深度学习的实用层面
Train/Dev/Test sets
深度学习是一个典型的高度迭代的过程,需要不断地进行循环测试,来找到最适合当前网络的超参。一方面可以提升迭代的效率,另一方面可以避免过度拟合等问题。
在实践中,(合理的)高质量训练集、验证集和测试集,有助于提升迭代的效率。
Train/Dev/Test sets
-
Train set:训练集,用于模型拟合的数据样本;
-
Dev set:验证集,是模型训练过程中单独流出来的样本集,用于调整模型的超参数以及对模型的能力进行初步评估。即cross validation set,用来测试不同算法。
-
Test set:用来最终评估模型的泛化能力。但是测试集的结果不能用来作为调参、选择特征等算法相关选择的依据。
划分标准:
- 传统规模较小的数据集:常用的划分方法是三七分。70%作为训练集、30%作为测试集。或者60%作为训练集、20作为验证集、20作为测试集。
- 大数据时代呢(数十万、百万玩级):dev/test sets的比例不需要太高,只要足够测试就好。可能是98%:1%:1%甚至更小的dev/test sets。
- 最好确保dev set和test set的数据来自相同的数据分布。因为要用dev set来评估不同的模型,如果dev set和test set来自同一个分布就会表现得比较好。
最后,没有test set也是可以的。
Bias/Variance
Bias:偏差,High bias:欠拟合;说明算法比数据简单,不足以描述数据。
Variance:方差,High variance:过拟合;说明算法超过了s-huju得实际复杂熊,甚至将一些随机因素过度解释为了数据规律。

对于深度学习的多维度的算法,不能像平面图那样直观的从结果看出来是高方差还是高偏差。需要通过对比training set error、dev set error以及base error的关系。下表是判断依据(假设base error接近0%,base error就是人眼识别的结果)train set error比dev set error好得多,那就是高方差。train set error比base error 差得多,那就是高偏差。
| Train set error | Dev set error | type |
|---|---|---|
| low (1%) | high (11%) | high variance |
| high (15%) | high, but near train set error (16%) | high bias |
| high (15%) | high, but much higher than Train set error (30%) | high bias & high variance |
| low (0.5%) | low (1%) | low bias & low variance |
好的算法同时要求low bias和 low variance,这里的低都是相对于base error的,如果假设base error = 15%,那么第二行的算法也是一个好的算法。
bias-variance trade-off问题:
bigger、regularization
Basic Recipe for Machine Learning
一般步骤:

针对bias和variance要选择对应的解决方法。在早期ML,可能在降低bias是variance会增高或者反过来,所以强调bias-variance trade-off;在现在DP,可以通过加大神经网络或者增加更多的数据,同时解决这两个问题,而不会影响到彼此(翻译说一石二鸟)
Regularization your neural network
-
正则化有助于防止over fitting 过度拟合,降低方差。
-
常用的正则化方式:
-
L2 regularization
-
dropout regularization
-
-
浅显的理解之所以会有过拟合问题,本质上是数据存在一定的随机性干扰(即在主要的规律外,还有一定的随机因素干扰了数据,而这些随机因素被算法当成规律学习了),而中和这种随机性的办法就是在算法中也增加一些“干扰”,这个“干扰”就是Regularization。
下图是是否做了regularization的对比举例,直观上,regularization 让decision boundary更平滑了:
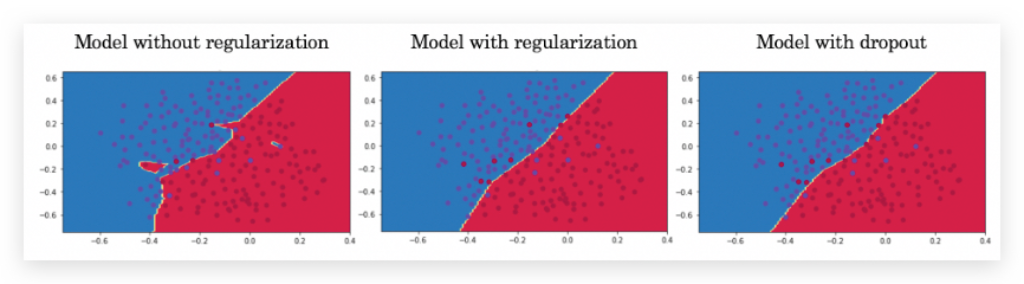
L2 Regularization
- L1范数:$$||X||1=\sum^{n}|x_i| $$,表示非零元素的绝对值之和。
- L2范数:$$||X||_2=\sqrt{\sum{n}_{i=1}x_i2} $$,表示元素的平方再开根
- 矩阵的L2范数叫做:费罗贝尼乌斯范数,所有元素的平方和$$||W||^{2}_F$$
加上正则化的损失函数:其中$$\lambda$$是正则化参数
L1正则化和L2正则化的特征:
-
L1正则化,权重W最终会变得稀疏,多数会变成0
-
L2正则化,使权重参数W衰减
为什么L2正则化可以预防过拟合
当设置的$$\lambda$$很大的时候,那么整个函数J对于范数部分更为敏感(因为导致范数部分值比较大),为了保证J的值比较小,那么最终倾向于让W向0靠近;W靠近0的后果是神经网络中的很多单元的作用变得很小,整个神经网络越来越接近逻辑回归。
**同时过大的$$\lambda$$,导致W偏小,让激活函数(如tanh functiont)处于偏线性的部分。因此不会发生过度拟合的现象。L2正则化是训练深度学习模型时最常用的一种办法。 **

L2 regularization的不足:要通过不断的选用不同的λ进行测试,计算量加大了
Dropout Regularization
Dropout 正则化:在每轮迭代计算时,随机地将神经网络中的一些神经元剔除,以达到降低一些复杂隐藏层中隐藏单元的权重,来避免过度拟合。
实现dropout("Inverted dropout")反向随机失活

keep-drop:代表保留某个隐藏单元的概率,
-
根据a3形状定义矩阵 $$d3$$,矩阵元素取值范围为[0,1),将其于keep-drop进行比较,小于0.8的元素设置为true,否则为false。并将整个布尔型矩阵再赋给 $$d3$$。
-
将 $$d3$$于 $$a3$$逐元素相乘(在python中这是可以的,true=1,false=0)。相乘后,有20%的变成了0,从而降低了对结果的影响。
-
最后向外拓展 $$a3$$, $$a3/=keep-drop$$,使得剩下的这些权重参数W变得比原来大,保证激活函数的期望值与不使用dropout时一致。
理解dropout
- 功能于L2正则化类似。对于参数及较多的层可以使用keep-drop较大的值(不同的层可以使用不同的值,但是这样你也需要通过更多的超参数来控制不同层的keep-drop,会让交叉验证花费更多)。
- dropout的一大缺点是:代价函数不能再被明确定义,每次迭代,都会以及移除一些节点,那么cost function就不一样了。这种情况,想检查梯度下降的性能,实际上是很困难的。
- 实践中,可以先将keep-drop设置为1,也就是保留所有的神经单元,确保J函数的单调递减,然后再使用dropout正则化。
- 老师说计算机视觉领域用得多,其他领域不太推荐呢。
其他正则化
数据增广:假如是图片数据,想要扩大数据集代价比较高,可以通过对图片进行操作来以较小的成本获得新的质量较差的(相比新的数据)数据。比如对图片进行水平翻转、截取、缩放等操作。对数字可以对数字进行扭曲等操作。
early stopping、
如下图,在迭代的过程中可以发现dev set error会线上升在下降。因此在dev error上升的前的这个节点停止迭代可能会得到一下相对不错的结果。
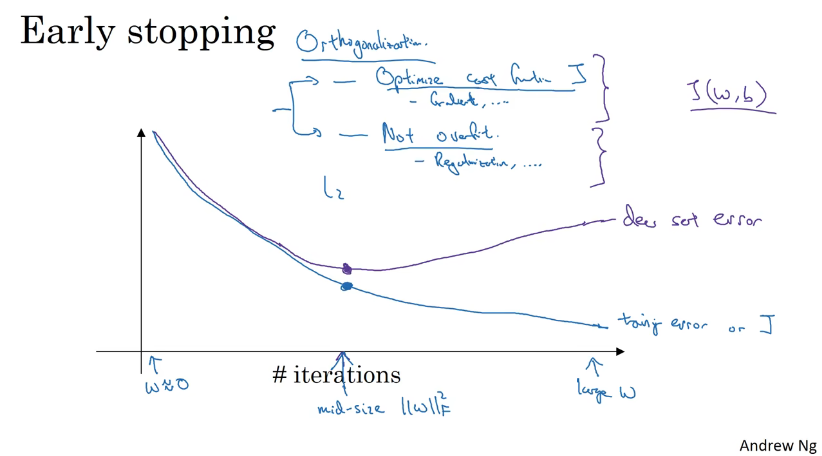
但是early stop缺点在于,他与最小化J的这个任务是相悖的,不能同时处理过拟合和代价函数不够小的问题。相比较于L2正则化,early stopping只需要运行一次梯度下降就可以找出W的中间值、最大、最小值。不需要尝试L2正则化超参数$$\lambda$$很多值。(使用 L2 正则化的话,这样训练时间可能很长,参数搜索空间大,计算代价很高。)
Setting up your optimization problem
归一化输入
归一化输入可以加速训练。要注意train set和dev/test set应该用一样的normalizing方法。normalizing = 中心化(均值为0)+归一化(方差为1)
为什么要归一化输入?
让每个参数的取值范围都近似一致,这样在做梯度下降的时候,所有的参数下降的速率相似;如果速度不一致,很可能有些参数已经下降完成了,而另一些参数还在下降过程中,就像图中左边的曲线。(不进行归一化,每个参数的取值范围不一致,那么每个参数下降的步长不一致,就会走“弯路”)。
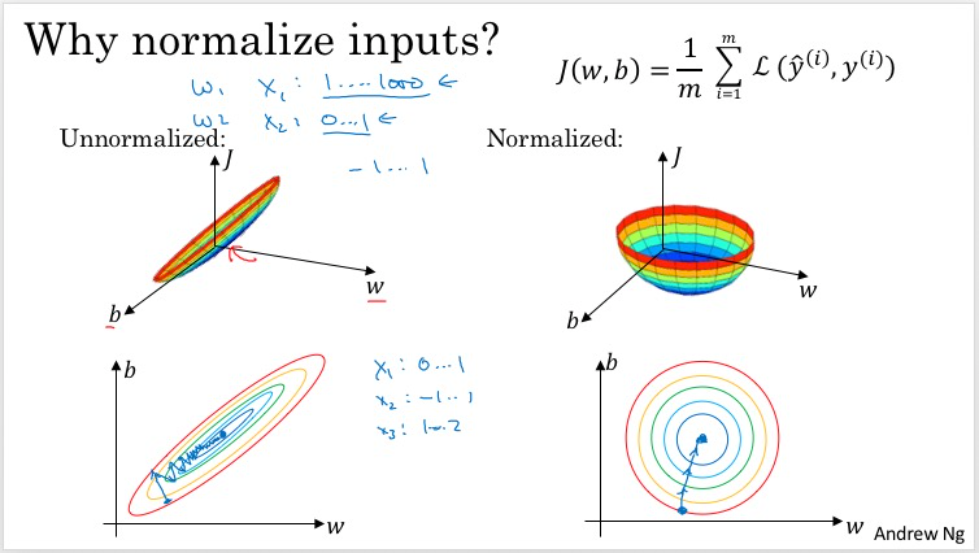
中心化的作用也是类似,因为在初始化参数的时候,用的是同一个随机分布做的初始化。
Vanishing / Exploding gradients
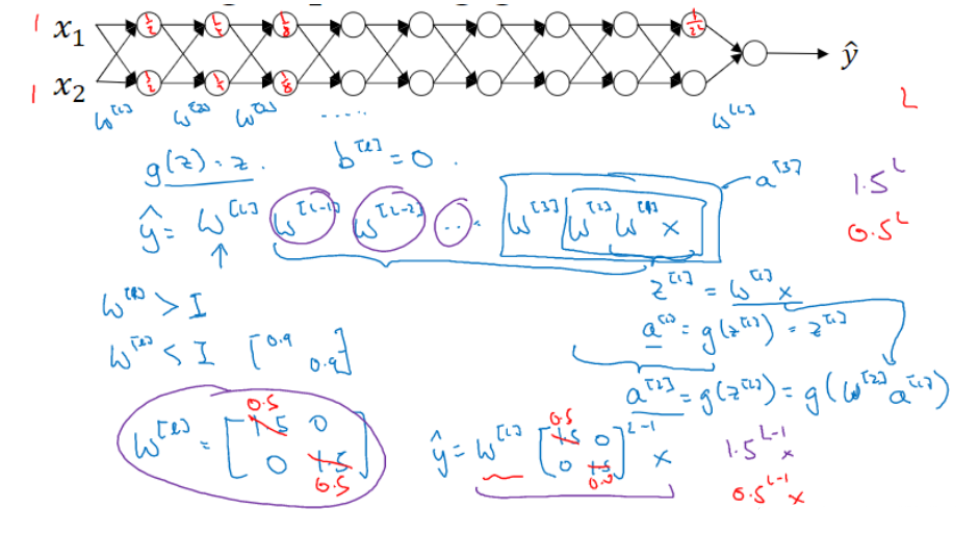
在非常深的神经网络中,权重只要不等于 1,激活函数将会呈指数级递增或者递减,导致训练难度上升,尤其是梯度与 L 相差指数级,梯度下降算法的步长会非常非常小,学习时间很长。
缓解的办法:better or more careful choice of the random initialization for your neural network.
神经网络权重的初始化
在之前的课程中提到(shallow neural network),初始化W的时候,会乘一个系数(比如0.01),为了是让W尽量小,尽量使得激活函数出现在有明显梯度的点,但具体多小呢,正是本节要解决的问题。 但对于DNN,鉴于Vanishing / Exploding gradients问题,初始化的参数希望让z尽量计算结果接近1。Variance(z)=1(就是预测值要是最好就是1)。 由于input是normalize的,因此尽量让w的方差靠近1/n,n是输入特征向量。
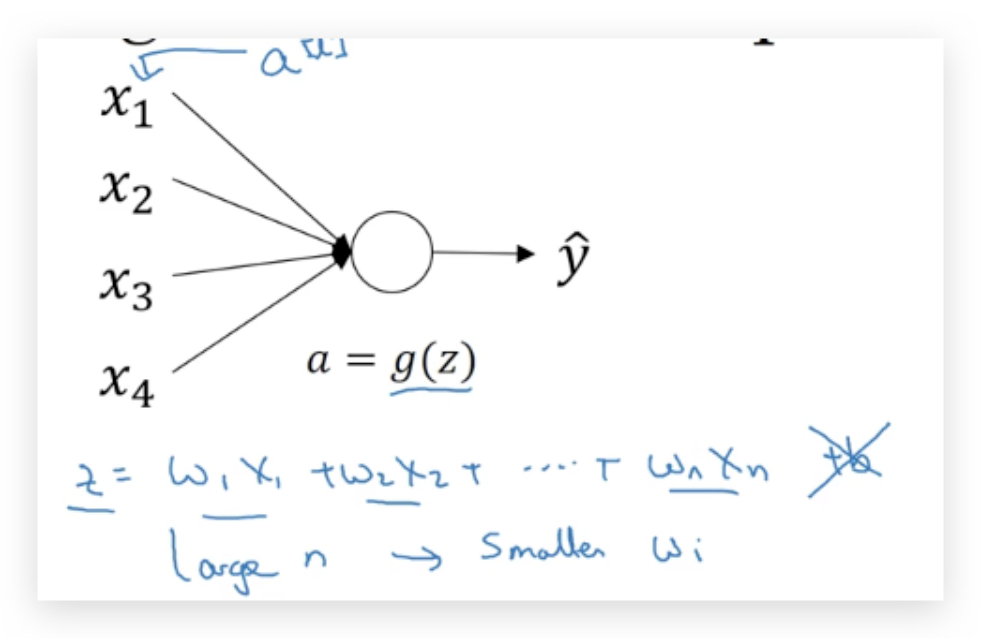
W[l]=np.random.randn(shape)*np.sqrt(1/n[l-1]),1/n[l-1]是给第l层输入的特征数量
如果使用ReLu激活函数,则$$*np.sqrt(\frac{2}{n^{[l-1]}})$$,称为Xavier初始化
如果使用tanh激活函数,则$$*\sqrt{(\frac{1}{n{[l-1]}})}$$或者$$*\sqrt{(\frac{2}{nn^{[l]}})}$$
梯度数值的逼近
梯度检验的作用是确保反向传播的正确运算。
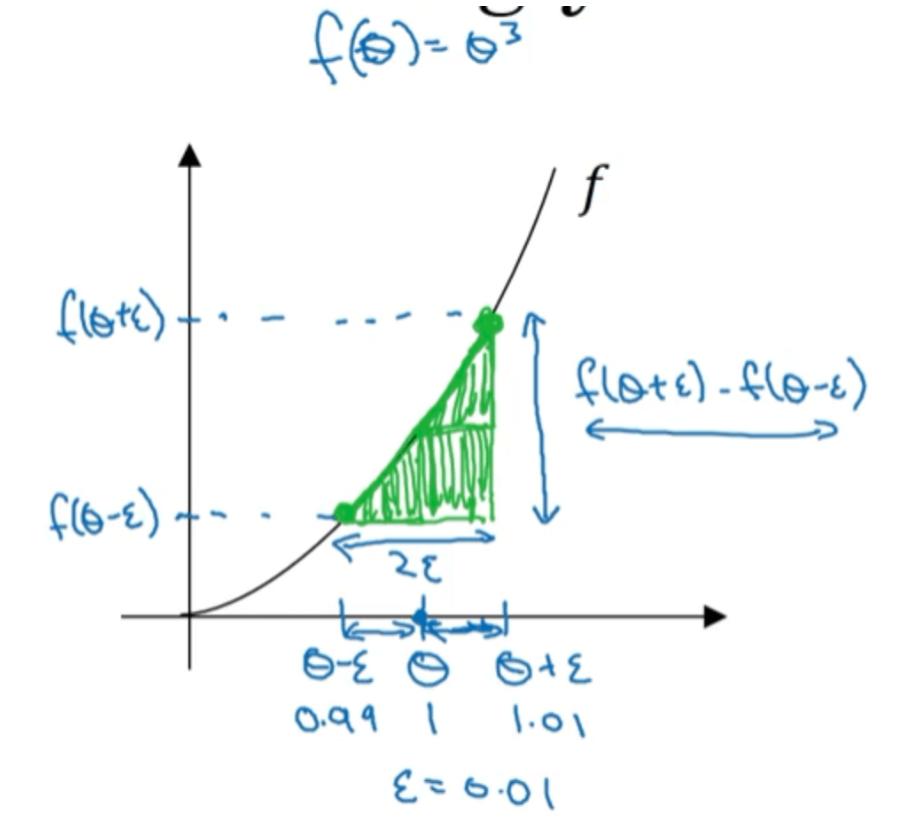
单边误差求导数
f(θ+ϵ)−f(θ)/ϵ=1.013−10.01=3.0301
双边误差求导数
f(θ+ϵ)−f(θ−ϵ)/2ϵ=1.013−0.9932×0.01=3.0001
双边误差求导数要比单边误差求导数更加准确。这是因为单边估计时误差为O(ϵ),而双边估计时误差为O(ϵ2),当ϵ<1时,肯定有ϵ2<ϵ,因此双边估计比单边估计更为准确。
梯度检验
梯度检验帮助我们发现反向传播的中的bug
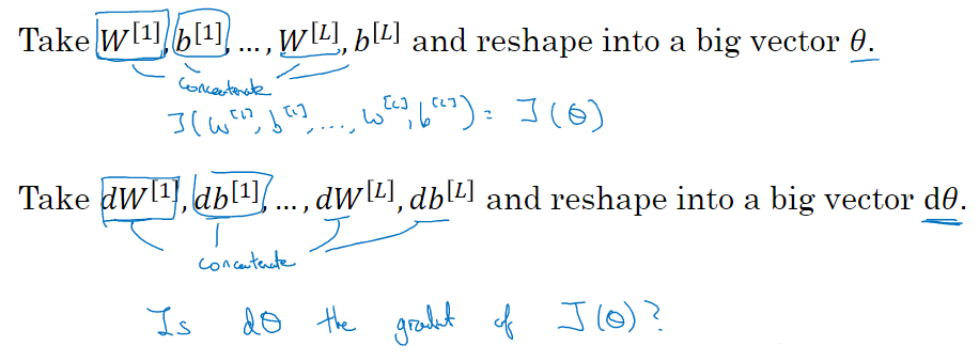
将所有W矩阵转换成向量之后,做连接运算,得到一个巨型向量θ ,该向量表示为参数θ,代价函数 J 是所有W和b的函数,现在你得到了一个θ 的代价函数 J (即J (θ) )。
接着,同样可以把 \(dW^{[1]}\)和\(db^{[1]}\)·····\(dW^{[L]}\)和\(db^{[L]}\)换成一个新的向量,用它们来初始化大向量dθ ,并且它与θ具有相同维度。(PS:θ的维度是超参数)

两个dθ应该具有相同的数量级,或者说dθ[i]要更小,那么就是证明没什么问题。that‘s great
注意:
- 仅在debug时用Gradient checking
- 不要漏掉 regularization 的部分
- dropout regularization不适用,因为J是不稳定的。