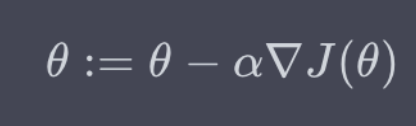参考网址:
https://blog.csdn.net/weixin_44179269/article/details/124573992?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170167791616800197042802%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=170167791616800197042802&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-124573992-null-null.142^v96^pc_search_result_base1&utm_term=backword&spm=1018.2226.3001.4187
以下伪代码只供理解模型训练的一些步骤和流程
1、网络类定义:
1 class MYNET(nn.Module): 2 def __init__(self,in_channels=3,out_channels=2): 3 super(MYNET,self).__init__() 4 .... 5 ..... 6 7 8 def forward(self.x): 9 ...... 10 ...... 11 return ... ...
2、训练定义 前向传播,loss计算,loss反向传播计算梯度
1 def main():
#训练网络 2 model = UNET(in_channels=3, out_channels=2).to(DEVICE) 3 #优化器 4 optimizer = optim.Adam(model.parameters(),lr= LEARNING_RATE)
#损失函数
loss_fn = nn.BCEWithLogitsLoss() 5 #数据集 6 train_loader, val_loader = get_loaders(train_pths, val_pths.batchsize.....)
#预训练模型加载
if LOAD_MODEL: load_ckpt(torch.load(Pretrained_Model),model)
#tensorboard可视化,创建writer
global writer
writer = SummaryWriter(log_dir = '/path/to/log_dir')
for epoch in range(NUM_EPOCHS):
...
train_fn(epoch,train_loader,model,optimizer,loss_fn,scaler)
checkpoint={
"state_dict": model.state_dict(),
"optimizer": optimizer.state_dict(),
}
save_ckpt(checkpoint)
writer.close()
def train_fn(epoch, loader, model, optimizer, loss_fn): loop = tqdm(loader)#进度条 for step,(data,targets) in enumerate(loop): .... #前向传播 predict = model(data) #计算loss loss = loss_fn(predict,targets) #loss(代价函数)反向传播计算梯度 ‘’‘’backward执行之后,会自动对loss函数表达式中的可求导变量进行偏导数求解(梯度是个向量),并赋值到自变量(可训练的网络参数).grad中‘’ loss.backward() #优化器执行参数更新 optimizer.step()
3、有关代价函数,反向求梯度
参考:https://www.cnblogs.com/xfuture/p/17869521.html
代价函数(是个标量):
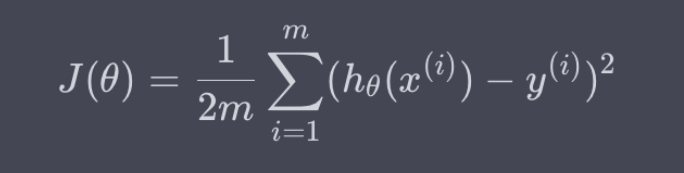
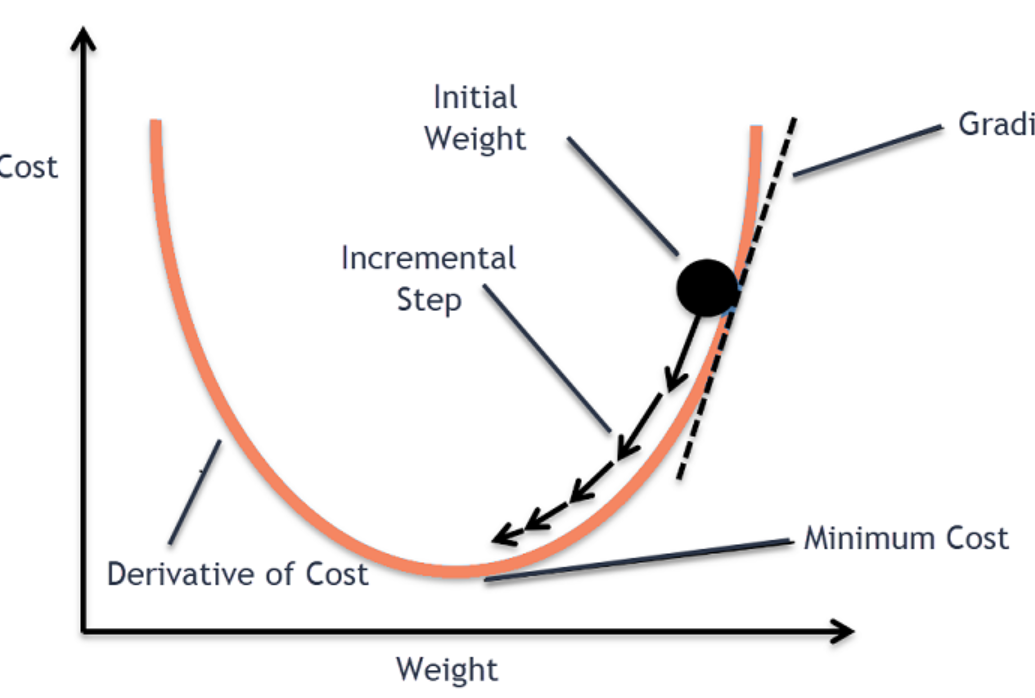
图(二维):
梯度(是代价函数在某点对所有自变量的偏导数构成的向量):
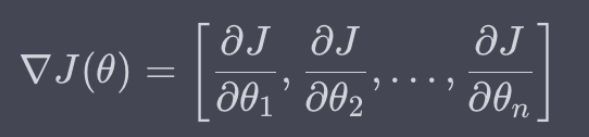
梯度更新(alpha为学习率):