1. 为什么要对样本进行 归一化
样本之间的数量级是千差万别 有量纲的 例如:
theta1 >> theta2
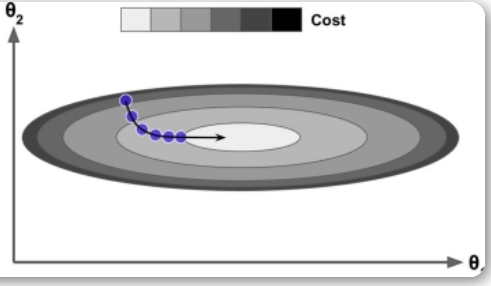
数值小的 theta2 反而能快速的 收敛
数值大的 theta1 收敛较慢
出现 theta2 等待 theta1 收敛的情况
2. 归一化的方式一 最大最小值
min-max scaling
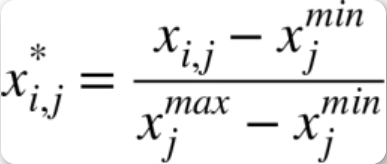
求出列的 最大值与最小值
import numpy as np
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data = np.array([1, 2, 3, 5, 5])
ret = scaler.fit_transform(data.reshape(-1, 1))
print(ret)
3. 归一化的方式二 标准归一化

样本数据映射到均值为0 方差为1 的标准正态分布上

from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data = [[1], [2], [3], [5], [5001]]
scaler.fit(data)
print(scaler.mean_)
print(scaler.var_)
print(scaler.transform(data))
# 虽然 5001 是一个 坏样本 但是归一化之后也不会相差 太多