrg))] (1) 这里,D(·, y)表示领域y ∈ Y的真/假分类器的输出。
对抗性源分类器损失。我们使用附加的对抗性损失函数和源分类器C(见图2)。 Ladvcls = EX,ytrg,s [CE(C(G(X, s)), ytrg)] (2) 这里,CE(·)表示交叉熵损失函数。
风格重构损失。我们使用风格重构损失来确保可以从生成的样本中重构出风格代码。 Lsty = EX,ytrg,s || s - S(G(X, s), ytrg) ||₁ (3)
风格多样性损失。风格多样性损失被最大化,以强制生成器生成具有不同风格代码的不同样本。除了最大化生成样本之间的平均绝对误差(MAE),我们还最大化使用不同风格代码生成的样本之间的F0特征的MAE。 Lds = EX,s1,s2,ytrg || G(X, s1) - G(X, s2) ||₁ + EX,s1,s2,ytrg || Fconv(G(X, s1)) - Fconv(G(X, s2)) ||₁ (4) 这里,s1、s2 ∈ Sytrg是从领域ytrg ∈ Y中随机采样的两个风格代码,Fconv(·)是F0网络F的卷积层的输出。