多样性和收敛性是什么?
- 多样性:多样性是指在一个系统、模型或者群体中存在的不同类型的元素的数量和种类。在生物学中,多样性可能指的是一个生态系统中的物种多样性;在社会学中,多样性可能指的是一个社区或者组织中的文化、种族、性别等方面的多样性;在计算机科学中,多样性可能指的是解决一个问题的不同方法或者策略。
- 收敛性:收敛性是指一个系统、过程或者序列随着时间的推移趋向于一个特定的值或者状态。在数学中,收敛性可能指的是一个数列趋向于一个特定的极限;在物理学中,收敛性可能指的是一个物理系统趋向于一个稳定的状态;在计算机科学中,收敛性可能指的是一个算法或者模型在训练过程中的性能逐渐提高并趋向于一个最优的状态。
这两个概念在很多情况下都是相互关联的。例如,在一个生态系统中,物种的多样性可能会影响到系统的稳定性和收敛性;在一个机器学习模型的训练过程中,不同的训练策略(多样性)可能会影响到模型的收敛速度和最终性能(收敛性)。
多样性和收敛性分别在基于决策聚类的大规模优化进化算法中有什么用处?
-
多样性:多样性是指种群中个体的差异性。在优化进化算法中,多样性有助于防止算法过早陷入局部最优解,能够在搜索空间中广泛搜索,提高找到全局最优解的可能性。通过保持种群的多样性,算法可以在全局范围内进行探索,而不仅仅是在当前最优解的附近进行搜索。
-
收敛性:收敛性是指算法的解趋向于最优解的能力。在优化进化算法中,收敛性是评价算法性能的重要指标之一。一个好的优化算法应该具有快速收敛到全局最优解的能力。如果算法的收敛性不好,即使种群的多样性很高,也可能无法在有限的迭代次数内找到满意的解。
在基于决策聚类的大规模优化进化算法中,需要通过适当的策略来平衡多样性和收敛性,以在全局范围内进行有效的搜索,同时又能快速收敛到全局最优解。
NSGA-II(快速非支配排序的遗传算法)
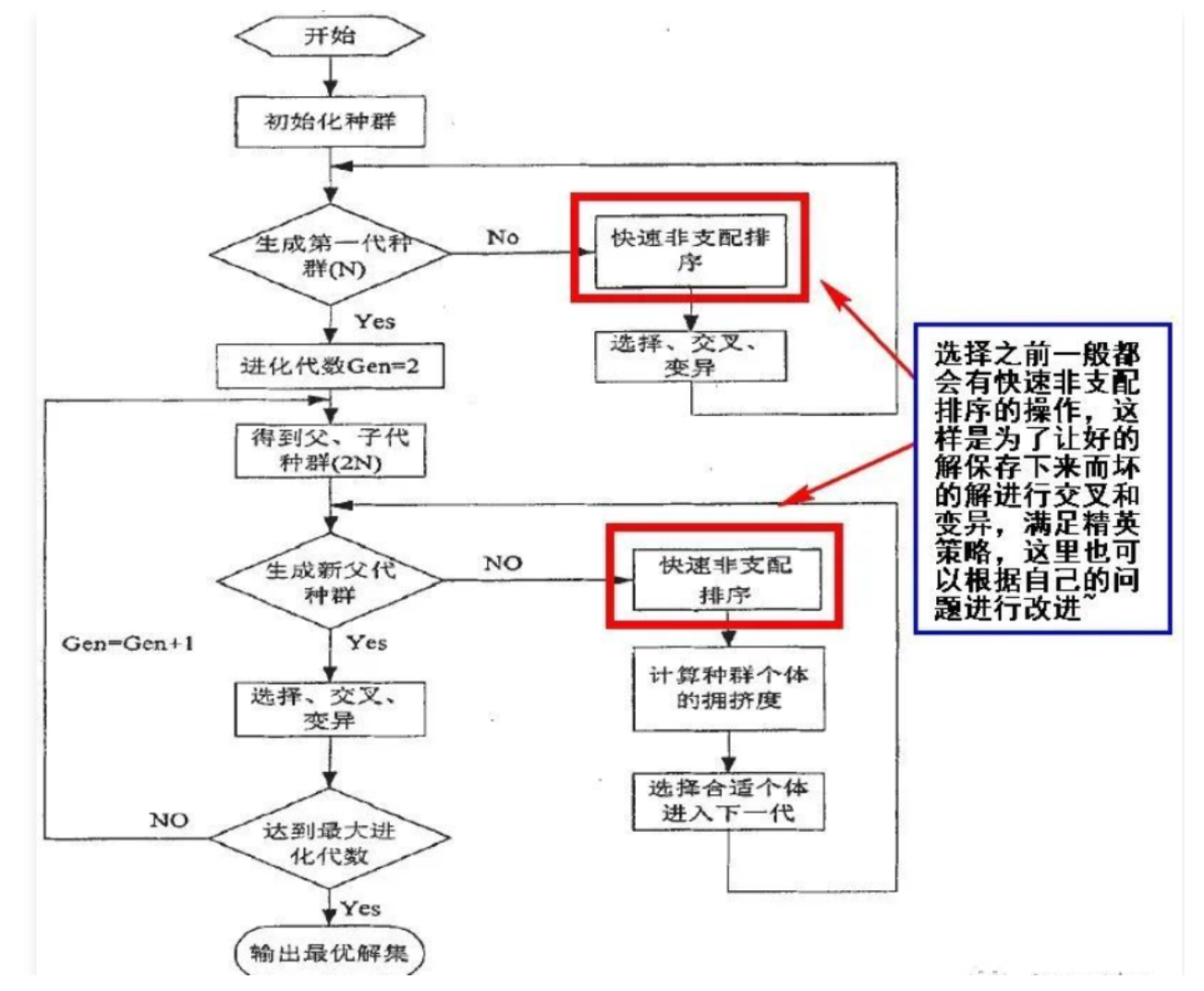
通过快速非支配排序找出最优的支配解,用于确定解的优势关系。每个等级都包含一组被其他等级中的任何解都不支配的解。等级1包含的解被认为是最优的,等级2的解次之,以此类推。这种方法可以快速有效地对种群进行排序,以便在进化算法中选择最优解。
保留优异的支配解,交叉变异
在NSGA-II算法中计算个体的拥挤度有什么用处?
在NSGA-II算法中,拥挤度的计算是为了维护种群的多样性,并帮助在非支配排序后的选择过程中进行决策。
在多目标优化问题中,通常会有一组解(称为Pareto前沿)在所有目标上都不被其他解支配。然而,这组解通常不止一个,因此需要一种方法来选择最好的解。这就是拥挤度计算的作用所在。
拥挤度是一个度量,表示一个解在目标空间中的邻居有多近。如果一个解的拥挤度较高,那么它周围的其他解就比较少,反之亦然。在选择过程中,如果两个解的非支配等级相同,那么拥挤度较低的解(即周围的解较少的解)会被优先选择。这样做的目的是为了鼓励算法探索解空间的不同区域,从而找到更多的可能解,而不是仅仅集中在某个局部区域。
拥挤度如何计算出来?
计算拥挤度,需要先进行快速非支配排序,得出不同种群的等级
- 对于每个目标函数,将解按照该目标函数的值进行排序。
- 对于排序后的每个解,计算它在该目标函数上的两个相邻解之间的距离。这个距离被称为解的拥挤距离。
- 对于每个解,其在所有目标函数上的拥挤距离之和就是它的拥挤度。
收敛性和多样性分别是由什么决定的?
- 收敛性:NSGA-II算法通过非支配排序来保证解的收敛性,即算法能够逐渐接近或达到真实的Pareto前沿。非支配排序根据解的支配关系将种群分为几个等级,每个等级内的解都不被其他等级的解支配。在选择过程中,等级较高(被支配的少)的解会被优先选择。
- 多样性:拥挤度计算则是为了保证解的多样性。拥挤度是一个度量,表示一个解在目标空间中的邻居有多近。在选择过程中,如果两个解的非支配等级相同,那么拥挤度较低的解(即周围的解较少的解)会被优先选择。这样做的目的是为了鼓励算法探索解空间的不同区域,从而找到更多的可能解,而不是仅仅集中在某个局部区域。
因此,拥挤度在NSGA-II算法中起到了平衡收敛性和多样性的作用。通过非支配排序和拥挤度计算的结合,NSGA-II能够在保证解的质量(收敛性)的同时,也保证了解的多样性。
收敛性与多样性是如何选择出来的?
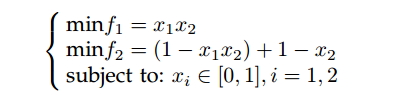
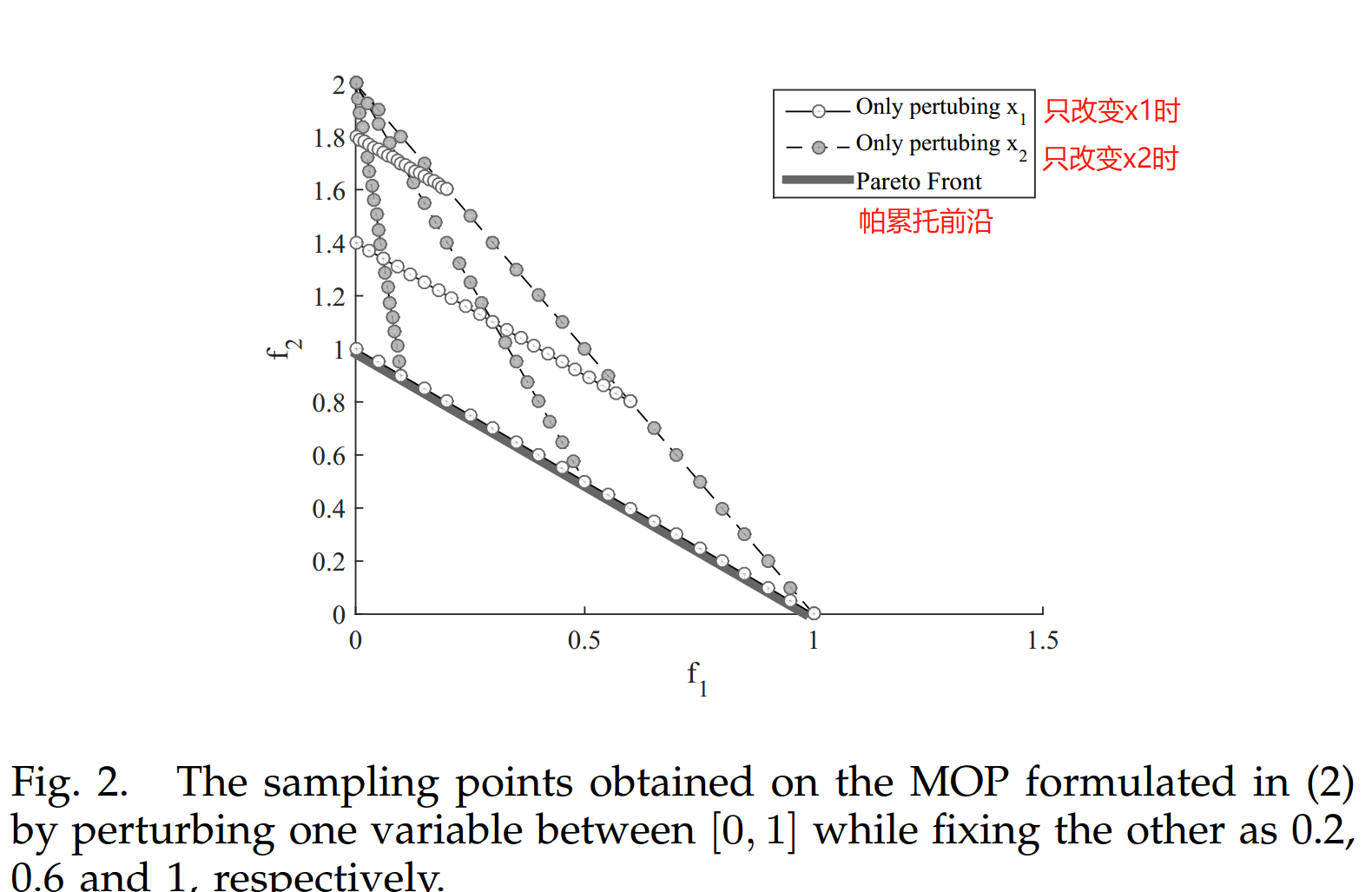
图2. 在公式(2)中构建的多目标优化问题上获得的采样点,这些点是通过在[0; 1]范围内扰动一个变量,同时将另一个变量固定为0.2、0.6和1来得到的。

然而,在这种情况下,由于只改变x2时的线段与帕累托前沿产生的交集较少,将 x2 标记为与收敛相关的变量更有利,因为优化 x2 将引导总体趋向帕累托前沿。
本文算法LMEA 的主要框架是什么(两个部分)
决策变量聚类方法

- 行 1: 使用
N初始化种群P。 - 行 2: 通过调用
VariableClustering函数,并传递种群P、nSel和nP er作为参数,对决策变量进行聚类。返回决策变量(DV)和聚类变量(CV)。 - 行 3: 通过调用
InteractionAnalysis函数,并传递种群P、聚类变量CV和nCor作为参数,进行决策变量交互分析。返回子聚类变量subCV s。 - 行 5: 在循环内,通过调用
ConvergenceOptimization函数,并传递种群P和子聚类变量subCV s作为参数,进行收敛优化。更新种群P。 - 行 6: 在循环内,通过调用
DiversityOptimization函数,并传递种群P和决策变量DV作为参数,进行多样性优化。更新种群P
InteractionAnalysis函数

以下是对Algorithm 2: InteractionAnalysis的解读:
- 行 1: 初始化一个空的子组集合
subCVs。 - 行 2-20: 对于
CV中的每一个收敛相关变量v,执行以下操作:- 行 3: 初始化一个空的
CorSet。 - 行 4-14: 对于
subCVs中的每一个组Group,执行以下操作: - 行 5-14: 对于
Group中的每一个变量u,执行以下操作: - 行 6: 设置一个标志变量
flag为false。 - 行 7-14: 从1到
nCor进行循环,执行以下操作: - 行 8: 从
P中随机选择一个解p。 - 行 9-14: 如果在解
p中,v与u有交互,执行以下操作:- 行 10: 将标志变量
flag设置为true。 - 行 11: 将
Group添加到CorSet中。 - 行 12: 跳出当前循环。
- 行 10: 将标志变量
- 行 13-14: 如果
flag为true,跳出当前循环。 - 行 15-20: 如果
CorSet为空,执行以下操作: - 行 16: 将
v作为一个新的子组添加到subCVs中。 - 行 17-20: 否则,执行以下操作:
- 行 18: 将
subCVs设置为CorSet。 - 行 19: 将
CorSet中的所有变量和v设置为Group。 - 行 20: 将
Group添加到subCVs中。
- 行 3: 初始化一个空的

具体来说,如果一个变量至少与subCVs中的一个现有变量有交互,那么这两个变量会被分配到同一个子组;否则,它会被分配到一个新的子组。
利用变量分析法,将相互交互的决策变量分到一个子组中,而各组之间保持变量不交互的状态方便独立优化


(a) 显示了这种聚类分类的方法,不同颜色线表示改变调查的不同的变量,相同颜色的条数表示从种群中采样的个体数目,例如,白色的线条有两条就是x2的采样个数是两个个体,而同一条线上点的个数表示对个体上这个变量采取的扰动的数量,例如这里对于单个个体的研究变量的扰动数目为8,所以一条线上的点的个数为8,同时,其他没有考虑的变量此时保持不变。

(b)显示了聚类的标准,就是当考虑同一个变量的改变时,两个解构成的线分别与收敛方向构成的夹角,夹角较大表明变量与多样更相关,而夹角越小表明变量与收敛更相关。
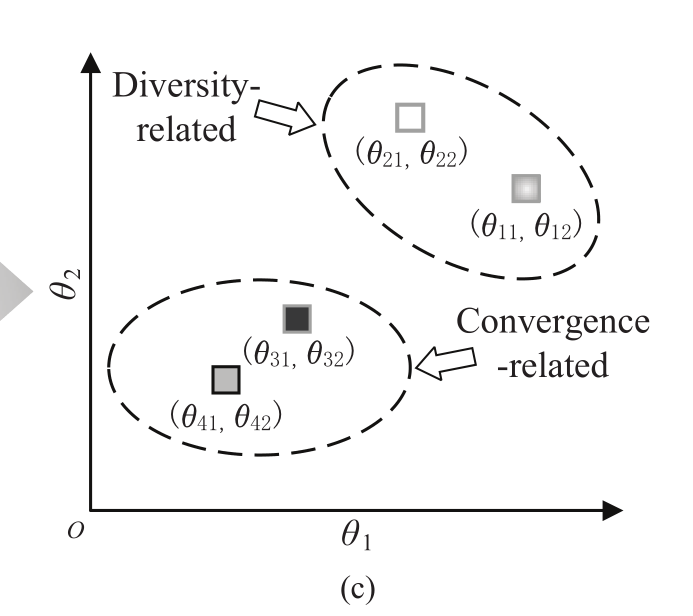
(c)显示了聚类的操作方法,由于考虑的变量的采样解的个数为二,因此构成的是一个二维的坐标系,通过这个坐标系上点的分布而通过K-means将变量分为两个簇、对于考虑多个采样,角度都比较大的变量划归为多样性相关的变量,而对于考虑多个采样,角度都比较小的变量划归为收敛性相关的变量。这种方式而言,单个变量采样的数量越多,坐标系的维度越大,聚类的效果越好!
基于树的快速非支配排序方法


T-ENS的主要理念是使用一棵树来表示每个非支配前沿中的解决方案,其中决定解决方案之间非支配关系的目标信息通过解决方案在树中的节点位置进行记录。因此,许多解决方案之间的非支配关系可以从已经被分配到前沿(存储在树中)的那些解决方案中推断出来,从而大大减少了同一前沿中的解决方案之间的比较次数。这导致T-ENS在计算效率上相较于ENS有了显著提升,特别是在解决多目标优化问题(MaOPs)时。算法6、7和8以伪代码的形式详细呈现了T-ENS的步骤。
- 算法6主要负责形成非支配解的集合,即非支配前沿。它通过不断地构建和更新树,来找到解决方案中的非支配关系。这个过程中,每个解都会根据其目标值被分配到相应的树中,从而构建出一系列的非支配前沿。
- 算法7则是被算法6调用的一个辅助函数,负责在给定的树中检查一个解是否能够成为树中的一个节点。如果该解在树中通过了检查(即,它不被树中的任何其他节点所支配),那么它就会被添加到树中,并从当前种群中移除。

- 算法8是一个递归算法,用于检查一个解决方案p是否被一个树形结构的解决方案集所支配。这个算法是多目标优化算法中,用于构造Pareto前沿的一个关键组成部分。Pareto前沿包含了所有非支配解决方案的集合,这些解决方案在所有目标上都不比其他任何解决方案差。该算法通过高效地检查非支配关系,大大提高了生成Pareto前沿的效率。
T-ENS
具体来说,如同在ENS中所做的,T-ENS首先按照首个目标的升序对种群中的解决方案进行排序,这适用于M目标最小化问题,其中M ≥ 2。我们假设排序后的种群由以下N个解决方案组成:p1(f1, f2, ..., fM)、p2(f1, f2, ..., fM)、...、pN(f1, f2, ..., fM),其中fij是第i个解决方案的第j个目标值,满足1 ≤ j ≤ M且1 ≤ i ≤ N。然后,T-ENS开始为每个非支配前沿构建一棵树。T-ENS将第一个解决方案p1作为第一个非支配前沿F1的树的根,种群中属于F1的所有其他解决方案将作为p1的后代进行存储。解决方案pi(2 ≤ i ≤ N)在树中的位置由满足f[i][objSeq[1][j]] < f[1][objSeq[1][j]]的最小j(j > 1)来确定,其中objSeq[1][j]是为解决方案p1随机生成的从2到M的序列的第j个元素。更准确地说,满足上述条件的解决方案pi将以第j个目标值objSeq[1][j]作为根的第j个子节点进行存储。如果有多于一个的解决方案满足上述条件,下一个解决方案将作为pi的子节点,即p1的孙节点进行存储。这个过程一直重复,直到检查完种群中的所有解决方案。在为第一个非支配前沿F1的树构建完成后,T-ENS开始为第二个前沿F2构建树,直到种群中的所有解决方案都被分配到一棵树中。
上述的树已经为前沿中的解决方案建立了代表性。假设有一个解决方案p需要被分配到前沿中,且在树中存在一个解决方案q,p与q之间呈现非支配关系,且在第objSeq[q][j]个目标上,p的值小于q(由于q在排序后的种群中的排名优于p,所以在第一个目标上,p的值大于q)。那么,p与储存在节点q的第k个子节点(k > j)以及该子节点的所有后代之间的非支配关系,可以从q和p之间的非支配关系中推断出来。因为对于这些解决方案s,我们有f[objSeq[q][j]]<f[objSeq[q][j]]<f[objSeq[q][j]],其中j∈{1; 2; : : : ; M − 1}。因此,在确定p的前沿时,无需将p与这些解决方案进行比较,这使得T-ENS在处理多目标优化问题(MaOPs)时效率极高。
T-ENS(Truncated Efficient Non-dominated Sort)算法的运行过程可以概括为以下几个步骤:
- 排序:首先,T-ENS按照首个目标的升序对种群中的解决方案进行排序。这适用于M目标最小化问题,其中M ≥ 2。排序后的种群由N个解决方案组成。
- 树构建:然后,T-ENS开始为每个非支配前沿(F1, F2,...)构建一棵树。将第一个解决方案p1作为第一个非支配前沿F1的树的根,种群中属于F1的所有其他解决方案将作为p1的后代进行存储。解决方案pi(2 ≤ i ≤ N)在树中的位置由满足某个条件的最小j(j > 1)来确定。如果有多个解决方案满足这个条件,下一个解决方案将作为pi的子节点,即p1的孙节点进行存储。这个过程一直重复,直到检查完种群中的所有解决方案。
- 树的使用:在为每个非支配前沿构建完树后,这些树为前沿中的解决方案提供了代表性。当一个解决方案p需要被分配到前沿中,并且在树中存在一个解决方案q(p与q之间存在非支配关系)时,可以从q和p之间的非支配关系推断出p与储存在节点q的第k个子节点(k > j)以及该子节点的所有后代之间的非支配关系。这样,在确定p的前沿时,无需将p与这些解决方案进行比较,大大提高了处理多目标优化问题(MaOPs)的效率。
总结来说,T-ENS的运行过程是:先对种群进行排序,然后为每个非支配前沿构建一棵树,最后利用这些树快速确定解决方案的非支配关系,提高处理多目标优化问题的效率。